Capítulo 26 Análise robusta
26.1 Raciocínio inferencial robusto
26.1.1 O que é análise robusta?
- Análise robusta é uma abordagem estatística que busca fornecer resultados confiáveis mesmo quando as suposições clássicas dos modelos estatísticos são violadas.293
26.1.2 Por que usar análise robusta?
Métodos clássicos como ANOVA e regressão por mínimos quadrados assumem normalidade e homoscedasticidade — suposições frequentemente violadas na prática.293
Violações de suposições podem comprometer os resultados, reduzindo o poder estatístico, distorcendo os intervalos de confiança e obscurecendo as reais diferenças entre grupos.293
Testar previamente as suposições não é suficiente: testes de homoscedasticidade têm baixo poder e não garantem segurança analítica.293
Métodos estatísticos robustos oferecem uma solução mais segura e eficaz, lidando melhor com dados não ideais.293
26.1.3 Quando usar análise robusta?
Em alguns casos, os métodos robustos confirmam os resultados clássicos; em outros, revelam interpretações completamente diferentes.293
A forma de saber o impacto real dos métodos robustos é usá-los e comparar com os métodos tradicionais.293
26.1.4 Por que métodos robustos são preferíveis?
Métodos robustos têm a vantagem de resistir à influência de valores extremos, fornecendo medidas de posição e dispersão mais estáveis.211
Estimadores robustos oferecem maior segurança na presença de até 50% de contaminação nos dados, o que representa um ganho significativo em relação aos métodos clássicos.211
26.2 Valores discrepantes
26.2.1 O que são valores discrepantes (outliers)?
Em termos gerais, um valor discrepante — “fora da curva” ou outlier — é uma observação que possui um valor relativamente grande ou pequeno em comparação com a maioria das observações.286,294
Um valor discrepante é uma observação incomum que exerce influência indevida em uma análise.286
Valores discrepantes são dados com valores altos de resíduos.294
Nem todo valor extremo é um valor discrepante, e nem todo valor discrepante será influente.REF?
Alguns valores discrepantes são apenas pontos incomuns, outros de fato mudam os resultados e por isso são chamados de influentes.REF?
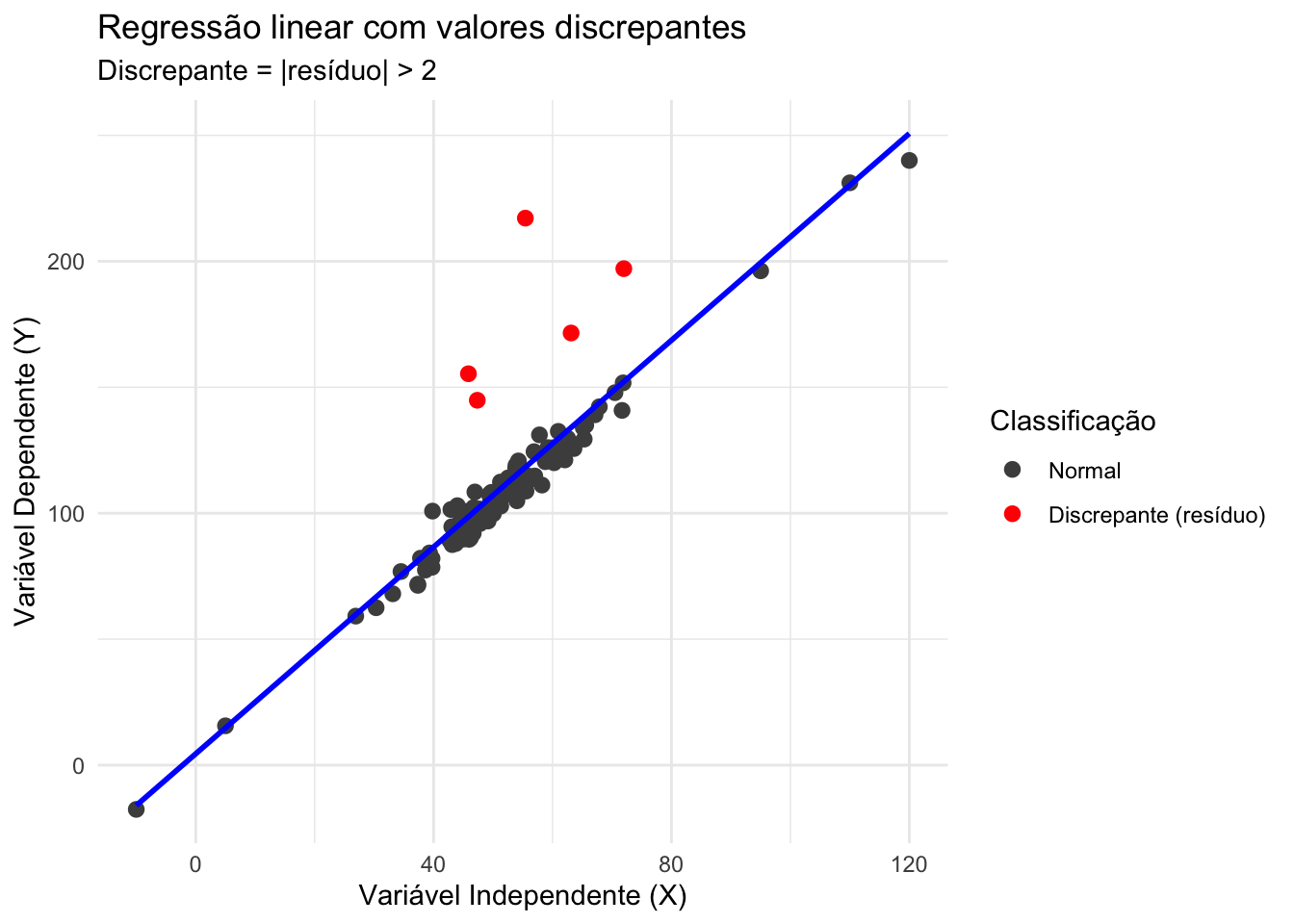
Figura 26.1: Regressão linear com valores discrepantes
26.2.2 Quais são os tipos de valores discrepantes?
Valores discrepantes podem ser categorizados em três subtipos: outliers de erro, outliers interessantes e outliers aleatórios.294
Os valores discrepantes de erro são observações claramente não legítimas, distantes de outros dados devido a imprecisões por erro de mensuração e/ou codificação.294
Os valores discrepantes interessantes não são claramente erros, mas podem refletir um processo/mecanismo potencialmente interessante para futuras pesquisas.294
Os valores discrepantes aleatórios são observações que resultam por acaso, sem qualquer padrão ou tendência conhecida.294
Valores discrepantes podem ser univariados ou multivariados.294
26.2.3 Por que é importante avaliar valores discrepantes?
Excluir o valor discrepante implica em reduzir inadequadamente a variância, ao remover um valor que de fato pertence à distribuição considerada.294
Manter os dados inalterados (mantendo o valor discrepante) implica em aumentar inadequadamente a variância, pois a observação não pertence à distribuição que fundamenta o experimento.294
Em ambos os casos, uma decisão errada pode influenciar o erro do tipo I (\(\alpha\) — rejeitar uma hipótese verdadeira) ou o erro do tipo II (\(\beta\) — não rejeitar uma hipótese falsa).294
26.2.4 Como detectar valores discrepantes?
Na maioria das vezes, não há como saber de qual distribuição uma observação provém. Por isso, não é possível ter certeza se um valor é legítimo ou não dentro do contexto do experimento.294
Recomenda-se seguir um procedimento em duas etapas: detectar possíveis candidatos a outliers usando ferramentas quantitativas; e gerenciar os outliers, decidindo manter, remover ou recodificar os valores, com base em informações qualitativas.294
A detecção de outliers deve ser aplicada apenas uma vez no conjunto de dados; um erro comum é identificar e tratar os outliers (como remover ou recodificar) e, em seguida, reaplicar o procedimento no conjunto de dados já modificado.294
A detecção ou o tratamento dos outliers não deve ser realizada após a análise dos resultados, pois isso introduz viés nos resultados.294
26.2.5 Quais são os métodos para detectar valores discrepantes?
Valores univariados são comumente considerados outliers quando são mais extremos do que a média ± (desvio padrão × constante), ex.: 3 (99,7% de cobertura) ou 3,29 (99,9% de cobertura).294
Para detectar outliers univariados, recomenda-se o uso do Desvio Absoluto Mediano (Median Absolute Deviation, MAD), mais extremos que mediana ± uma constante (valor padrão: 1,4826).294,295
Para detectar outliers multivariados, recomenda-se o Determinante de Mínima Covariância (Minimum Covariance Determinant, MCD), pois possui ponto de quebra máximo e utiliza a mediana.294,296
Para detectar outliers multivariados, comumente utiliza-se a distância de Mahalanobis, que identifica valores muito distantes do centroide formado pela maioria dos dados (por exemplo, 99%).294
26.2.6 Quais testes são apropriados para detectar valores discrepantes?
A escolha do método de detecção depende da natureza do outlier, se univariado ou multivariado.211
Para valores univariados, podem ser usados boxplots (com pontos além de 1,5 vezes o intervalo interquartílico), z-scores clássicos (\(|z| > 2.5\) ou \(|z| > 3\)) ou z-scores robustos, que substituem média por mediana e desvio-padrão por estimadores robustos.211
Para valores multivariados, recomenda-se a distância de Mahalanobis para medir o afastamento em relação ao centroide, com ajustes robustos de covariância como MCD (Minimum Covariance Determinant) ou MVE (Minimum Volume Ellipsoid).211
Técnicas baseadas em análise de componentes principais (PCA) robusta também podem ser aplicadas para reduzir dimensionalidade e expor outliers mascarados.211
Métodos de trimming multivariado (MVT) podem iterativamente remover observações mais distantes, mas apresentam limitações em alta dimensionalidade.211
Estimadores com alto ponto de quebra, como o MCD, permitem detectar até 50% de outliers antes de comprometer a análise.211
26.2.7 Como manejar os valores discrepantes?
Manter outliers pode ser uma boa decisão se a maioria desses valores realmente pertence à distribuição de interesse.294
Manter outliers que pertencem a uma distribuição alternativa pode ser problemático, pois um teste pode se tornar significativo apenas por causa de um ou poucos outliers.294
Remover outliers pode ser eficaz quando eles distorcem a estimativa dos parâmetros da distribuição.294
Remover outliers que pertencem legitimamente à distribuição pode reduzir artificialmente a estimativa do erro.294
Remover outliers leva à perda de observações, especialmente em conjuntos de dados com muitas variáveis, quando outliers univariados são excluídos em cada variável.294
Recodificar outliers evita a perda de uma grande quantidade de dados, mas deve ser baseada em argumentos razoáveis e convincentes.294
Erros de observação e de medição são uma justificativa válida para descartar observações discrepantes.286
26.2.8 Como conduzir análises com valores discrepantes?
É importante reportar se existem valores discrepantes e como foram tratados.286
Valores discrepantes na variável de desfecho podem exigir uma abordagem mais refinada, especialmente quando representam uma variação real na variável que está sendo medida.286
Valores discrepantes em uma (co)variável podem surgir devido a um projeto experimental inadequado; nesse caso, abandonar a observação ou transformar a covariável são opções adequadas.286
Valores discrepantes podem ser recodificados usando a Winsorização,297 que transforma os outliers em valores de percentis específicos (como o 5º e o 95º).294
O pacote outliers298 fornece a função outlier para identificar os valores mais distantes da média.
O pacote outliers298 fornece a função rm.outlier para remover os valores mais distantes da média detectados por testes de hipótese e/ou substitui-los pela média ou mediana.
26.2.9 Como lidar com outliers na análise exploratória de dados?
Após a detecção, três estratégias principais podem ser adotadas: (1) manter os outliers, (2) removê-los ou (3) recodificá-los (por exemplo, com Winsorização).294
A escolha deve ser justificada com base no contexto teórico e nas características do banco de dados. Idealmente, erros devem ser corrigidos ou removidos, enquanto outliers interessantes podem gerar novas hipóteses de pesquisa.294
A decisão sobre como lidar com outliers deve ser definida a priori e preferencialmente registrada em plataformas de pré-registro. Essa prática aumenta a transparência, reduz a flexibilidade analítica e evita inflar taxas de erro tipo I.294
26.3 Valores influentes
26.3.1 O que são valores influentes?
- Valores influentes são observações que, se removidas, causariam uma mudança significativa nos resultados da análise estatística.REF?
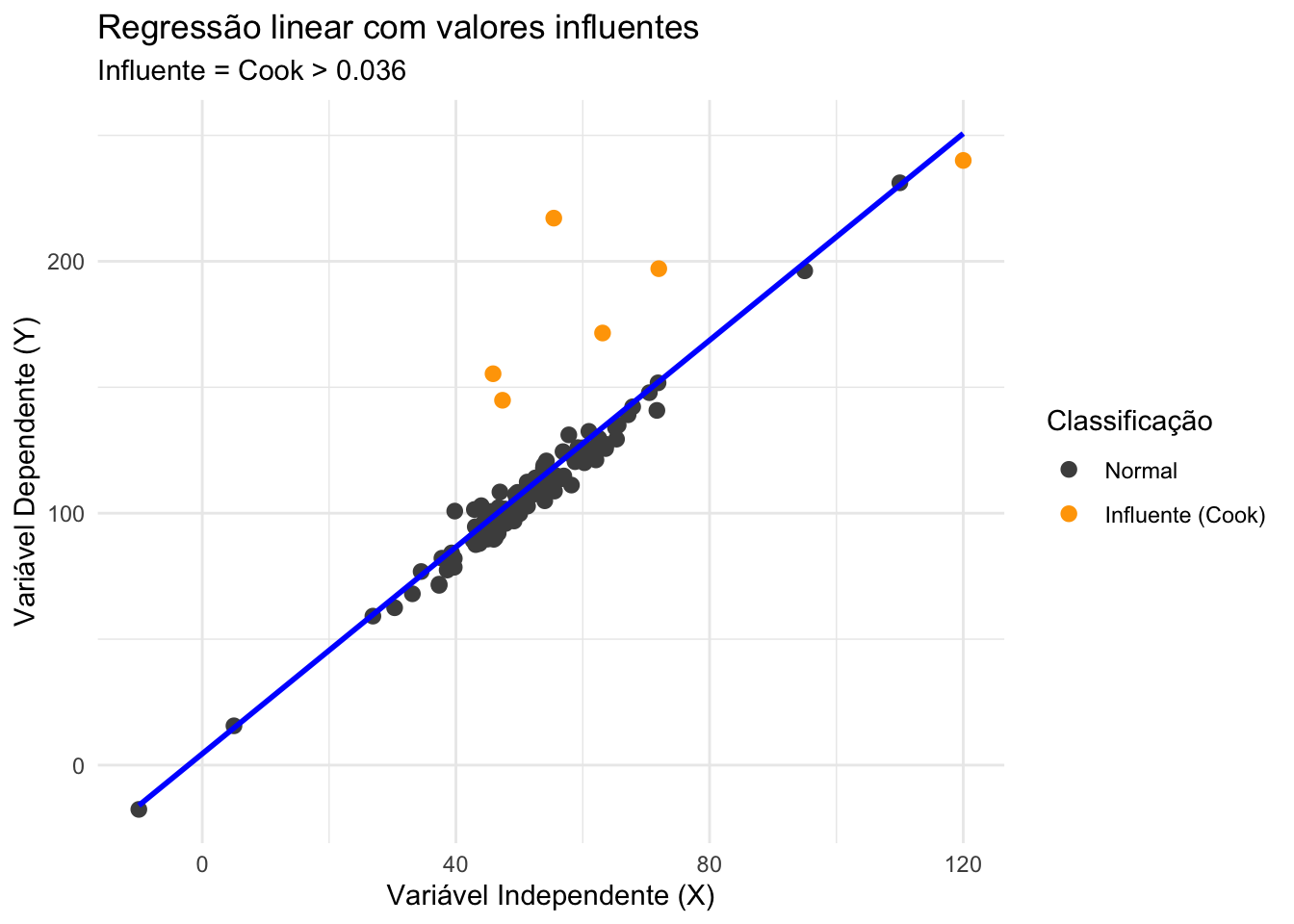
Figura 26.2: Regressão linear com valores influentes.
26.3.2 O que é função de influência?
- A função de influência mede a sensibilidade de um estimador a pequenas contaminações nos dados. Um estimador é considerado robusto se sua função de influência for limitada, indicando que valores extremos não exercem impacto desproporcional.299
26.3.3 O que é ponto de quebra?
- O ponto de quebra representa a fração mínima de observações contaminadas necessária para distorcer um estimador até o infinito. Por exemplo, a média tem ponto de quebra 0, enquanto a mediana atinge o ponto de quebra máximo (50%).299
26.3.4 Como detectar valores influentes?
- A alavancagem (leverage) mede o quão distante uma observação está dos valores médios das variáveis independentes. Observações com alta alavancagem têm o potencial de influenciar significativamente a linha de regressão.REF?
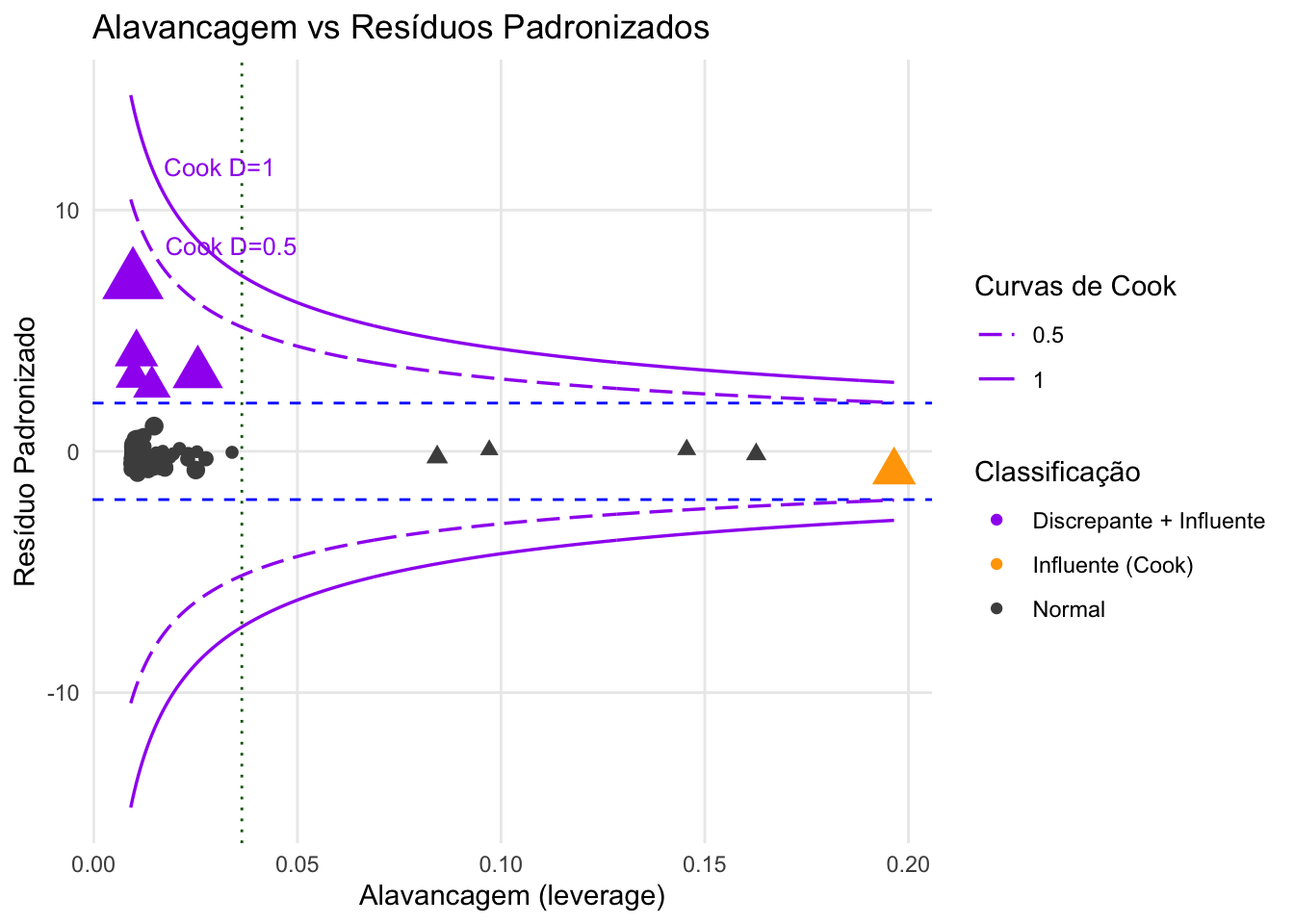
Figura 26.3: Alavancagem versus Resíduos Padronizados com distância de Cook para análise da influência de pontos.
26.4 Métodos robustos de tratamento de outliers
26.4.1 O que é Winsorização?
Winsorização é uma técnica que substitui os valores extremos (outliers) por valores menos extremos, preservando a estrutura dos dados.293
Winsorização é feita definindo limites superior e inferior e substituindo os valores que ultrapassam esses limites pelos próprios limites.293
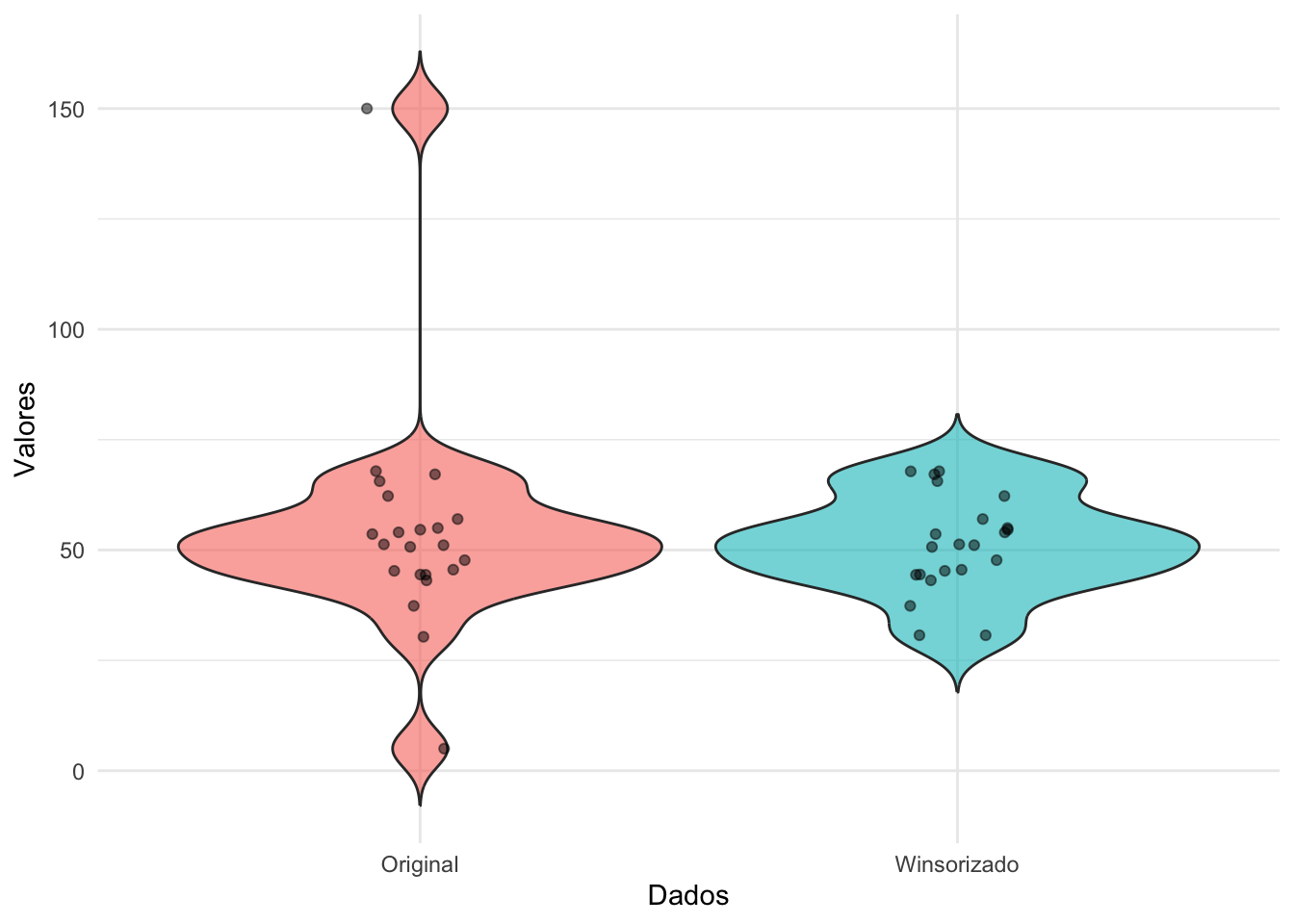
Figura 26.4: Boxplots comparando dados originais e dados Winsorizados.
26.4.2 Quais são as alternativas à Winsorização?
Podar (trimming): remove diretamente uma fração fixa das observações mais extremas.REF?
Estimadores robustos: resistem à influência de outliers sem transformar os dados.REF?
Transformações de variáveis: reduzem a assimetria e impacto de valores extremos, mas mudam a escala interpretativa.REF?
O pacote WRS2300 fornece as funções winmean e winvar para calcular a média e variância Winsorizadas.
O pacote WRS2300 fornece a função yuen para realizar o teste de comparação de Yuen de médias Winsorizadas para amostras independentes ou dependentes.
O pacote WRS2300 fornece a função wincor para calcular a correlação Winsorizada.
O pacote WRS2300 fornece as funções t1way, t2way e t3way para realizar testes de comparação de médias Winsorizadas para análise de variância para 1, 2 ou 3 fatores, respectivamente.
Ferreira, Arthur de Sá. Ciência com R: Perguntas e respostas para pesquisadores e analistas de dados. Rio de Janeiro: 1a edição,