Capítulo 57 Simulação computacional
57.1 Simulações computacionais
57.1.1 O que são simulações computacionais?
- Simulações computacionais consistem na geração de dados artificiais a partir de modelos matemáticos ou probabilísticos, permitindo testar hipóteses, validar métodos e explorar cenários complexos sem necessidade de dados reais.14
57.1.2 Por que estudos de simulação devem ser tratados como experimentos científicos?
Simulações são experimentos empíricos, ainda que realizados em ambiente computacional.482
Devem seguir princípios de planejamento, incluindo definição clara de objetivos, delineamento de cenários e análise adequada dos resultados.471,482
Falhas de planejamento ou de relatório podem levar a interpretações equivocadas do desempenho de métodos estatísticos.482
57.1.3 O que são estudos de simulação estatística?
Estudos de simulação estatística são experimentos computacionais nos quais dados artificiais são gerados a partir de um mecanismo probabilístico conhecido.483
Diferentemente da análise de dados reais, nas simulações os valores verdadeiros dos parâmetros são definidos pelo pesquisador, permitindo avaliar diretamente se um método estatístico recupera corretamente esses valores.483
Estudos de simulação são amplamente utilizados para investigar o comportamento de métodos estatísticos em diferentes cenários e condições de dados.483
57.1.4 Qual é o papel dos estudos de simulação em pesquisa científica?
Em muitos problemas estatísticos existem vários métodos possíveis para análise de dados. O desempenho desses métodos depende de suposições que nem sempre são satisfeitas em dados reais, como normalidade das variáveis, ausência de erros de medição ou independência das observações.483
Estudos de simulação permitem avaliar como os métodos se comportam quando essas suposições são atendidas ou violadas.483
57.1.5 Por que não avaliar métodos estatísticos apenas com dados reais?
Em dados reais, o valor verdadeiro dos parâmetros populacionais geralmente é desconhecido.483
Portanto, não é possível saber se um método estatístico estimou corretamente um efeito ou se um teste rejeitou corretamente uma hipótese.483
Em simulações, o valor verdadeiro é definido pelo pesquisador, permitindo comparar diretamente o resultado do método com a verdade conhecida.483
57.1.6 Quais são as principais vantagens de estudos de simulação?
Permitem avaliar métodos estatísticos quando a verdade é conhecida.483
Possibilitam testar diferentes cenários de dados, incluindo situações raras ou difíceis de observar empiricamente.483
Permitem investigar sistematicamente o impacto de fatores como tamanho da amostra, distribuição dos dados ou presença de erros de medição.483
57.1.7 Quais são as limitações de estudos de simulação?
Os cenários simulados podem ser simplificações da realidade.483
Resultados podem depender das suposições adotadas no mecanismo gerador de dados.483
Estudos de simulação complexos podem demandar grande poder computacional.483
Existe risco de interpretação inadequada se os cenários não forem bem escolhidos ou relatados.483
57.2 Simulações em todo o fluxo de trabalho estatístico
57.2.1 Qual é o papel das simulações no fluxo de trabalho estatístico?
Estudos de simulação são utilizados para avaliar o desempenho de métodos estatísticos, comparando estimadores, testes de hipótese ou modelos preditivos em cenários controlados.484
As simulações desempenham um papel amplo, participando de praticamente todas as etapas do fluxo de trabalho estatístico, desde a especificação do modelo até a interpretação dos resultados.484
Em uma perspectiva moderna, as simulações podem ser utilizadas em quatro grandes etapas: especificação do modelo; verificação do modelo; inferência estatística; e checagem e validação do modelo.484
57.2.2 Como as simulações auxiliam na especificação de modelos?
Simulações podem ser usadas para verificar se um modelo produz dados plausíveis antes mesmo da coleta ou análise dos dados reais.484
Essa estratégia é conhecida em contextos bayesianos como prior predictive checking, na qual dados são simulados a partir do modelo proposto para avaliar se os resultados gerados são compatíveis com o conhecimento prévio disponível.484
Dessa forma, simulações ajudam a identificar especificações inadequadas ainda nas fases iniciais do desenvolvimento do modelo.484
57.2.3 Como as simulações contribuem para a verificação de modelos?
Antes de aplicar um método a dados reais, é importante verificar se ele funciona corretamente quando suas suposições são satisfeitas.484
Em muitos casos, a única forma prática de avaliar propriedades como viés, cobertura de intervalos de confiança ou calibração de incerteza é por meio de simulações.484
Técnicas modernas, como Simulation-Based Calibration (SBC), utilizam simulações repetidas para verificar se distribuições posteriores e estimativas probabilísticas estão corretamente calibradas.484
57.2.4 Como as simulações podem ser utilizadas diretamente para inferência?
Em alguns problemas, o cálculo analítico da distribuição de interesse é impossível ou extremamente difícil.484
Nesses casos, simulações podem ser utilizadas diretamente para realizar inferência estatística, estimar parâmetros ou conduzir testes de hipótese.484
Métodos como Monte Carlo, Markov Chain Monte Carlo (MCMC) e Approximate Bayesian Computation (ABC) são exemplos de abordagens que utilizam simulações para aproximar distribuições probabilísticas complexas.484
57.2.5 Como as simulações auxiliam na validação de modelos?
Após o ajuste de um modelo, simulações podem ser utilizadas para gerar novos conjuntos de dados a partir dos parâmetros estimados.484
Esses dados simulados podem ser comparados aos dados observados para verificar se o modelo reproduz adequadamente os padrões presentes na realidade para avaliar a adequação do modelo aos dados.484
57.3 Métodos de simulação
57.3.1 Quais são os elementos fundamentais de um estudo de simulação?
Objetivo da simulação: Definir o que se pretende investigar, como avaliar um método ou comparar diferentes abordagens.482,483
Mecanismo gerador de dados: Especificar como os dados simulados serão gerados, incluindo distribuição, parâmetros e estrutura das variáveis.482,483
Métodos de análise: Aplicar aos dados simulados os métodos estatísticos que se deseja avaliar ou comparar.482,483
Medidas de desempenho: Avaliar os métodos usando critérios como viés, erro tipo I, poder estatístico ou cobertura de intervalos de confiança.482,483
Número de repetições: Repetir a simulação muitas vezes para reduzir o efeito da variabilidade aleatória e obter estimativas mais estáveis.482,483
57.3.2 O que é um cenário de simulação?
Um cenário de simulação corresponde a uma combinação específica de parâmetros utilizados no mecanismo gerador de dados.483
Cenários podem variar em tamanho da amostra, distribuição das variáveis, intensidade do efeito ou presença de erro de medição.483
Avaliar múltiplos cenários permite investigar como o desempenho de um método estatístico muda em diferentes condições de dados.483
Em muitos estudos, diferentes cenários correspondem a combinações fatoriais de parâmetros, permitindo tratar o estudo de simulação como um experimento planejado.471
57.3.3 Quais são os principais elementos para avaliar a qualidade de um modelo de simulação?
Verificação: processo de confirmar que o modelo computacional implementa corretamente o modelo matemático e seus algoritmos.485
Validação: avaliação de quão bem o modelo representa o sistema real dentro do contexto para o qual foi desenvolvido.485
Quantificação da incerteza: análise da variabilidade e das incertezas presentes nos dados, parâmetros ou estruturas do modelo.485
Análise de sensibilidade: investigação de como mudanças nos parâmetros de entrada afetam os resultados da simulação.485
57.3.4 Por que é necessário repetir muitas simulações?
Mesmo em simulações, os resultados variam devido à variabilidade aleatória das amostras geradas.483
Por isso, é necessário repetir o processo de geração de dados e análise muitas vezes.483
A média dos resultados obtidos ao longo das repetições fornece uma avaliação mais estável do desempenho do método estatístico.483
57.3.5 Quais boas práticas devem ser seguidas em estudos de modelagem e simulação?
Defina claramente o objetivo da simulação e as hipóteses a serem testadas, incluindo quais aspectos do fenômeno ou do método você pretende avaliar.16
Documente detalhadamente o processo de simulação, incluindo os parâmetros utilizados, a lógica do algoritmo e as suposições feitas.486
Compartilhar dados, modelos e códigos sempre que possível para facilitar a reprodutibilidade científica.485
O pacote base31 fornece a função set.seed para especificar uma semente e garantir a reprodutibilidade de computações que envolvem números aleatórios.
O pacote stats159 fornece a função rnorm para simular dados de uma distribuição normal.
O pacote stats159 fornece a função rbinom para simular dados de uma distribuição Binomial.
O pacote stats159 fornece a função rpois para simular dados de uma distribuição Poisson.
O pacote stats159 fornece a função rexp para simular dados de uma distribuição Exponencial.
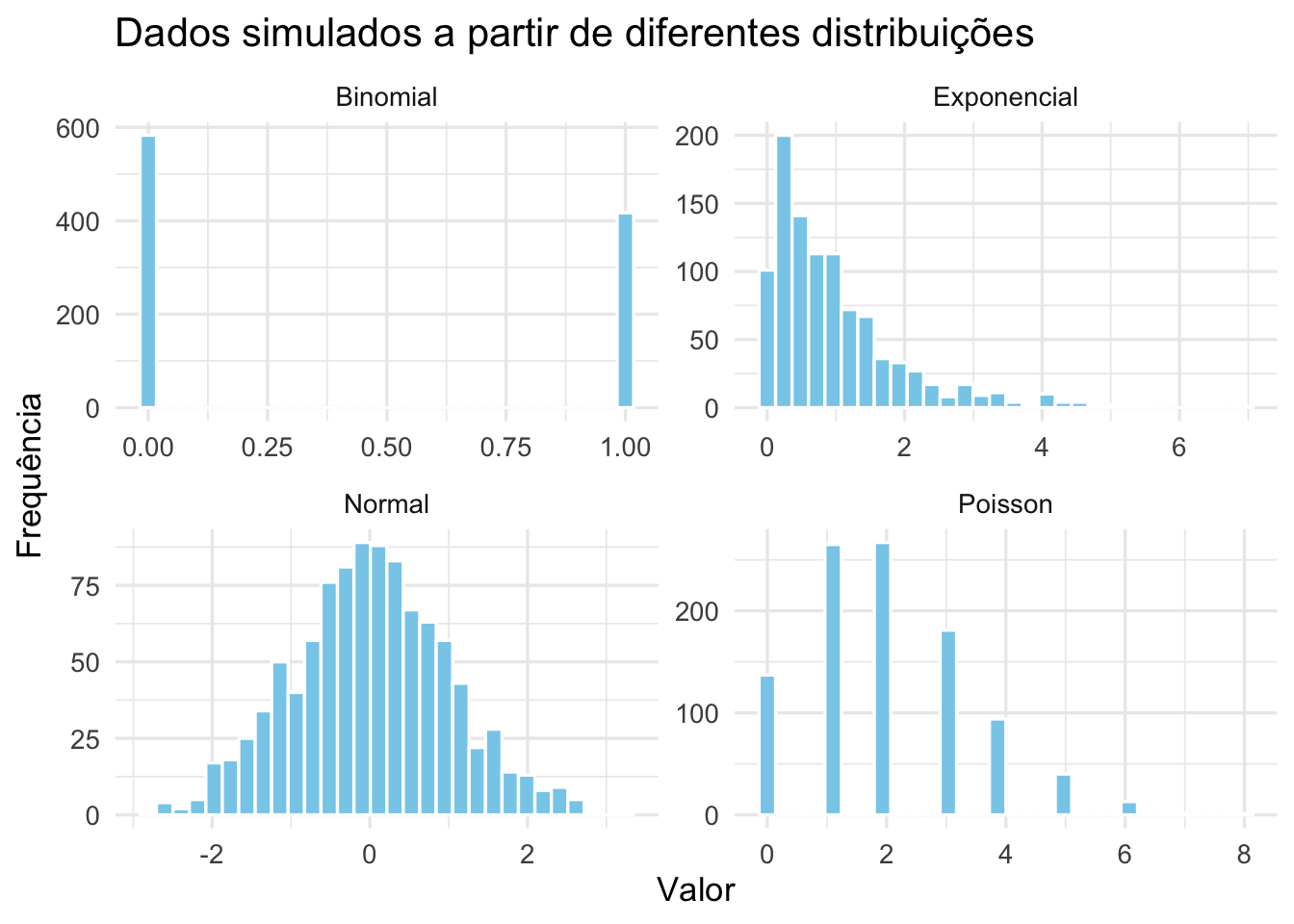
Figura 57.1: Dados simulados a partir de diferentes distribuições: Normal(0,1), Binomial(1,0.4), Poisson(2) e Exponencial(1).
57.4 Método de Monte Carlo
57.4.1 O que é o método de Monte Carlo?
O método de Monte Carlo consiste em utilizar geração repetida de números aleatórios para estimar propriedades de sistemas matemáticos ou estatísticos complexos.487
A ideia central é aproximar resultados teóricos por meio da simulação de muitas amostras aleatórias.487
No método Markov Chain Monte Carlo (MCMC), o modelo de Markov é usado para gerar amostras de distribuições complexas a partir da simulação de cadeias com distribuição estacionária prescrita.408
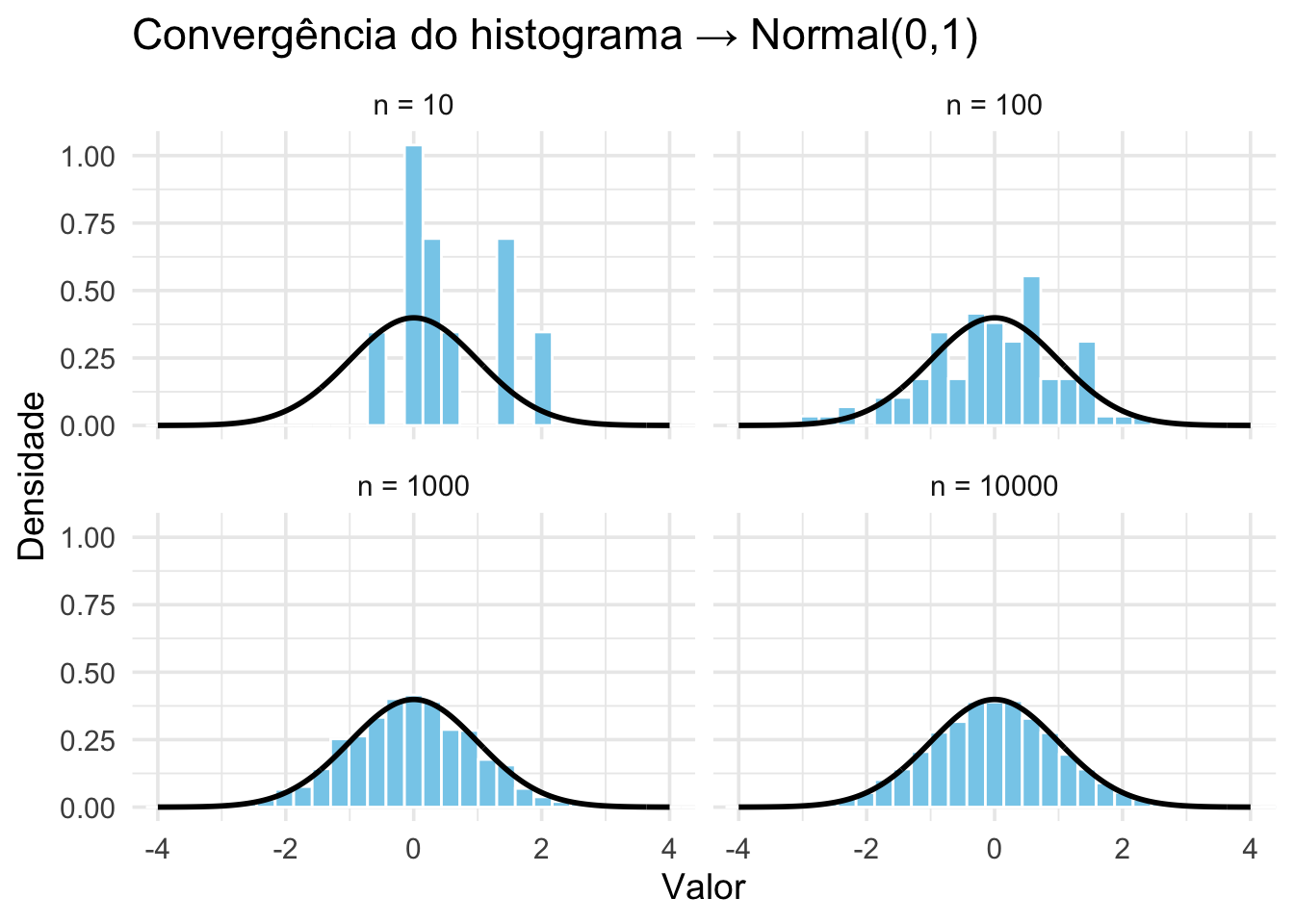
Figura 57.2: Convergência do histograma para a PDF teórica da Normal(0,1) com o aumento do tamanho amostral (n = 10, 100, 1000, 10000).
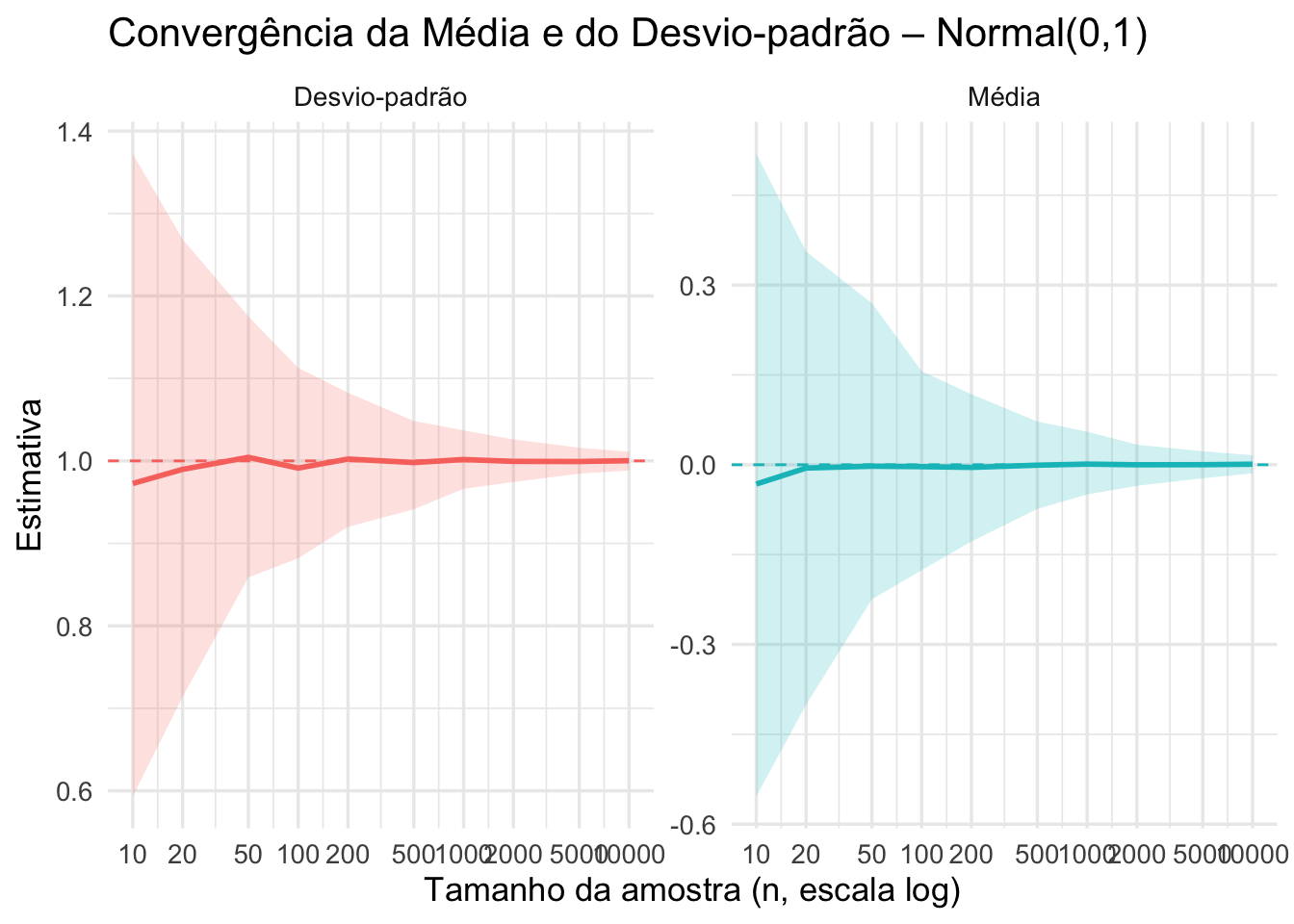
Figura 57.3: Convergência da média e do desvio-padrão amostral para os valores teóricos (0 e 1, respectivamente) com o aumento do tamanho amostral (n = 10, 20, 50, 100, 200, 500, 1000, 2000, 5000, 10000).
O pacote base31 fornece a função set.seed para especificar uma semente para reprodutibilidade de computações que envolvem números aleatórios.
O pacote simstudy488 fornece as funções defData e genData para criar variáveis e simular um banco de dados de acordo com o delineamento pré-especificado, respectivamente.
O pacote faux489 fornece a função sim_design para simular um banco de dados de acordo com o delineamento pré-especificado.
O pacote InteractionPoweR445 fornece a função generate_interaction para simular bancos de dados com efeitos de interação.
57.4.2 Como escolher a distribuição adequada em um estudo de simulação?
- Em estudos de simulação, é comum avaliar múltiplas distribuições para investigar a sensibilidade dos resultados às suposições do modelo.16
57.5 Avaliação de métodos estatísticos em simulações
57.5.1 Quais critérios são usados para avaliar métodos estatísticos em simulações?
Erro tipo I: probabilidade de rejeitar uma hipótese nula verdadeira.483
Poder estatístico: probabilidade de detectar um efeito quando ele realmente existe.483
Viés das estimativas: diferença entre o valor estimado e o valor verdadeiro do parâmetro.483
Cobertura de intervalos de confiança: proporção de intervalos que contêm o valor verdadeiro do parâmetro.483
Erro de predição: diferença entre valores previstos e valores observados em modelos preditivos.483
Estabilidade: grau de consistência do desempenho do método quando diferentes amostras são geradas sob o mesmo cenário de simulação.483
Custo computacional: quantidade de recursos computacionais necessários para executar o método, como tempo de processamento ou uso de memória.483
Sucesso da computação: proporção de execuções nas quais o método converge ou produz resultados válidos sem falhas numéricas ou problemas de otimização.483
57.5.2 O que é o erro padrão de Monte Carlo?
Em estudos de simulação, as estimativas de desempenho de um método estatístico (por exemplo, viés, poder estatístico ou erro tipo I) são calculadas a partir de um número finito de repetições da simulação.482
Como cada repetição utiliza uma amostra aleatória diferente, essas estimativas também apresentam variabilidade aleatória.482
O erro padrão de Monte Carlo (Monte Carlo standard error, MCSE) quantifica essa variabilidade e indica o grau de incerteza associado às estimativas obtidas na simulação.482
O MCSE mede a precisão com que uma medida de desempenho foi estimada a partir do número de repetições realizadas.482
Gráficos como zipper (zip) plots podem ser utilizados para avaliar visualmente a cobertura de intervalos de confiança em estudos de simulação.482,490
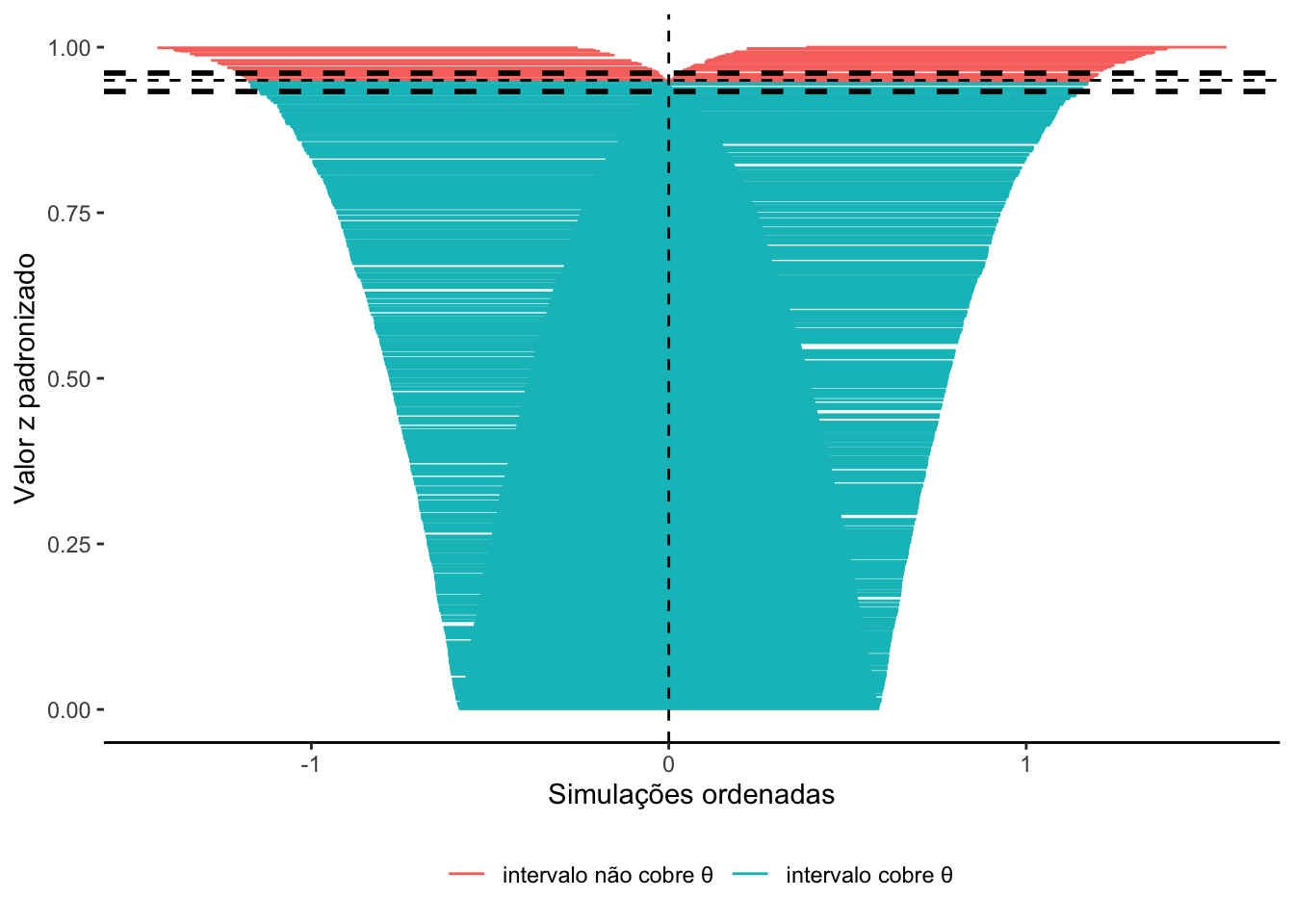
Figura 57.4: Cobertura de Intervalos de Confiança em um estudo de simulação.
O pacote rsimsum491 fornece a função simsum para computar o desempenho de estudos de simulação.
57.6 Diretrizes para redação
57.6.1 Quais são as diretrizes para redação de estudos de simulação computacional?
Visite a rede Enhancing the QUAlity and Transparency Of health Research (EQUATOR Network) para encontrar diretrizes específicas.
Strengthening the reporting of empirical simulation studies: Introducing the STRESS guidelines.492
Ferreira, Arthur de Sá. Ciência com R: Perguntas e respostas para pesquisadores e analistas de dados. Rio de Janeiro: 1a edição,