Capítulo 43 Modelos de regressão
43.1 Modelos e regressão
43.1.1 O que é modelagem?
- Modelagem é o processo de usar dados para selecionar um modelo matemático explícito que represente o processo gerador dos dados.340
43.1.2 O que é regressão?
Regressão refere-se a uma equação matemática que permite que uma ou mais variável(is) de desfecho (dependentes) seja(m) prevista(s) a partir de uma ou mais variável(is) independente(s).334
Para estimar os efeitos imparciais de um fator de exposição primária sobre uma variável de desfecho, frequentemente constroem-se modelos estatísticos de regressão.236
A regressão implica em uma direção de efeito, mas não garante causalidade.334
43.1.3 Por que a escolha do modelo de regressão é complexa?
Há inúmeras combinações possíveis de variáveis, formas funcionais (lineares, quadráticas, transformações), interações e formas do desfecho, o que torna o espaço de possibilidades muito amplo.340
Todos os modelos são errados, mas alguns são úteis.374
43.1.4 O que diferencia modelos clássicos e modernos em predição?
- Modelos clássicos, como a regressão logística e as árvores de decisão, contrastam com os modelos modernos, como máquinas de vetor de suporte, redes neurais e random forests, principalmente pela maior flexibilidade e capacidade destes últimos de capturar não linearidades e interações.375
O pacote modelsummary376 fornece as funções modelsummary e modelplot para gerar tabelas e gráficos de coeficientes de regressão.
O pacote gtsummary225 fornece a função tbl_regression para construção da ‘Tabela 2’ com dados do modelo de regressão.
O pacote equatiomatic377 fornece a função extract_eq para extrair a equação dos modelos em formato LaTeX para visualização.
43.3 Estruturas de análise de regressão
43.3.1 O que são análises de regressão simples?
A análise de regressão simples consiste em modelos estatísticos com uma variável dependente (desfecho) e uma variável independente (preditor).378
A equação de regressão simples é expressa como (43.1), onde \(Y\) é a variável dependente, \(X\) é a variável independente, \(\beta_0\) é o intercepto (constante), \(\beta_1\) é o coeficiente de regressão da variável independente e \(\epsilon\) representa o erro aleatório do modelo.378
\[\begin{equation} \tag{43.1} Y = \beta_0 + \beta_1 X + \epsilon \end{equation}\]
43.3.2 O que são análises de regressão multivariável?
A análise multivariável (ou múltiplo) consiste em modelos estatísticos com uma variável dependente (desfecho) e duas ou mais variáveis independentes.378
A equação de regressão multivariável é expressa como (43.2), onde \(Y\) é a variável dependente, \(X_1, X_2, ..., X_n\) são as variáveis independentes, \(\beta_0\) é o intercepto (constante), \(\beta_1, \beta_2, ..., \beta_n\) são os coeficientes de regressão das variáveis independentes e \(\epsilon\) representa o erro aleatório do modelo.378
\[\begin{equation} \tag{43.2} Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + ... + \beta_n X_n + \epsilon \end{equation}\]
43.3.3 O que são análises de regressão multivariada?
A análise multivariada consiste em modelos estatísticos com duas ou mais variáveis dependente (desfechos) e duas ou mais variáveis independentes.378
Na regressão multivariada (43.3), \(Y_1, Y_2, ..., Y_m\) são as variáveis dependentes, \(X_1, X_2, ..., X_n\) são as variáveis independentes, \(\beta_{0j}\) é o intercepto de \(Y_j\), \(\beta_{ij}\) são os coeficientes de regressão de \(X_i\) para \(Y_j\), e \(\epsilon_j\) representa o erro aleatório associado a \(Y_j\).378
\[\begin{align} \tag{43.3} Y_1 &= \beta_{01} + \beta_{11} X_1 + \beta_{12} X_2 + \dots + \beta_{1n} X_n + \epsilon_1 \\ Y_2 &= \beta_{02} + \beta_{21} X_1 + \beta_{22} X_2 + \dots + \beta_{2n} X_n + \epsilon_2 \\ &\vdots \\ Y_m &= \beta_{0m} + \beta_{m1} X_1 + \beta_{m2} X_2 + \dots + \beta_{mn} X_n + \epsilon_m \end{align}\]
43.3.4 O que são análises de regressão segmentada?
A regressão segmentada é uma abordagem frequentemente utilizada para análise de séries temporais interrompidas, permitindo estimar alterações no nível e/ou na tendência do desfecho após a intervenção.379
Modelos de regressão segmentada podem ser implementados utilizando regressão linear, Poisson, logística ou modelos multinível, dependendo da natureza do desfecho e da estrutura dos dados.380
Diferentes modelos de impacto podem ser especificados, incluindo mudanças abruptas de nível, mudanças graduais de tendência, efeitos temporários ou efeitos com período de latência.379
Entre os modelos mais utilizados, destacam-se os modelos com mudança imediata de nível, mudança de tendência e mudança simultânea de nível e tendência.379
Modelo com mudança imediata de nível (43.4), utilizado quando se espera um efeito abrupto após a intervenção, sem alteração na tendência temporal.
\[\begin{equation} \tag{43.4} Y_t = \beta_0 + \beta_1 T + \beta_2 X_t \end{equation}\]
- Modelo com mudança de tendência (43.5), utilizado quando a intervenção altera gradualmente a inclinação da série temporal, sem mudança imediata no nível.
\[\begin{equation} \tag{43.5} Y_t = \beta_0 + \beta_1 T + \beta_3 TX_t \end{equation}\]
- Modelo com mudança simultânea de nível e tendência (43.6), considerado o modelo ITS mais completo e frequentemente utilizado, permitindo estimar alterações imediatas e graduais após a intervenção.379
\[\begin{equation} \tag{43.6} Y_t = \beta_0 + \beta_1 T + \beta_2 X_t + \beta_3 TX_t \end{equation}\]
A variável \(T\) representa o tempo transcorrido desde o início do estudo, sendo expressa na unidade correspondente à frequência das observações, como meses ou anos.379
A variável \(X_t\) representa uma variável indicadora (dummy) da intervenção, codificada como 0 no período pré-intervenção e 1 no período pós-intervenção.379
A variável \(Y_t\) representa o valor do desfecho observado no tempo \(t\).379 O coeficiente \(\beta_0\) representa o nível inicial do desfecho no tempo \(T = 0\).379
O coeficiente \(\beta_1\) representa a tendência temporal pré-intervenção, indicando a variação esperada do desfecho ao longo do tempo antes da implementação da intervenção.379
O coeficiente \(\beta_2\) representa a mudança imediata no nível do desfecho após a intervenção.379
O coeficiente \(\beta_3\) representa a mudança na inclinação da tendência temporal após a intervenção.379
O termo de interação \(TX_t\) representa a alteração da inclinação da tendência temporal após a intervenção.379
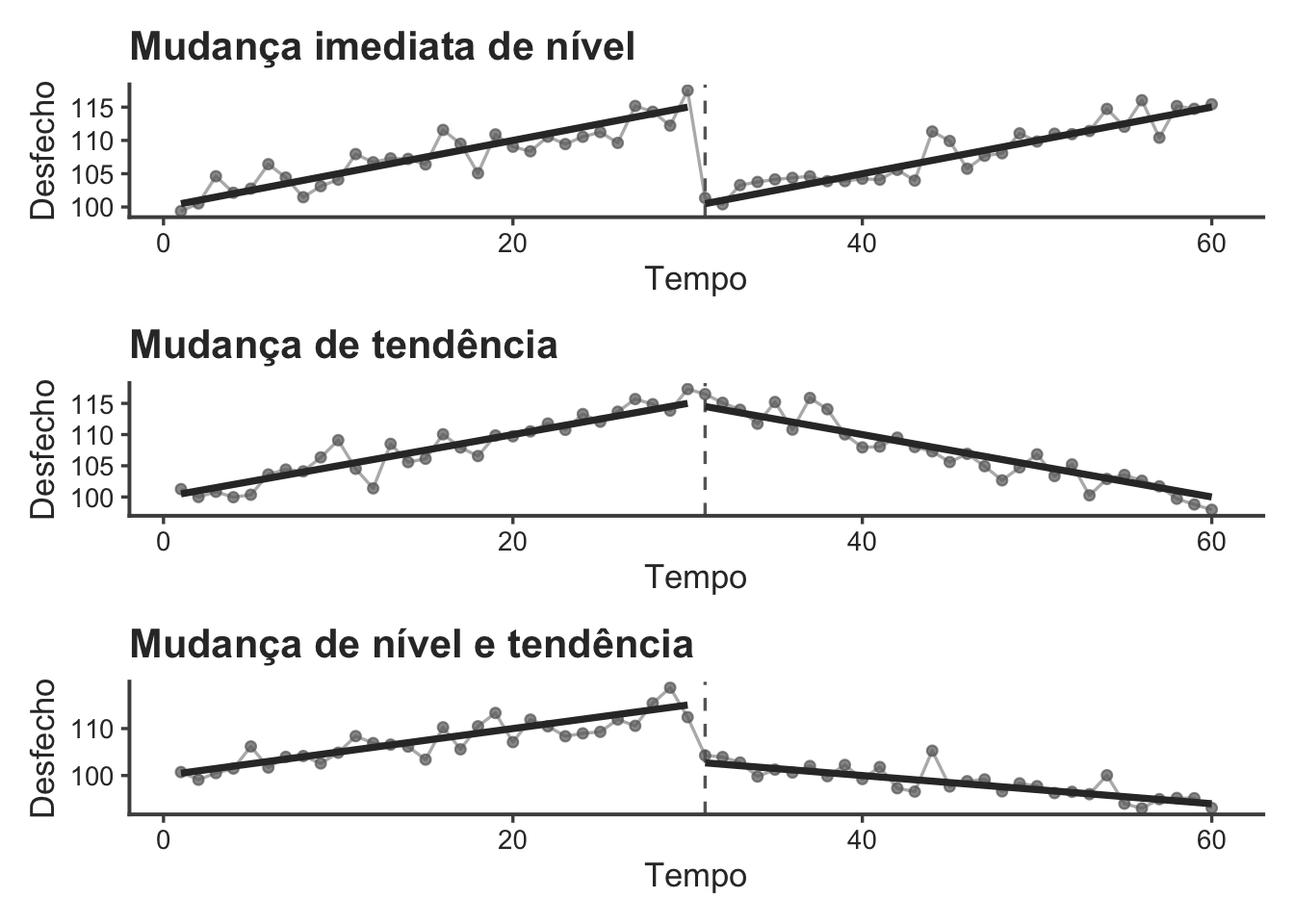
Figura 43.1: Modelos de regressão segmentada.
43.4 Tipos e famílias de regressão
43.4.1 O que são modelos de regressão linear?
- Modelos lineares (43.7) descrevem uma relação linear nos parâmetros entre um desfecho contínuo \(Y\) e um ou mais preditores \(X\).REF?
\[\begin{equation} \tag{43.7} Y = \beta_0 + \sum_{i=1}^{n} \beta_i X_i + \epsilon \end{equation}\]
Assumem erros independentes, de média zero e variância constante (homoscedasticidade).REF?
A normalidade dos resíduos é uma hipótese comum para inferência estatística, mas não obrigatória para estimação dos coeficientes.REF?
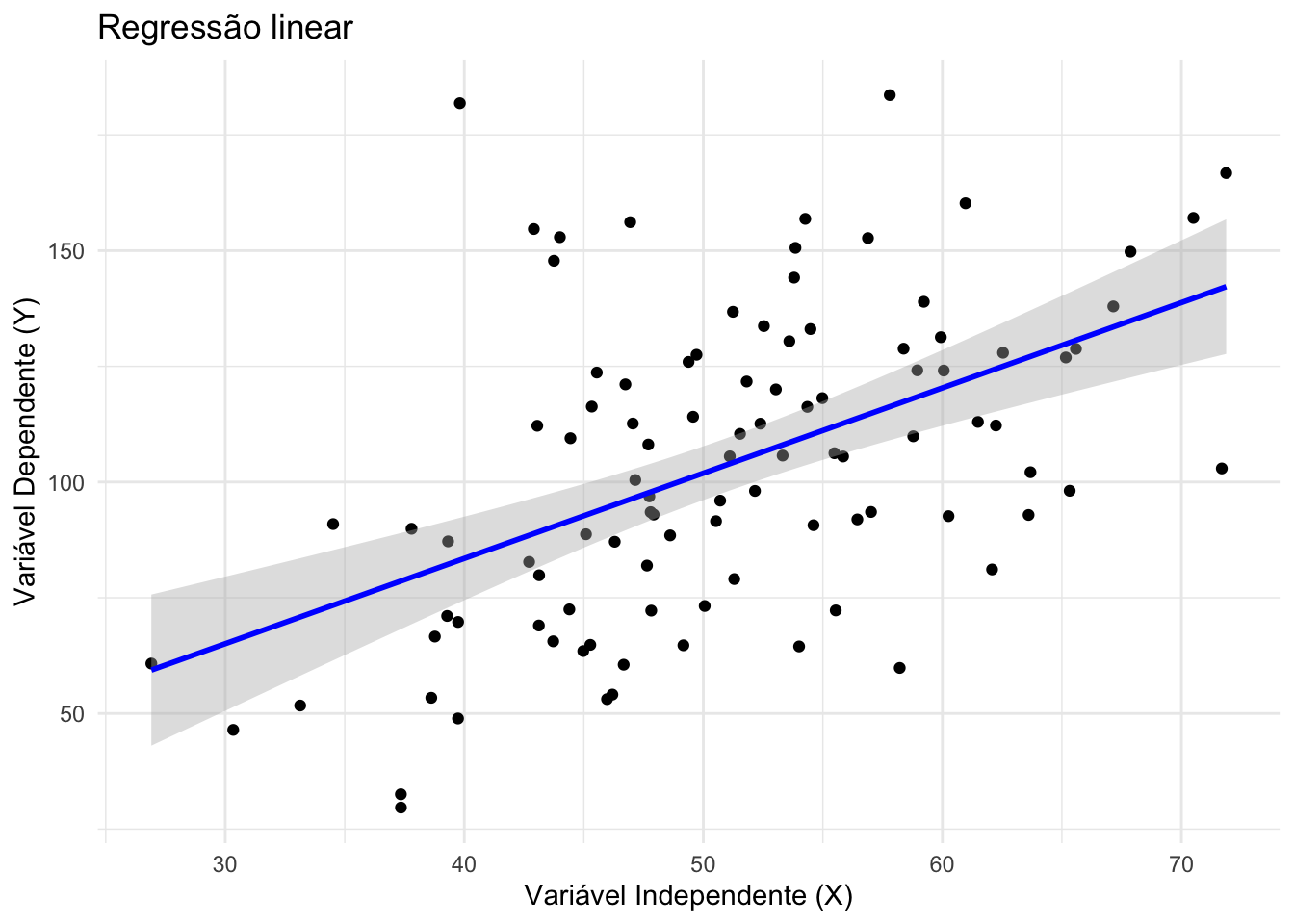
Figura 43.2: Regressão linear.
43.4.2 O que são modelos de regressão polinomial?
São extensões da regressão linear em que se incluem termos elevados a potências das variáveis independentes (ex.: \(X^2\), \(X^3\)), permitindo capturar relações curvas.REF?
Modelos de regressão polinomial continuam sendo lineares nos parâmetros, por isso ainda se enquadram como um caso particular da regressão linear.REF?
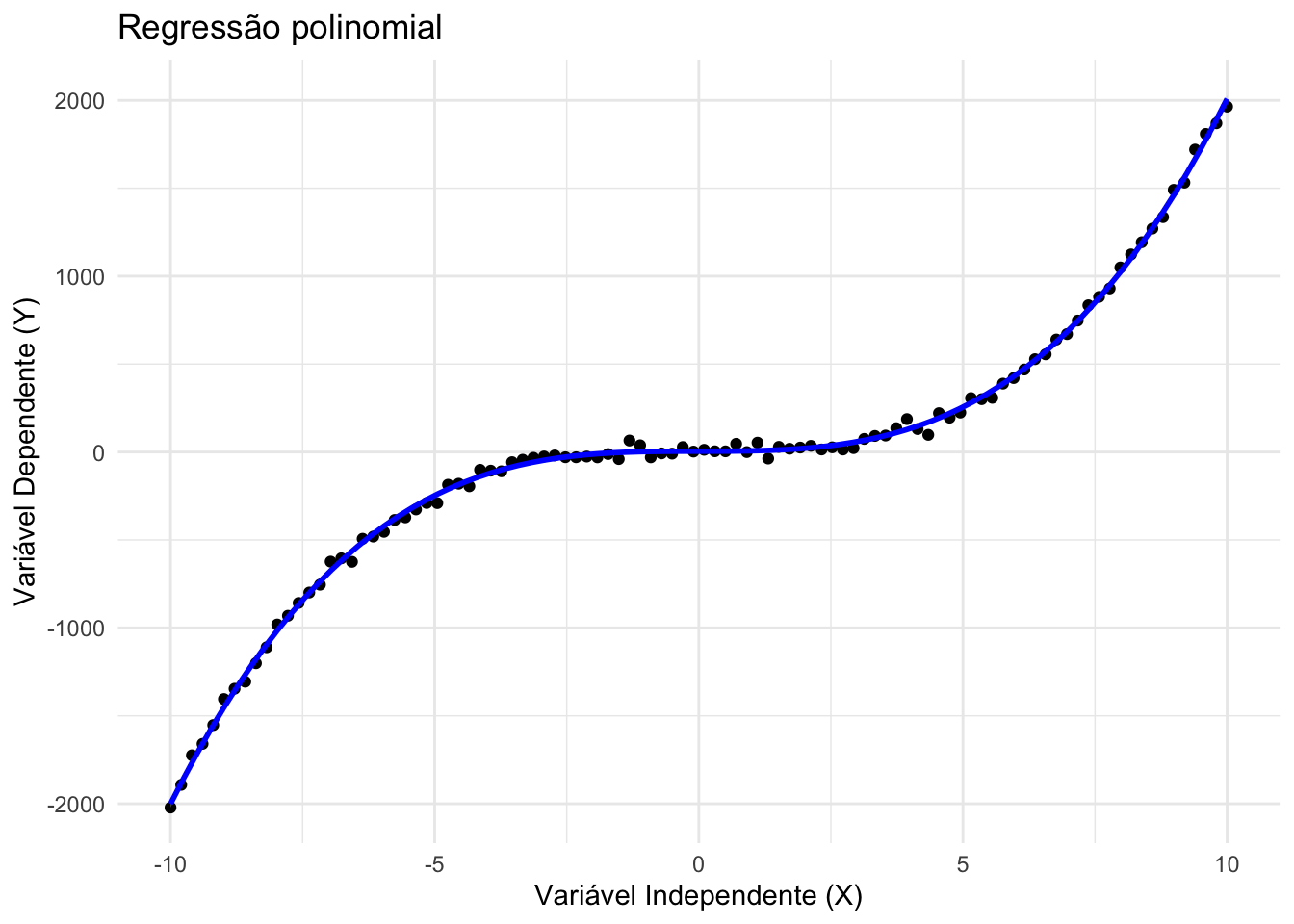
Figura 43.3: Regressão polinomial.
43.4.3 O que são modelos de regressão não-linear?
São modelos em que a relação entre os parâmetros e a variável resposta não é linear.
Podem assumir formas funcionais mais complexas (ex.: exponencial, logarítmica, logística).REF?
Importante diferenciar “não-linear na variável” (ex.: polinomial) de “não-linear no parâmetro” (ex.: modelos logísticos de crescimento).REF?
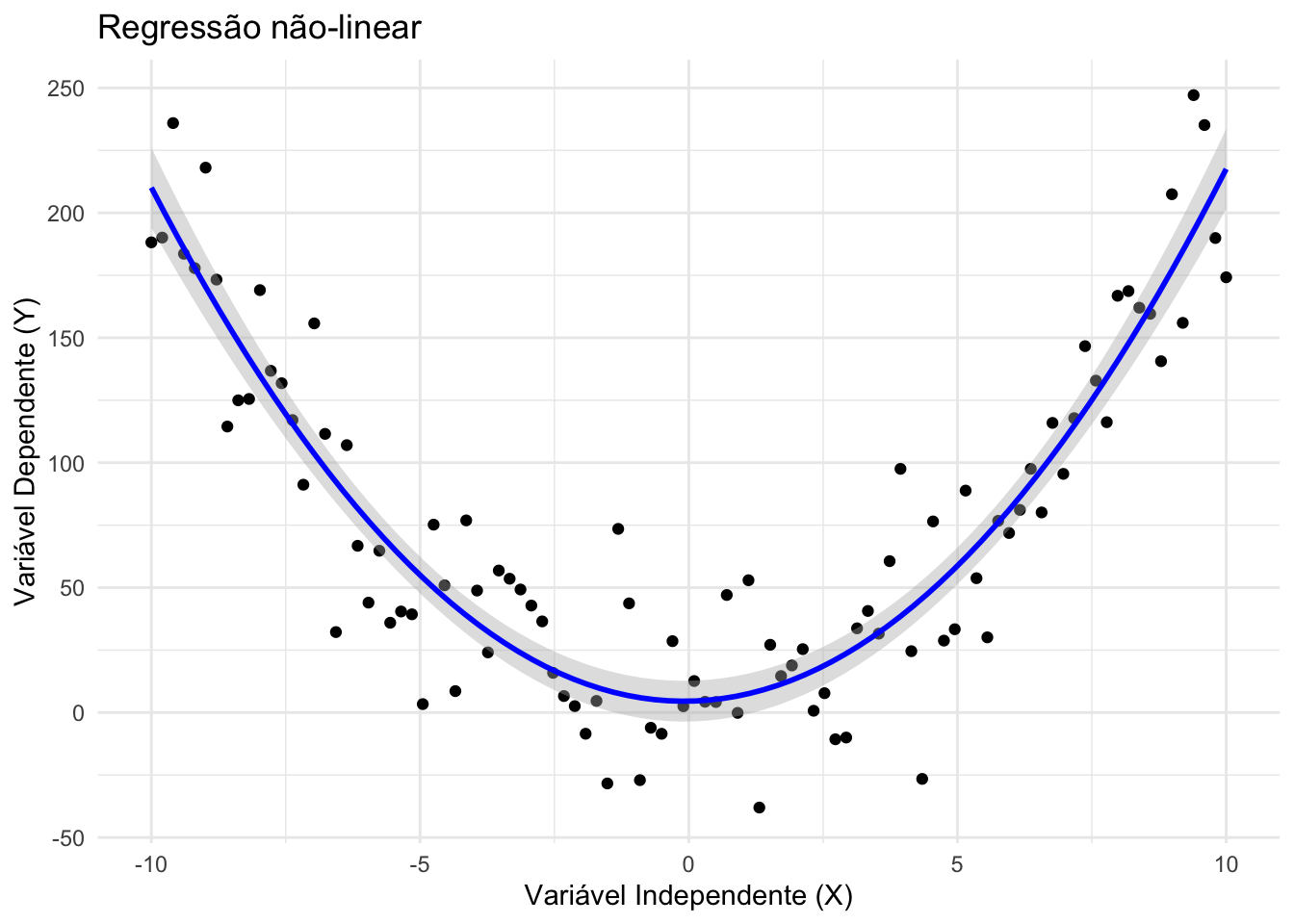
Figura 43.4: Regressão não-linear.
43.4.4 O que são modelos de regressão logística?
Modelos logísticos são casos de regressão linear generalizada em que a resposta \(Y\) é binária.381
A equação (43.8) modela a razão de chances (odds) em função dos preditores.381
\[\begin{equation} \tag{43.8} \log\left(\frac{p}{1-p}\right) = \beta_0 + \beta_1 X + ... + \beta_n X_n \end{equation}\]
\[\begin{equation} \tag{43.9} g(p) = \log\left(\frac{p}{1-p}\right) \end{equation}\]
A interpretação dos coeficientes \(\beta_i\) pode ser feita em termos de razões de chances (odds ratios, \(OR\)), por exponenciação dos coeficientes: \(OR_i = e^{\beta_i}\), o que representa o fator multiplicativo na \(OR\) do desfecho para cada aumento de uma unidade em \(X_i\) (mantendo os demais preditores constantes).381
A intepretação pode ser feita por estimativa da variação percentual na chance (\(OR\)) de ocorrência de \(Y\), calculando \((e^b - 1) \times 100\), de modo que um aumento de 1 unidade em \(X\) está associado a um aumento de \((e^b - 1) \times 100\%\) na chance de \(Y\) ocorrer (mantidos os demais preditores constantes).
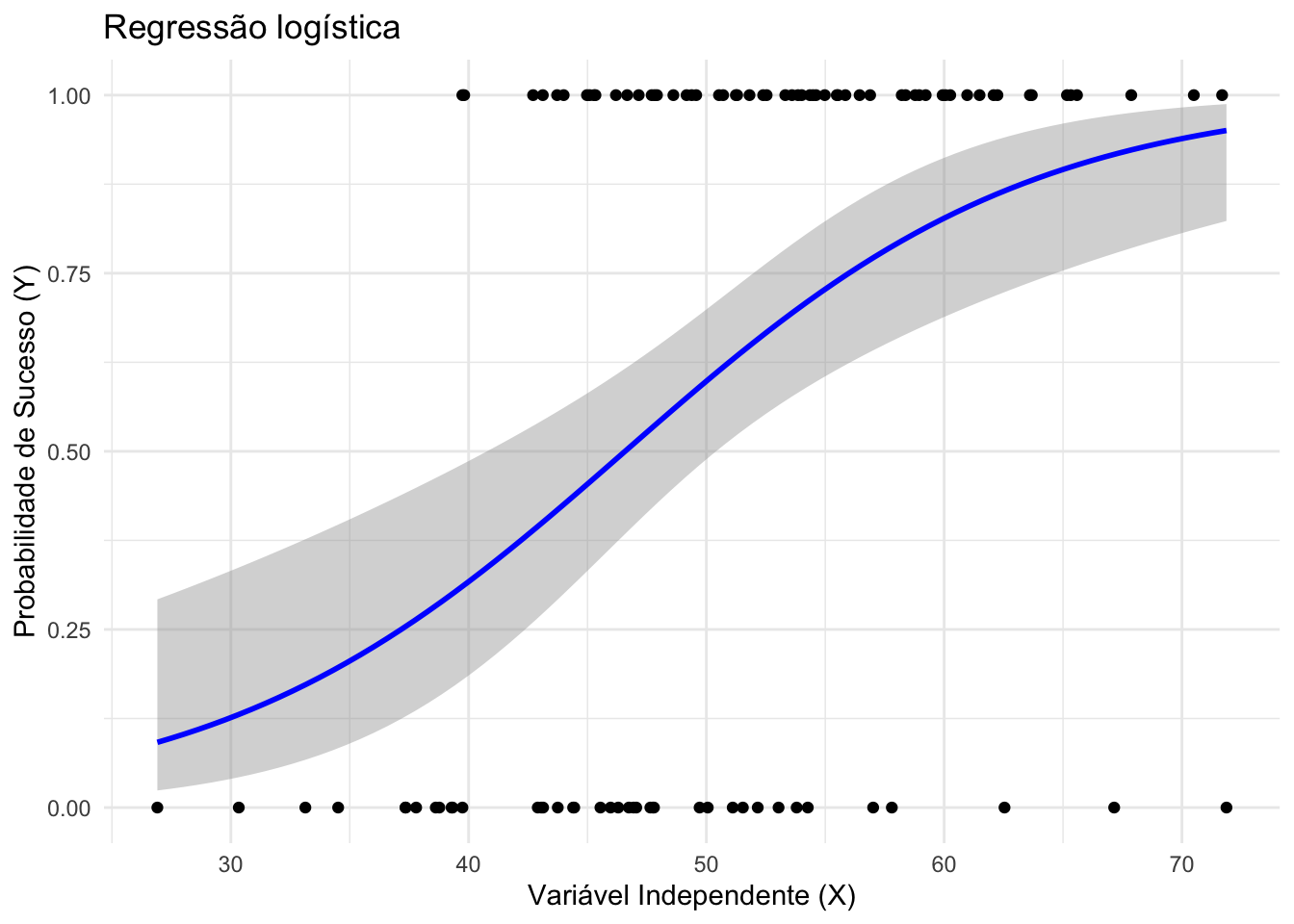
Figura 43.5: Regressão logística.
43.4.5 O que são modelos de regressão multinomial?
Modelos de regressão multinomial são usados quando a variável resposta é categórica com mais de dois níveis não ordenados.REF?
Estendem a regressão logística binária, modelando as razões de chances (odds ratios) de cada categoria em relação a uma categoria de referência.REF?
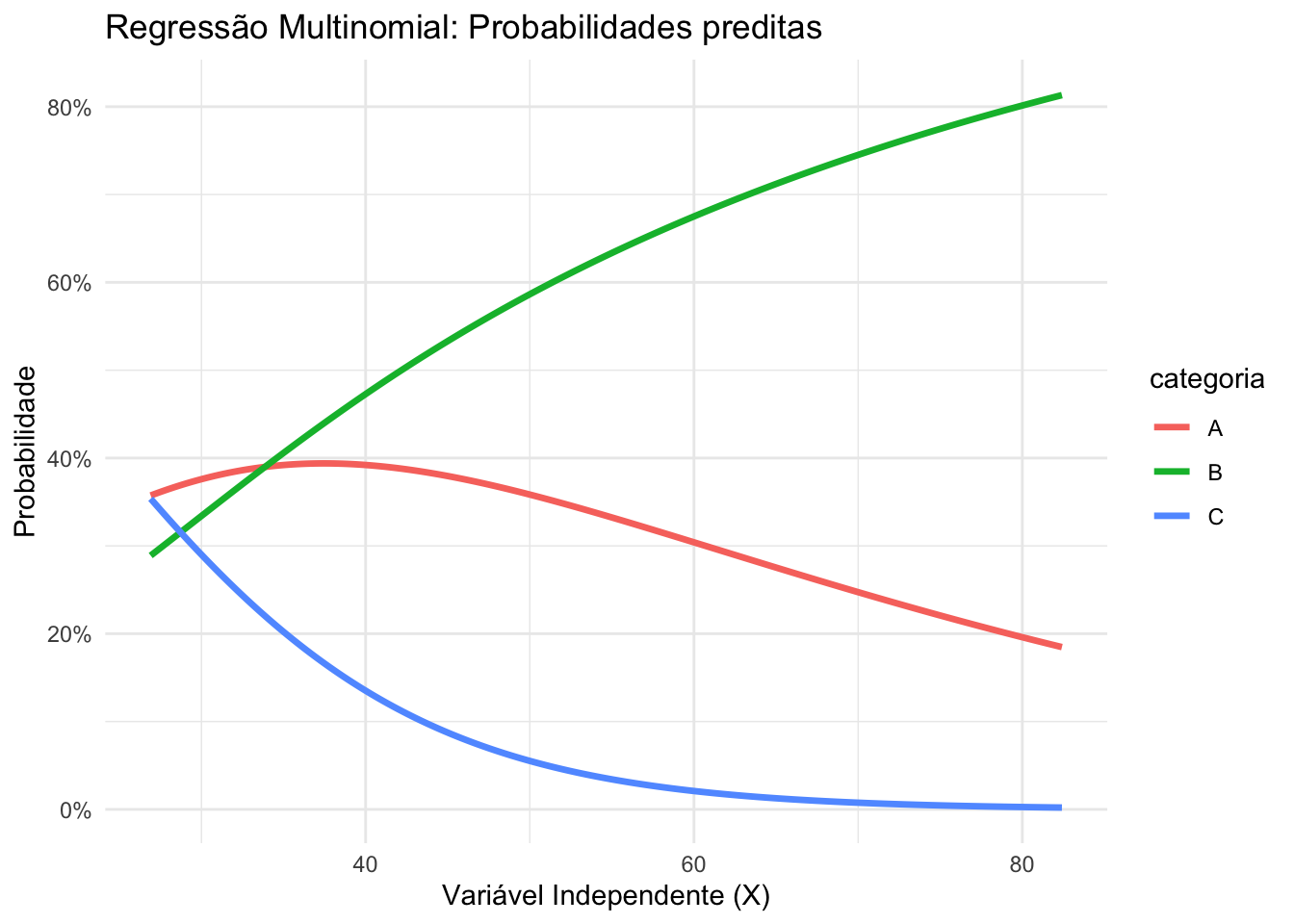
Figura 43.6: Regressão multinomial
43.4.6 O que são modelos de regressão ordinal?
Modelos de regressão ordinal são usados quando a variável resposta é categórica com mais de dois níveis ordenados.REF?
Modelam a probabilidade acumulada de estar em ou abaixo de cada categoria, usando uma função de ligação logit, probit ou log-log.REF?
Assumem a proporcionalidade dos coeficientes entre as categorias (proportional odds).REF?
43.4.7 O que são modelos de regressão de Poisson?
Modelos de regressão de Poisson são usados quando a variável resposta é uma contagem de eventos não negativos.REF?
Assumem que \(Y \sim Poisson(\mu)\), com \(\mu = E[Y|X]\) relacionado aos preditores via função de ligação log.REF?
A sobre-dispersão (variância maior que a média) pode exigir modelos alternativos como a regressão binomial negativa.REF?
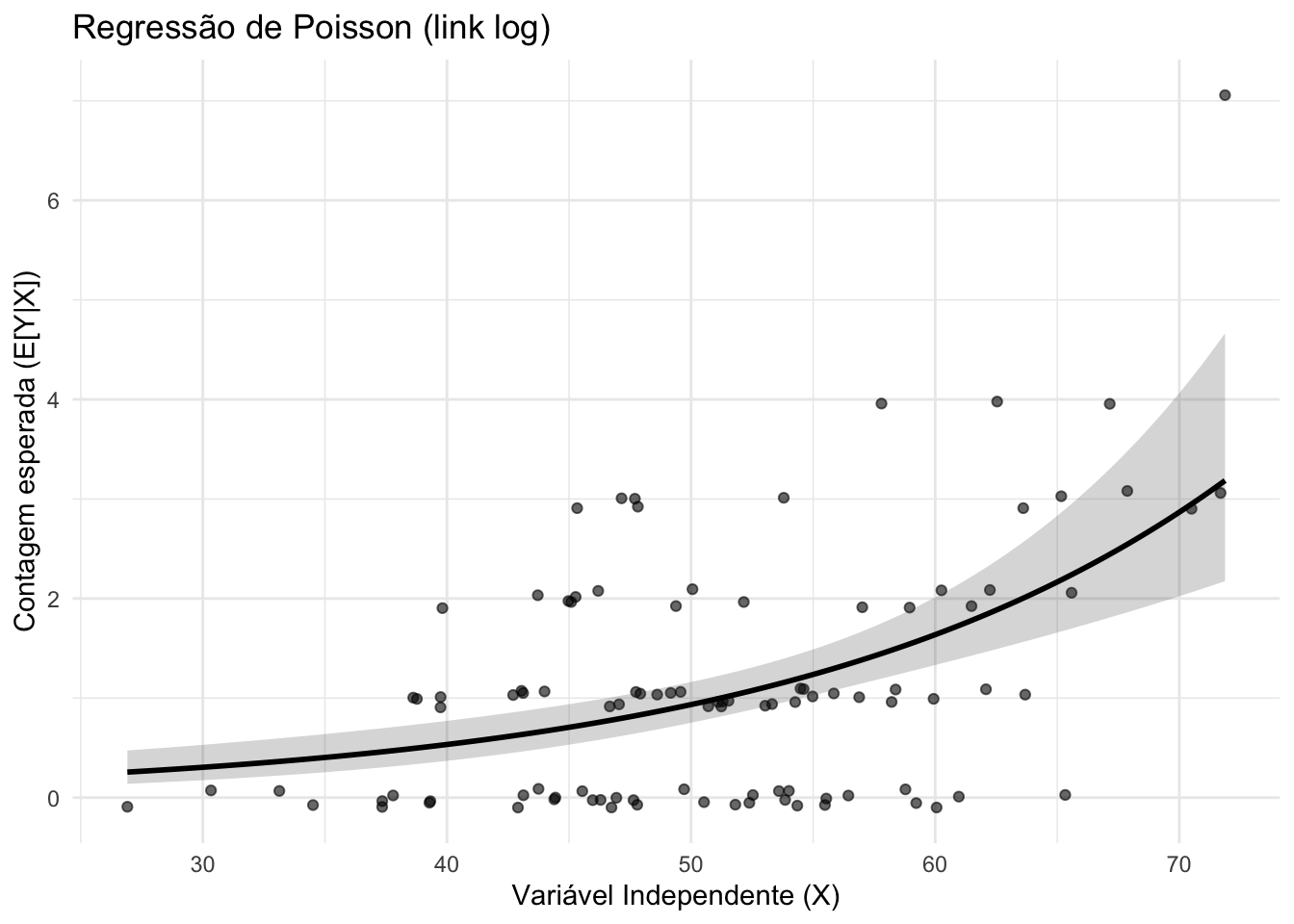
Figura 43.7: Regressão de Poisson.
43.4.8 O que são modelos de regressão binomial negativa?
Modelos de regressão binomial negativa são usados para contagens superdispersas, onde a variância excede a média.REF?
Introduzem um parâmetro de dispersão adicional para modelar a variabilidade extra.REF?
A função de ligação log é comumente usada, semelhante à regressão de Poisson.REF?
43.5 Quais são os principais métodos de estimação em regressão linear?
43.5.1 O que é a regressão por mínimos quadrados ordinários (OLS)?
- A regressão por mínimos quadrados ordinários (OLS) (43.10) estima os coeficientes \(\hat{\boldsymbol{\beta}}^{OLS}\) minimizando a soma dos quadrados dos resíduos, ou seja, a diferença entre os valores observados \(y_i\) e os valores preditos pelo modelo linear \(X\hat{\boldsymbol{\beta}}\).REF?
\[\begin{equation} \tag{43.10} \hat{\boldsymbol{\beta}}^{OLS} = \arg\min_{\boldsymbol{\beta}} \left\{ \sum_{i=1}^{n} \left( y_i-\beta_0-\sum_{j=1}^{p}x_{ij}\beta_j \right)^2 \right\} \end{equation}\]
43.5.2 Por que utilizar modelos de regressão regularizados?
A regressão por mínimos quadrados ordinários pode apresentar elevada variância quando há multicolinearidade, muitos preditores ou risco de overfitting.REF?
Modelos regularizados introduzem uma penalização sobre os coeficientes, aceitando um pequeno aumento no viés em troca de uma redução da variância e, frequentemente, de melhor capacidade de generalização.REF?
Os principais modelos regularizados são Ridge, Least Absolute Shrinkage and Selection Operator (LASSO) e elastic net.REF?
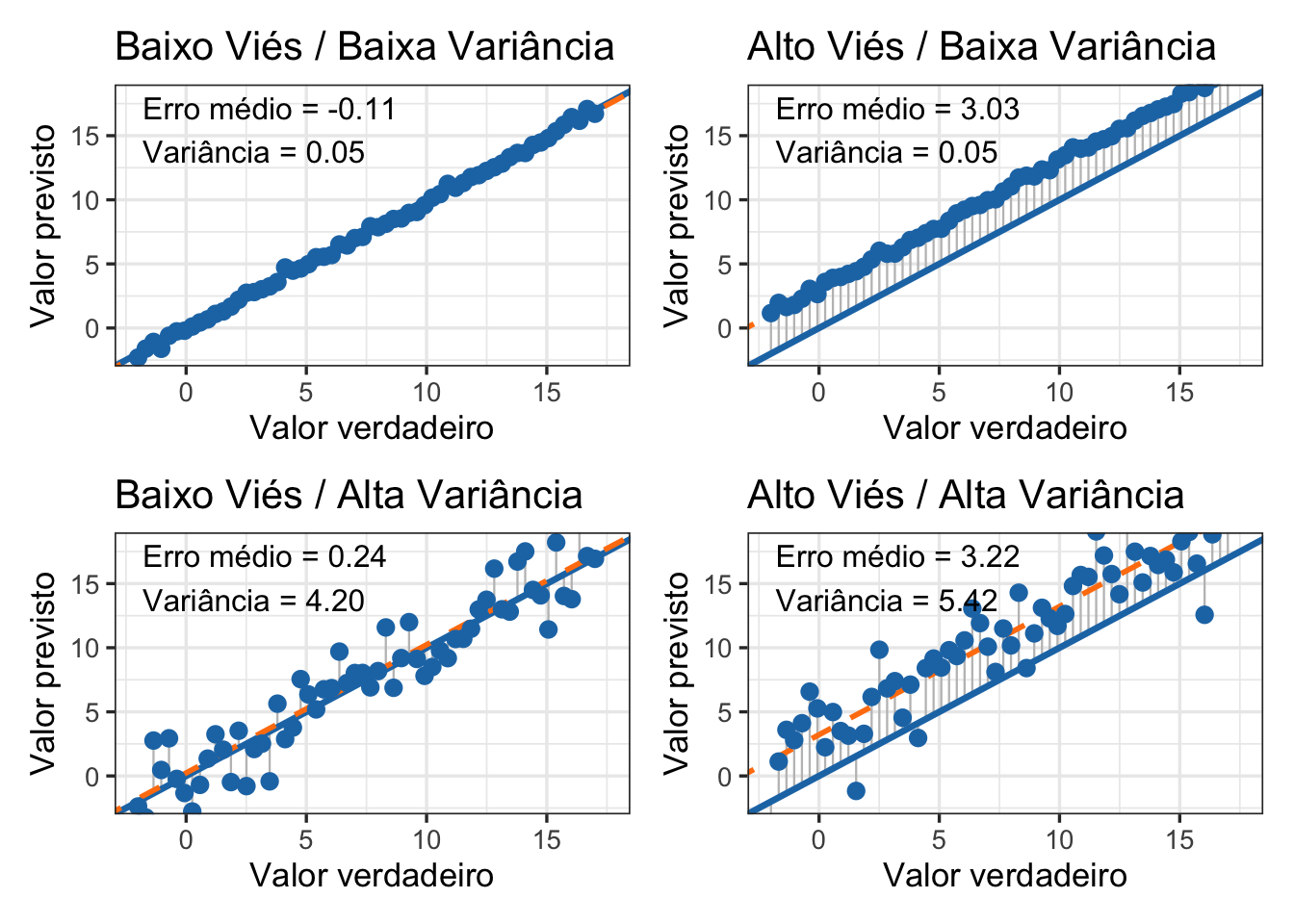
Figura 43.8: Trade-off entre viés e variância.
43.5.3 O que é a regressão Ridge?
- Regressão Ridge (43.11) é um modelo linear regularizado que adiciona uma penalização L2 à soma dos quadrados dos coeficientes.REF?
\[\begin{equation} \tag{43.11} \hat{\boldsymbol{\beta}}^{ridge} = \arg\min_{\boldsymbol{\beta}} \left\{ \sum_{i=1}^{n} \left( y_i-\beta_0-\sum_{j=1}^{p}x_{ij}\beta_j \right)^2 + \lambda \sum_{j=1}^{p}\beta_j^2 \right\} \end{equation}\]
Ajuda a reduzir multicolinearidade e overfitting, encolhendo os coeficientes em direção a zero, mas nunca os tornando exatamente nulos.REF?
O hiperparâmetro de regularização é \(\lambda\), controlando a intensidade da penalização. Valores maiores de \(\lambda\) resultam em maior encolhimento dos coeficientes.REF?
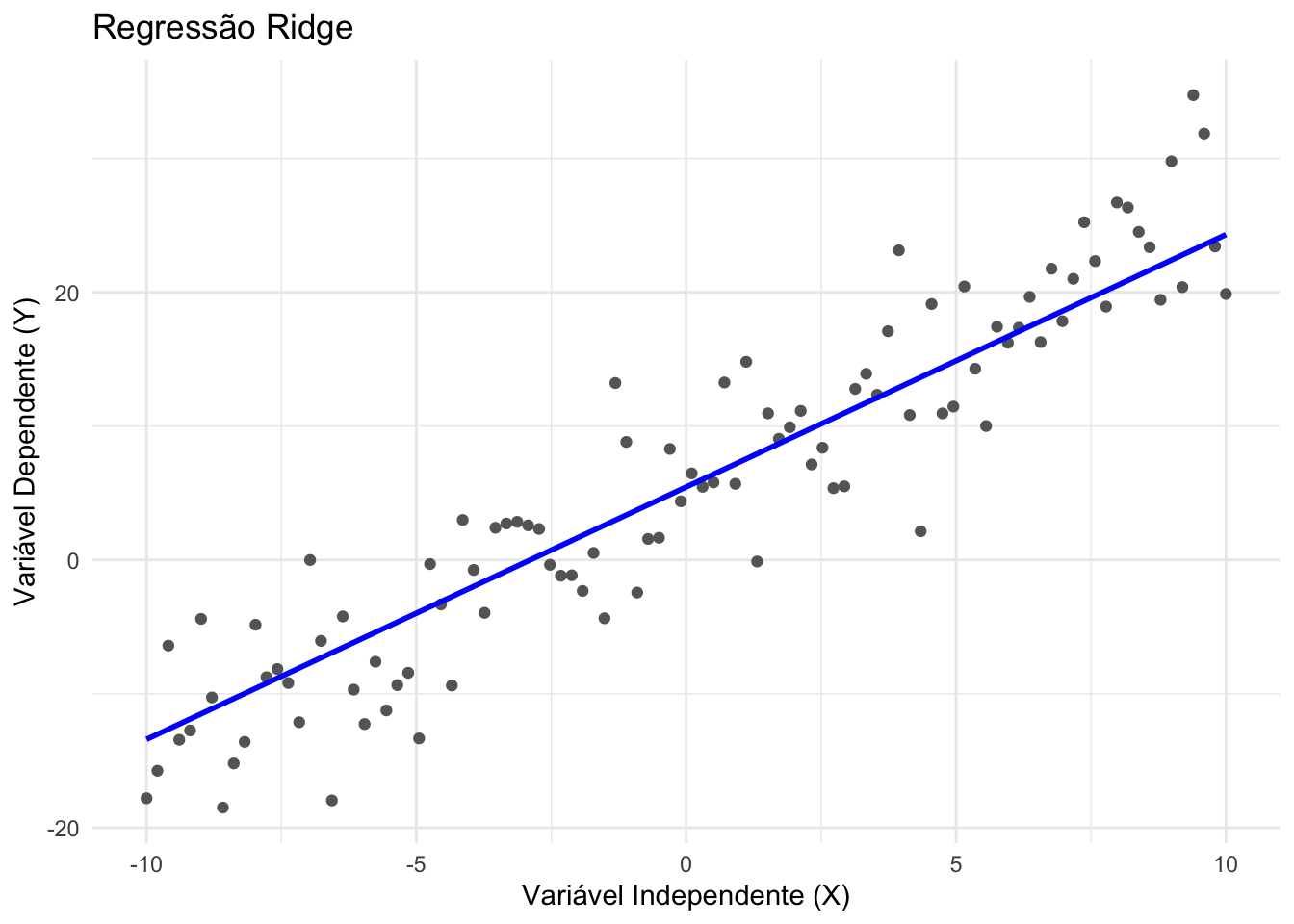
Figura 43.9: Regressão Ridge.
43.5.4 O que é a regressão LASSO?
- Regressão Least Absolute Shrinkage and Selection Operator (LASSO) (43.12) utiliza penalização L1, que pode zerar coeficientes.REF?
\[\begin{equation} \tag{43.12} \hat{\boldsymbol{\beta}}^{lasso} = \arg\min_{\boldsymbol{\beta}} \left\{ \sum_{i=1}^{n} \left( y_i-\beta_0-\sum_{j=1}^{p}x_{ij}\beta_j \right)^2 + \lambda \sum_{j=1}^{p} \left|\beta_j\right| \right\} \end{equation}\]
Além de reduzir overfitting, também realiza seleção automática de variáveis.REF?
Enquanto a regressão Ridge mantém todos os preditores, a LASSO pode excluir variáveis irrelevantes.REF?
43.5.5 O que é a regressão elastic net?
- Regressão elastic net (43.13) combina penalizações L1 (LASSO) e L2 (Ridge), controladas por um parâmetro \(\alpha\).REF?
\[\begin{equation} \tag{43.13} \hat{\boldsymbol{\beta}}^{enet} = \arg\min_{\boldsymbol{\beta}} \left\{ \sum_{i=1}^{n} \left( y_i-\beta_0-\sum_{j=1}^{p}x_{ij}\beta_j \right)^2 + \lambda \sum_{j=1}^{p} \left[ (1-\alpha)\beta_j^2 + \alpha\left|\beta_j\right| \right] \right\} \end{equation}\]
43.6 Efeitos de modelos de regressão
43.6.1 O que é efeito fixo?
Efeito fixo é a relação média entre variáveis assumida como igual para todos os grupos ou indivíduos, representando o comportamento populacional esperado.REF?
Ele descreve tendências sistemáticas e reproduzíveis que não dependem de pertencer a um grupo específico.REF?
Em modelos estatísticos, corresponde aos parâmetros estimados globalmente a partir de todos os dados.REF?
43.6.2 O que é efeito aleatório?
Efeito aleatório representa desvios específicos de grupos ou unidades em relação ao efeito fixo.REF?
Ele modela a variabilidade entre grupos, assumindo que esses desvios são amostras de uma distribuição comum.REF?
Não busca estimar cada grupo isoladamente, mas sim quantificar a variabilidade entre eles.REF?
43.6.3 O que é efeito misto?
Um modelo de efeitos mistos combina efeitos fixos e aleatórios em uma única estrutura estatística.REF?
Ele permite estimar tendências globais ao mesmo tempo em que ajusta variações específicas por grupo.REF?
Essa combinação possibilita inferência correta mesmo na presença de heterogeneidade, evitando armadilhas como o Paradoxo de Simpson.REF?
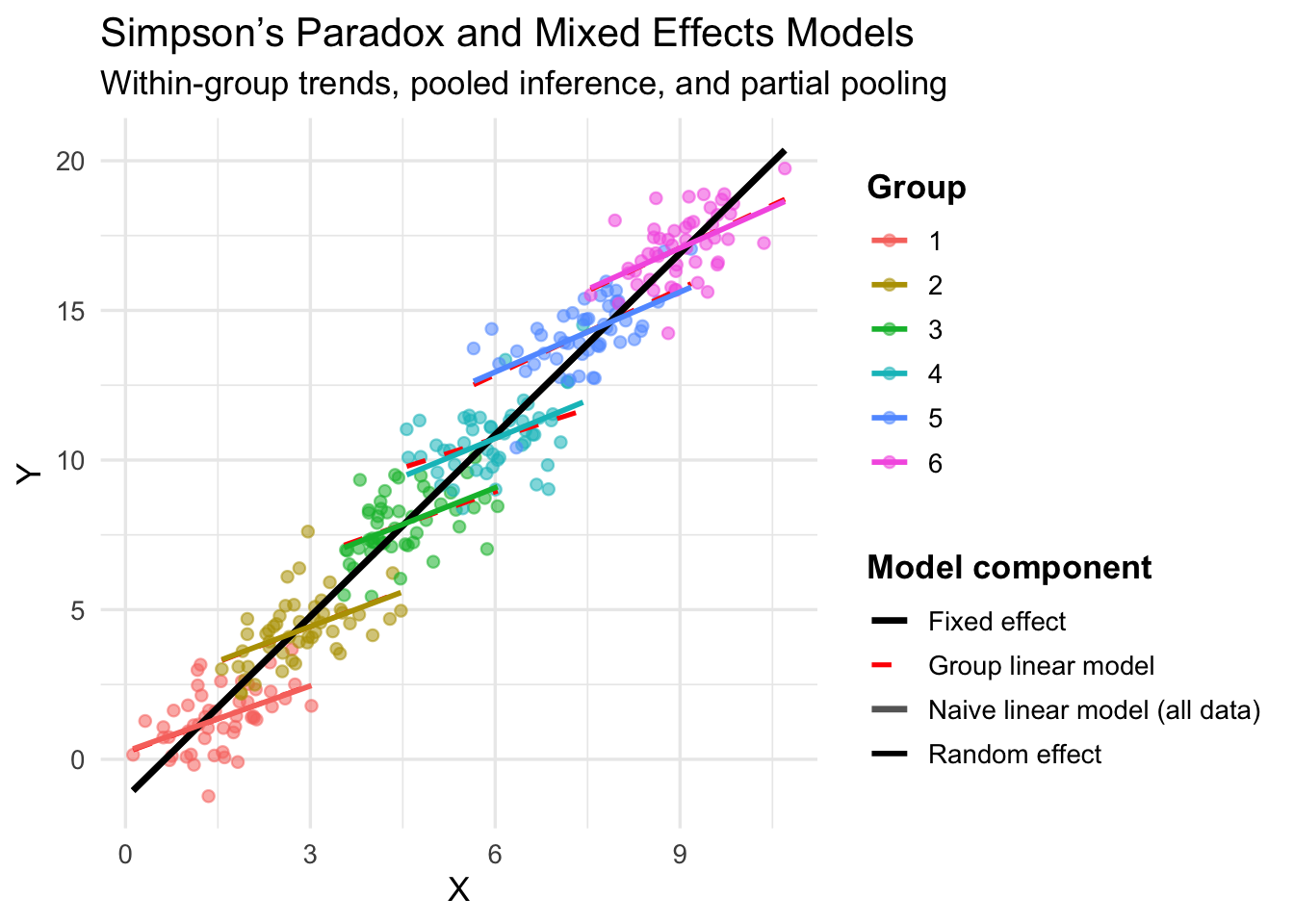
Figura 43.10: Efeitos fixos, aleatórios e mistos em dados simulados com paradoxo de Simpson. As linhas vermelhas representam os efeitos dentro dos grupos, enquanto as linhas cinza e preta representam os efeitos globais. O modelo misto (linhas coloridas) captura os efeitos dentro dos grupos.
43.6.5 O que é efeito de interação?
A interação (representada pelo símbolo *) é o termo estatístico empregado para representar a heterogeneidade de um determinado efeito.383
.382
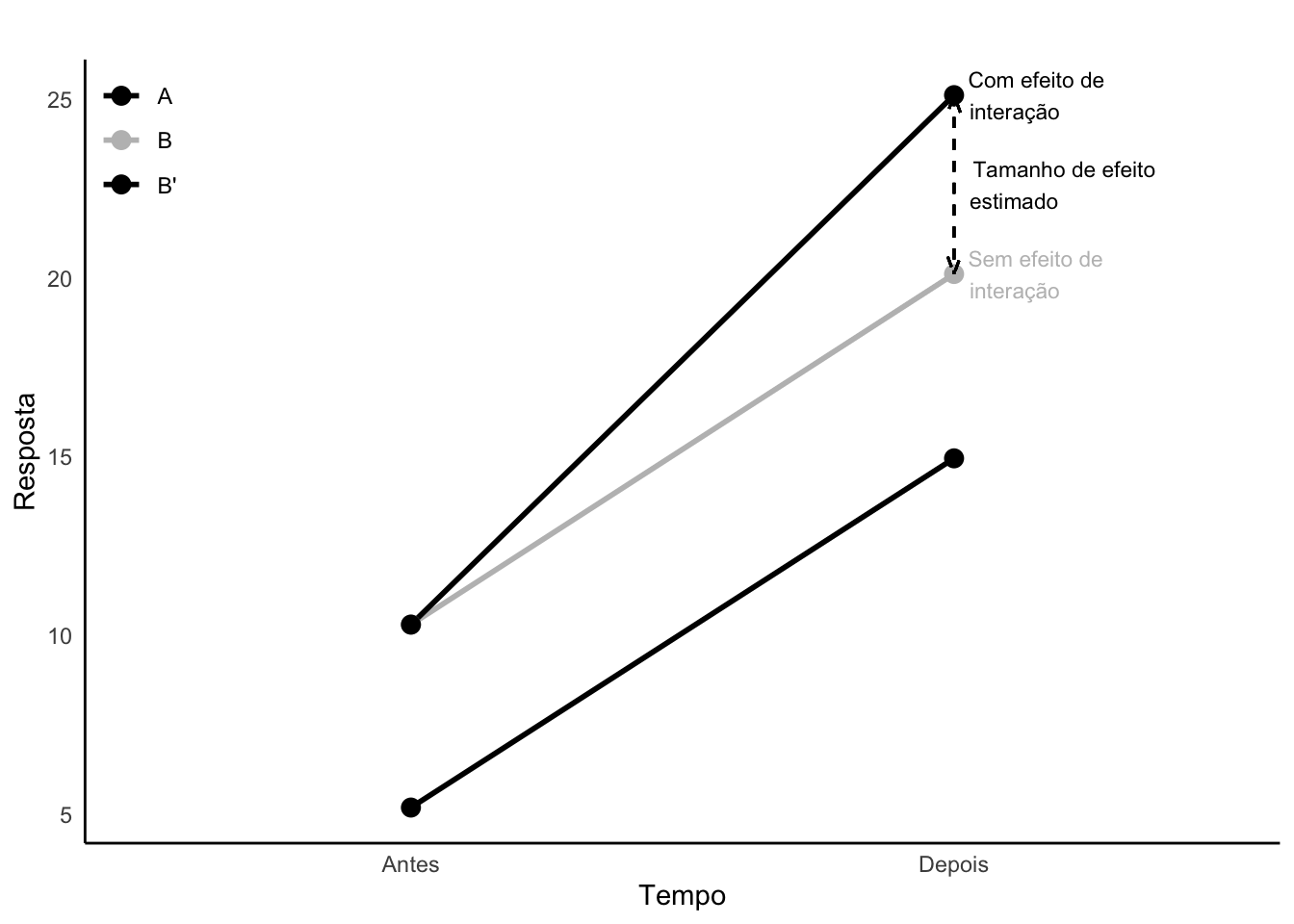
Figura 43.11: Análise de efeito de interação (direta) entre grupos e tempo. Retas paralelas sugerem ausência de efeito de interação.
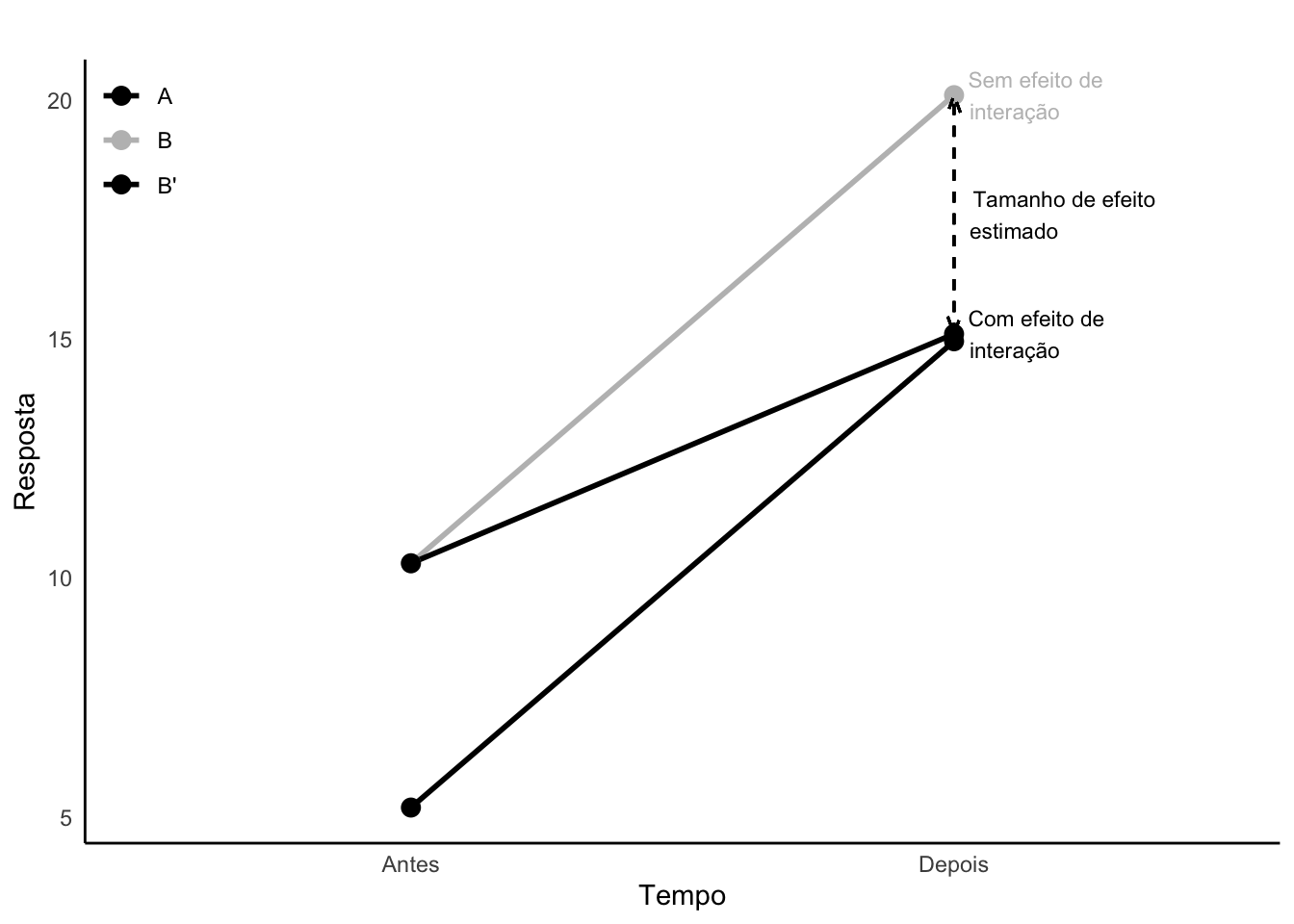
Figura 43.12: Análise de efeito de interação (inversa) entre grupos e tempo. Retas paralelas sugerem ausência de efeito de interação.
O pacote nlme384 fornece a função nlme para ajustar um modelo de regressão misto não linear.
O pacote mmrm385 fornece a função mmrm para ajuste de um modelo de regressão misto linear.
O pacote emmeans386 fornece a função emmeans para calcular as médias marginais dos fatores e suas combinações de um modelo de regressão misto linear.
43.7 Preparação de variáveis
43.7.1 Como preparar as variáveis categóricas para análise de regressão?
Variáveis fictícias (dummy) compreendem variáveis criadas para introduzir, nos modelos de regressão, informações contidas em outras variáveis que não podem ser medidas em escala numérica.388
Variáveis categóricas nominais, com 2 ou mais níveis, devem ser subdivididas em variáveis fictícias dicotômicas para ser usada em modelos de regressão.389
Cada nível da variável categórica nominal será convertido em uma nova variável fictícias dicotômica, tal que a nova variável dicotômica assume valor 1 para a presença do nível correspondente e 0 em qualquer outro caso.389
O pacote fastDummies390 fornece a função dummy_cols para preparar as variáveis categóricas fictícias para análise de regressão.
43.7.2 Por que é comum escolher a categoria mais frequente como referência em modelos epidemiológicos?
Maior estabilidade estatística: a categoria mais frequente costuma gerar estimativas mais estáveis, com menor erro padrão nos coeficientes das demais categorias.REF?
A escolha da referência não altera o ajuste nem o valor predito pelo modelo — apenas muda o ponto de comparação.REF?
43.8 Colinearidade
43.8.1 O que é colinearidade?
Colinearidade representa a correlação entre duas variáveis.391
Colinearidade exata indica uma relação linear perfeita entre duas variáveis.391
43.8.2 Como identificar colinearidade na matriz de correlação?
A colinearidade pode ser identificada na matriz de correlação por meio da análise dos coeficientes de correlação entre as variáveis.391
Valores de correlação próximos de \(1\) ou \(-1\) indicam colinearidade entre as variáveis.391
O pacote GGally392 fornece a função ggally_cor para estimar a correlação bivariada e exibir o coeficiente de correlação e o P-valor na matriz de correlação.392
43.9 Multicolinearidade
43.9.1 O que é multicolinearidade?
- Multicolinearidade representa a intercorrelação entre as variáveis independentes (explanatórias) de um modelo.391
43.9.2 Como diagnosticar multicolinearidade de forma quantitativa?
Verifique a existência de multicolinearidade entre as variáveis candidatas.393
O Coeficiente de determinação (\(R^2\)) é uma medida de quão bem as variáveis independentes explicam a variabilidade da variável dependente.391
Valores \(R^2\) próximos a 1 indicam que as variáveis independentes estão fortemente correlacionadas entre si, o que pode indicar multicolinearidade.391
O Fator de Inflação da Variância (variance inflation factor, VIF) é uma medida que quantifica o quanto a variância de um coeficiente de regressão é inflacionada devido à multicolinearidade.391
Valores de VIF maiores que 10 são frequentemente considerados indicativos de multicolinearidade significativa.391
O recíproco da VIF é chamado de Tolerância, que mede a proporção da variância de uma variável independente que não é explicada pelas outras variáveis independentes.391
Valores baixos de Tolerância (geralmente abaixo de 0.1) indicam multicolinearidade.391
O número de condições (Condition Number) é uma medida que avalia a estabilidade numérica de um modelo de regressão.391
Valores altos de número de condições (entre 10 de 30) indicam multicolinearidade, e valores maiores que 30 indicam forte multicolinearidade.391
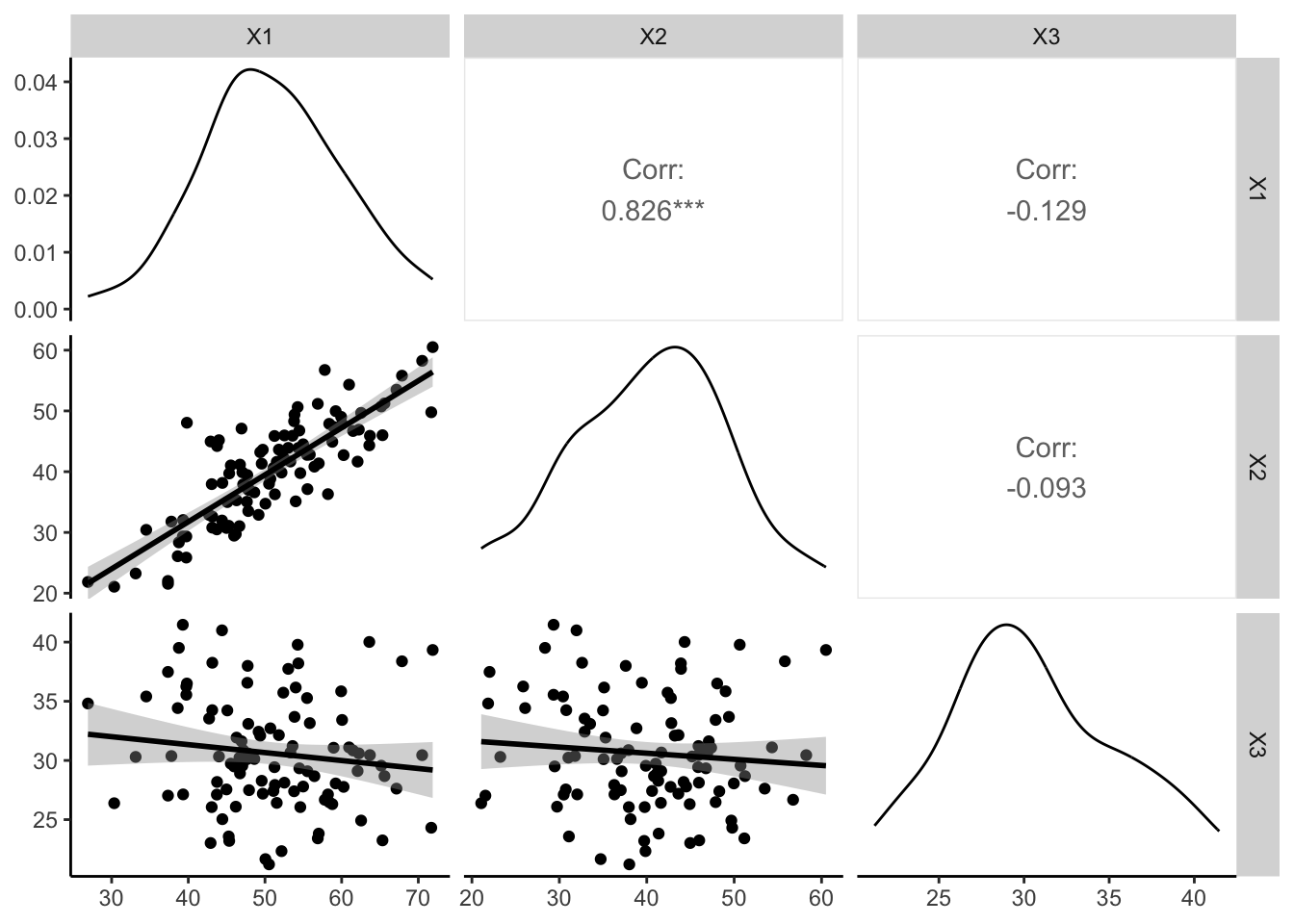
Figura 43.13: Multicolinearidade entre variáveis candidatas em modelos de regressão multivariável.
O pacote GGally392 fornece a função ggpairs para criar uma matriz gráfica de correlações bivariadas.
O pacote car394 fornece a função vif para calcular o fator de inflação da variância (VIF).
43.9.3 O que fazer em caso de multicolinearidade elevada?
Verifique a transformação (codificação) de variáveis numéricas em categóricas.391
Aumente o tamanho da amostra, se possível, para reduzir a multicolinearidade.391
Combine níveis de variáveis categóricas com baixa frequência de ocorrência.391
Combine variáveis numéricas altamente correlacionadas em uma única variável composta, como a média ou soma das variáveis.391
Considere a exclusão de variáveis altamente correlacionadas do modelo, especialmente se elas não forem essenciais para a análise.391
Use técnicas de seleção de variáveis, como seleção passo a passo, para identificar e remover variáveis redundantes.391
Use técnicas de regularização, como regressão Ridge ou LASSO, que podem lidar com multicolinearidade ao penalizar coeficientes de regressão.391
43.10 Redução de dimensionalidade
43.10.1 A correlação bivariada pode orientar a seleção de variáveis?
Seleção bivariada de variáveis consiste na aplicação de testes de correlação em pares de variáveis candidatas e variável de desfecho afim de selecionar quais serão incluídas no modelo multivariável.353,393,395
Seleção bivariada de variáveis é um dos erros mais comuns na literatura.353,393,395
A seleção bivariada de variáveis torna o modelo mais suscetível a otimismo no ajuste se as variáveis de confundimento não são adequadamente controladas.393,395
43.10.2 Variáveis sem significância estatística devem ser excluídas do modelo final?
Eliminar uma variável de um modelo significa anular o seu coeficiente de regressão (\(\beta = 0\)), mesmo que o valor estimado pelos dados seja outro.353
Desta forma, os resultados se afastam de uma solução de máxima verossimilhança (que tem fundamento teórico) e o modelo resultante é intencionalmente subótimo.353
Os coeficientes de regressão geralmente dependem do conjunto de variáveis do modelo e, portanto, podem mudam de valor (“mudança na estimativa” positiva ou negativa) se uma (ou mais) variável(is) for(em) eliminada(s) do modelo.353
43.10.3 Por que métodos de regressão gradual não são recomendados para seleção de variáveis?
Métodos diferentes de regressão gradual podem produzir diferentes seleções de variáveis de um mesmo banco de dados.389
Nenhum método de regressão gradual garante a seleção ótima de variáveis de um banco de dados.389
As regras de término da regressão baseadas em P-valor tendem a ser arbitrárias.389
43.10.4 O que pode ser feito para reduzir o número de variáveis candidatas?
Em caso de uma proporção baixa entre o número de participantes e de variáveis, use o conhecimento prévio da literatura para selecionar um pequeno conjunto de variáveis candidatas.393
Colapse categorias com contagem nula (células com valor igual a 0) de variáveis candidatas.393
Use simulações de dados para identificar qual(is) variável(is) está(ão) causando problemas de convergência do ajuste do modelo.393
A eliminação retroativa tem sido recomendada como a abordagem de regressão gradual mais confiável entre aquelas que podem ser facilmente alcançadas com programas de computador.353
43.10.5 Quando devemos forçar uma variável no modelo?
- Sempre que houver base teórica ou evidência prévia forte, ou se for a variável de exposição principal.340
43.11 Seleção de variáveis em regressão
43.11.1 O que é seleção de variáveis em regressão?
- Seleção de variáveis em regressão consiste em identificar, dentre um conjunto de preditores disponíveis, quais devem ser incluídos no modelo para otimizar o equilíbrio entre ajuste e parcimônia.396
43.11.2 Quais são os principais critérios de informação usados na seleção de variáveis?
Critérios de informação avaliam o ajuste do modelo penalizando a complexidade (número de preditores), ajudando a evitar overfitting.396
\(R^2_{adj}\) (43.14) penaliza o \(R^2\) pelo número de preditores, reduzindo o viés em modelos com muitas variáveis, onde \(n\) é o tamanho amostral, \(k\) o número de preditores, \(RSS\) a soma dos quadrados dos resíduos e \(SST\) a soma total dos quadrados.
\[\begin{equation} \tag{43.14} R^2_{adj} = 1 - \frac{(n-1)}{(n - k - 1)} \cdot \frac{RSS}{SST} \end{equation}\]
- \(AIC\) (Akaike Information Criterion) (43.15) mede o equilíbrio entre ajuste e complexidade:
\[\begin{equation} \tag{43.15} AIC = n \cdot \log\left(\frac{RSS}{n}\right) + 2k + n + n \cdot \log(2\pi) \end{equation}\]
- \(AICc\) (43.16) é uma versão corrigida do AIC, preferida para amostras pequenas:
\[\begin{equation} \tag{43.16} AIC_c = AIC + \frac{2(k+2)(k+3)}{n - (k + 2) - 1} \end{equation}\]
- \(C_p\) de Mallows compara o erro do modelo reduzido com o modelo completo, idealmente satisfazendo \(C_p \approx p\), onde \(m\) é o número total de preditores disponíveis, \(p\) o número de parâmetros (incluindo o intercepto), e \(RSS_{FULL}\) o erro quadrático residual do modelo completo:
\[\begin{equation} \tag{43.17} C_p = (n - m - 1)\frac{RSS}{RSS_{FULL}} - (n - 2p) \end{equation}\]
- \(BIC\) (Bayesian Information Criterion) (43.18) penaliza fortemente modelos complexos:
\[\begin{equation} \tag{43.18} BIC = n \cdot \log\left(\frac{RSS}{n}\right) + k \cdot \log(n) + n + n \cdot \log(2\pi) \end{equation}\]
43.11.3 Quais algoritmos podem ser usados para seleção automática?
Seleção progressiva: começa com o modelo nulo e adiciona, a cada iteração, a variável que mais melhora o critério escolhido. O processo para quando nenhuma nova variável melhora o modelo.396
Eliminação retrógrada: parte do modelo completo e remove, a cada iteração, a variável cuja exclusão mais melhora o critério. O processo para quando nenhuma remoção melhora o ajuste.396
Leaps-and-bounds: método exato que examina apenas uma fração dos \(2^m\) modelos possíveis, determinando os melhores subconjuntos para cada tamanho de preditor (usando os critérios AIC, BIC, AICc, R² ajustado e Cp).396
Esses métodos podem divergir em presença de alta multicolinearidade ou amostras pequenas, e devem ser acompanhados de diagnóstico de resíduos e validação cruzada.396
O pacote leaps397 fornece a função regsubsets para realizar os métodos de seleção de variáveis.
O pacote olsrr398 fornece a função ols_step_all_possible para testar todos os subconjuntos de potenciais preditores de uma regressão.
O pacote olsrr398 fornece a função ols_step_best_subset para selecionar o melhor de todos os subconjuntos de potenciais preditores de uma regressão, de acordo com critérios objetivos.
43.12 Desempenho e estabilidade de modelos
43.12.1 Como avaliar o desempenho dos modelos?
Pela área sob a curva ROC em conjunto com o otimismo (diferença entre AUC aparente e validada).375
O desempenho melhora com maior tamanho amostral, mas de forma desigual entre técnicas.375
43.12.2 Qual modelo alcança estabilidade mais rapidamente?
Regressão logística é o mais estável e menos data hungry.375
Árvore de decisão para classificação e regressão estabiliza rápido, mas em nível de desempenho baixo.375
Máquina de vetores de suporte, redes neurais e random forests apresentam instabilidade mesmo em amostras muito grandes.375
43.14 Avaliação de modelos
43.14.1 Como avaliar a qualidade de ajuste de um modelo?
- Coeficiente de determinação (\(R^2\)) (43.19) e \(R^2_{ajustado}\) (43.20): Medem a proporção da variabilidade dos dados explicada pelo modelo. O \(R^2\) ajustado penaliza a inclusão de variáveis irrelevantes.391
\[\begin{equation} \tag{43.19} R^2 = 1 - \frac{SS_{res}}{SS_{tot}} \end{equation}\]
\[\begin{equation} \tag{43.20} R^2_{ajustado} = 1 - (1 - R^2)\frac{n - 1}{n - p - 1} \end{equation}\]
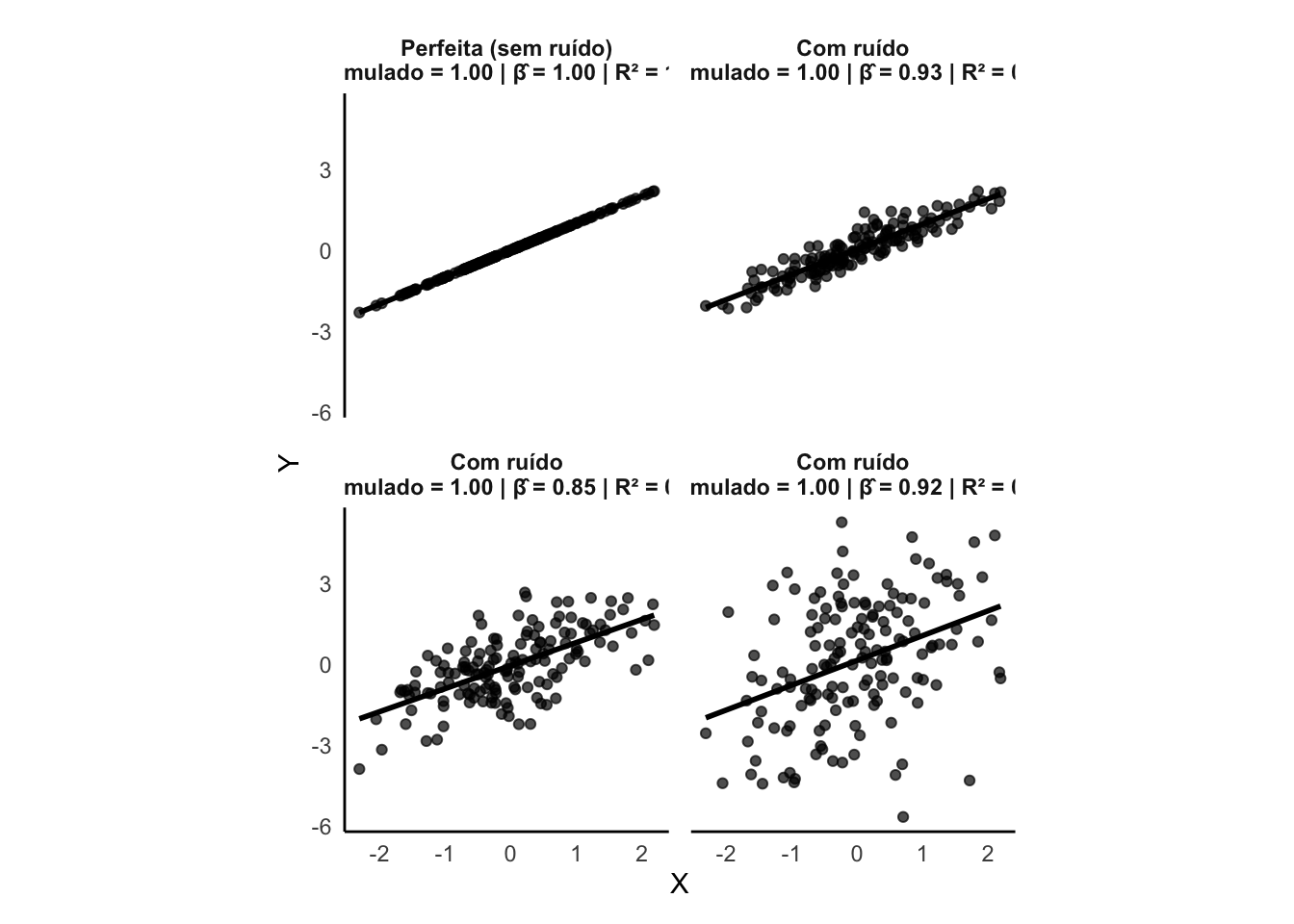
Figura 43.14: Exemplos de ajuste de modelos de regressão linear simples (\(y \sim x\)) com diferentes níveis de ruído (\(R^2\)). Cada painel mostra a reta ajustada (cinza) e os valores observados (pontos). Os valores anotados indicam o coeficiente angular simulado (\(\beta\)), o coeficiente angular estimado (\(\hat{\beta}\)) e o \(R^2\) observado.
- Erro quadrático médio (\(RMSE\)) (43.21): Mede a média dos erros ao quadrado entre os valores observados e os valores previstos pelo modelo, onde \(y_i\) são os valores observados, \(\hat{y}_i\) são os valores previstos pelo modelo, e \(n\) é o número de observações. Valores menores indicam melhor ajuste.REF?
\[\begin{equation} \tag{43.21} RMSE = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2} \end{equation}\]
- Critério de Informação Akaike (\(AIC\)) (43.22) e Critério de Informação Bayesiano (\(BIC\)) (43.23): Avaliam o ajuste do modelo penalizando a complexidade (número de parâmetros), onde \(k\) é o número de parâmetros do modelo, \(L\) é a verossimilhança máxima do modelo, e \(n\) é o tamanho da amostra. Modelos com menor AIC ou BIC são preferíveis.REF?
\[\begin{equation} \tag{43.22} AIC = 2k - 2\ln(L) \end{equation}\]
\[\begin{equation} \tag{43.23} BIC = \ln(n)k - 2\ln(L) \end{equation}\]
- Desvio residual (\(\sigma\)): Mede a variabilidade dos resíduos do modelo. Valores menores indicam melhor ajuste.REF?
| Métrica | Valor |
|---|---|
| AIC | 513.017 |
| AIC corrigido | 513.267 |
| BIC | 520.833 |
| \(R^2\) | 0.007 |
| \(R^2_{ajustado}\) | -0.003 |
| Erro quadrático médio (RMSE) | 3.053 |
| Desvio residual (sigma) | 3.084 |
O pacote performance315 fornece a função model_performance para calcular as métricas de ajuste da regressão adequadas ao modelo pré-especificado.
O pacote performance315 fornece a função compare_performance para comparar o desempenho e a qualidade do ajuste de diversos modelos de regressão pré-especificados.
43.16 Calibração de modelos
43.16.1 Como calibrar modelos estatísticos?
- .REF?
Ferreira, Arthur de Sá. Ciência com R: Perguntas e respostas para pesquisadores e analistas de dados. Rio de Janeiro: 1a edição,