Capítulo 17 Distribuições e parâmetros
17.1 Fontes de variabilidade
17.1.1 O que são fontes de variabilidade?
A variabilidade observada nos dados não surge de uma única causa, mas de diferentes processos que atuam simultaneamente durante a geração e a coleta dos dados.193
Compreender de onde vem a variação é essencial para interpretar distribuições, construir modelos e realizar inferência.193
A distribuição dos dados pode ser entendida como uma descrição da variabilidade resultante desses processos.193
17.1.2 Quais são as principais fontes de variabilidade?
Variabilidade real: resulta de diferenças reais entre indivíduos ou unidades observadas.193
Variabilidade de medição: decorre de limitações ou imperfeições nos instrumentos e métodos de medição. Mesmo quando o objeto medido não muda, repetidas medições podem produzir valores ligeiramente diferentes.193
Variabilidade amostral: surge porque diferentes amostras extraídas da mesma população podem produzir resultados distintos.193
Variabilidade experimental ou ambiental: relaciona-se a mudanças nas condições sob as quais os dados são obtidos, como temperatura, tempo, operador ou local de coleta.193
Variabilidade aleatória: refere-se à componente imprevisível associada ao acaso em processos naturais ou experimentais.193
17.1.3 Por que identificar as fontes de variabilidade é importante?
Permite distinguir entre variação real do fenômeno e ruído introduzido pelo processo de medição ou amostragem.193
Ajuda a escolher modelos estatísticos adequados para representar os dados.193
Orienta o desenho de experimentos e estratégias de amostragem para reduzir fontes indesejadas de variação.193
Fundamenta a interpretação das distribuições empíricas e teóricas utilizadas na inferência estatística.193
17.2 Distribuições de probabilidade
17.2.1 O que são distribuições de probabilidade?
A distribuição é o padrão de variação em uma variável ou conjunto de variáveis representado pelos dados.193
Uma distribuição de probabilidade é uma função que descreve os valores possíveis ou o intervalo de valores de uma variável (eixo horizontal) e a probabilidade ou frequência relativa com que os valores ocorrem (eixo vertical).136
17.2.2 Como representar distribuições de probabilidade?
Tabelas de frequência, polígonos de frequência, gráficos de barras, histogramas e boxplots são formas de representar distribuições de probabilidade.194
Tabelas de frequência mostram as categorias de medição e o número de observações em cada uma. É necessário conhecer o intervalo de valores (mínimo e máximo), que é dividido em intervalos arbitrários chamados “intervalos de classe”.194
Se houver muitos intervalos, não haverá redução significativa na quantidade de dados, e pequenas variações serão perceptíveis. Se houver poucos intervalos, a forma da distribuição não poderá ser adequadamente determinada.194
A quantidade de intervalos pode ser determinada pelo método de Sturges, que é dado pela fórmula \(k = 1 + 3.322 \times \log_{10}(n)\), onde \(k\) é o número de intervalos e \(n\) é o número de observações.195
A quantidade de intervalos pode ser determinada pelo método de Scott, que é dado pela fórmula \(h = 3.5 \times \text{sd}(x) \times n^{-1/3}\), onde \(h\) é a largura do intervalo, \(\text{sd}(x)\) é o desvio-padrão e \(n\) é o número de observações.196
A quantidade de intervalos pode ser determinada pelo método de Freedman-Diaconis, que é dado pela fórmula \(h = 2 \times \text{IQR}(x) \times n^{-1/3}\), onde \(h\) é a largura do intervalo, \(\text{IQR}(x)\) é o intervalo interquartil e \(n\) é o número de observações.197
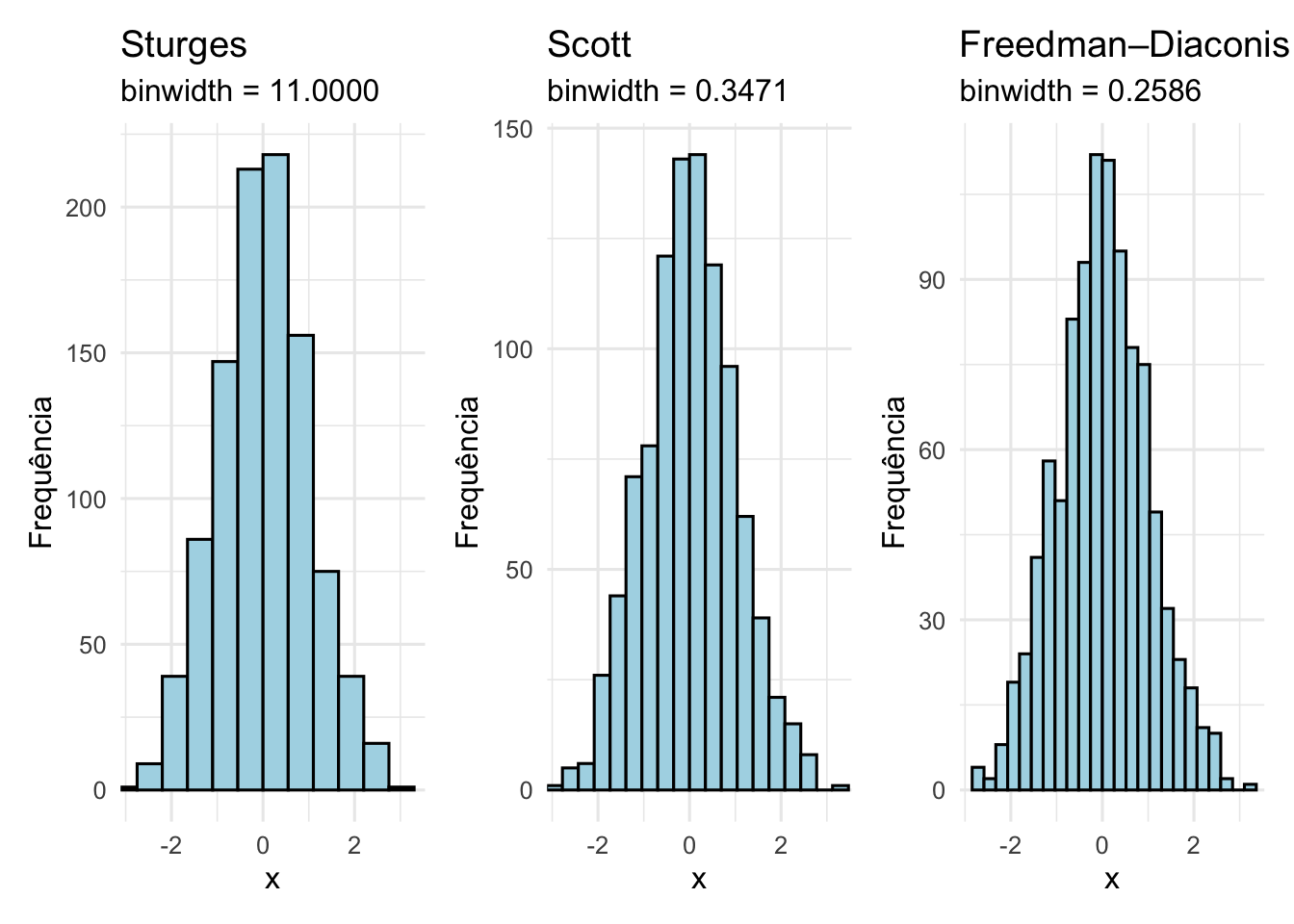
Figura 17.1: Histogramas com diferentes métodos de binning.: Sturges, Scott e Freedman-Diaconis.
A largura das classes pode ser determinada dividindo o intervalo total de observações pelo número de classes. Larguras desiguais podem ser usadas quando existirem grandes lacunas nos dados ou em contextos específicos. Os intervalos devem ser mutuamente exclusivos e não sobrepostos (ex.: <5, >10).194
Polígonos de frequência são gráficos de linhas que conectam os pontos médios de cada barra do histograma. Eles são úteis para comparar duas ou mais distribuições de frequência.194
Gráficos de barra verticais ou horizontais representam a distribuição de frequências de uma variável categórica. A altura de cada barra é proporcional à frequência da classe. A largura da barra é igual à largura da classe.194
Histogramas representam a distribuição de frequências de uma variável contínua. A altura de cada barra é proporcional à frequência da classe. A largura da barra é igual à largura da classe. A área de cada barra é proporcional à frequência da classe. A área total do histograma é igual ao número total de observações.194
Boxplots representam a distribuição de frequências de uma variável contínua. A linha central representa a mediana (Q2). A caixa inferior representa o primeiro quartil (Q1) e a caixa superior o terceiro quartil (Q3). Observações além de 1,5 vezes o intervalo interquartil (IQR) são representadas como valores atípicos.194
O pacote grDevices198 fornece funções da família nclass para determinar a quantidade de classes de um histograma com os métodos de Sturge195, Scott196 ou Freedman-Diaconis197.
O pacote ggplot2199 fornece a função geom_freqpoly para criar polígonos de frequência.
17.2.3 Quais características definem uma distribuição?
- Uma distribuição pode ser definida por modelos matemáticos e caracterizada por parâmetros de tendência central, dispersão, simetria e curtose.REF?
17.3 Tipos de distribuições
17.3.1 O que são distribuições empíricas?
- Distribuições empíricas são obtidas diretamente a partir dos dados observados, sendo geralmente representadas por histogramas, tabelas de frequência ou funções de distribuição empírica.193
17.3.2 O que são distribuições teóricas?
Distribuições teóricas correspondem a modelos matemáticos utilizados para representar o processo gerador dos dados, como as distribuições normal, binomial ou Poisson.193
A comparação entre distribuições empíricas e modelos teóricos é um passo fundamental na modelagem estatística e na inferência.193
17.3.3 O que são distribuições amostrais?
Distribuição amostral descreve a distribuição de uma estatística (como a média ou a proporção) quando calculada em múltiplas amostras da mesma população.193
As distribuições amostrais permitem quantificar a variabilidade associada às estimativas e constituem a base teórica para intervalos de confiança e testes de hipótese.193
17.3.4 Por que todas as distribuições são condicionais?
Uma distribuição descreve a variabilidade de uma variável sob determinadas condições ou suposições.193
Portanto, toda distribuição deve ser entendida como condicional ao processo gerador dos dados, ao modelo adotado ou às informações disponíveis.193
Na inferência estatística, muitas distribuições são condicionais aos parâmetros desconhecidos do modelo, como ocorre na distribuição amostral da média ou na distribuição binomial condicionada à probabilidade de sucesso.193
17.4 Distribuições univariadas
17.4.1 Quais são as distribuições mais comuns?
Distribuções discretas:
Bernoulli: resultado de um único teste com dois possíveis desfechos (sucesso ou fracasso).REF?
Binomial: número de sucessos em n tentativas independentes.REF?
Geométrica: número de tentativas necessárias até a ocorrência do primeiro sucesso.REF?
Binomial negativa: número de testes até o k-ésimo sucesso.REF?
Hipergeométrica: número de indivíduos na amostra tomados sem reposição.REF?
Poisson: número de eventos em um intervalo de tempo fixo.REF?
Uniforme: resultados (finitos) que são igualmente prováveis.REF?
Multinomial: resultados de múltiplos testes com mais de dois possíveis desfechos.REF?
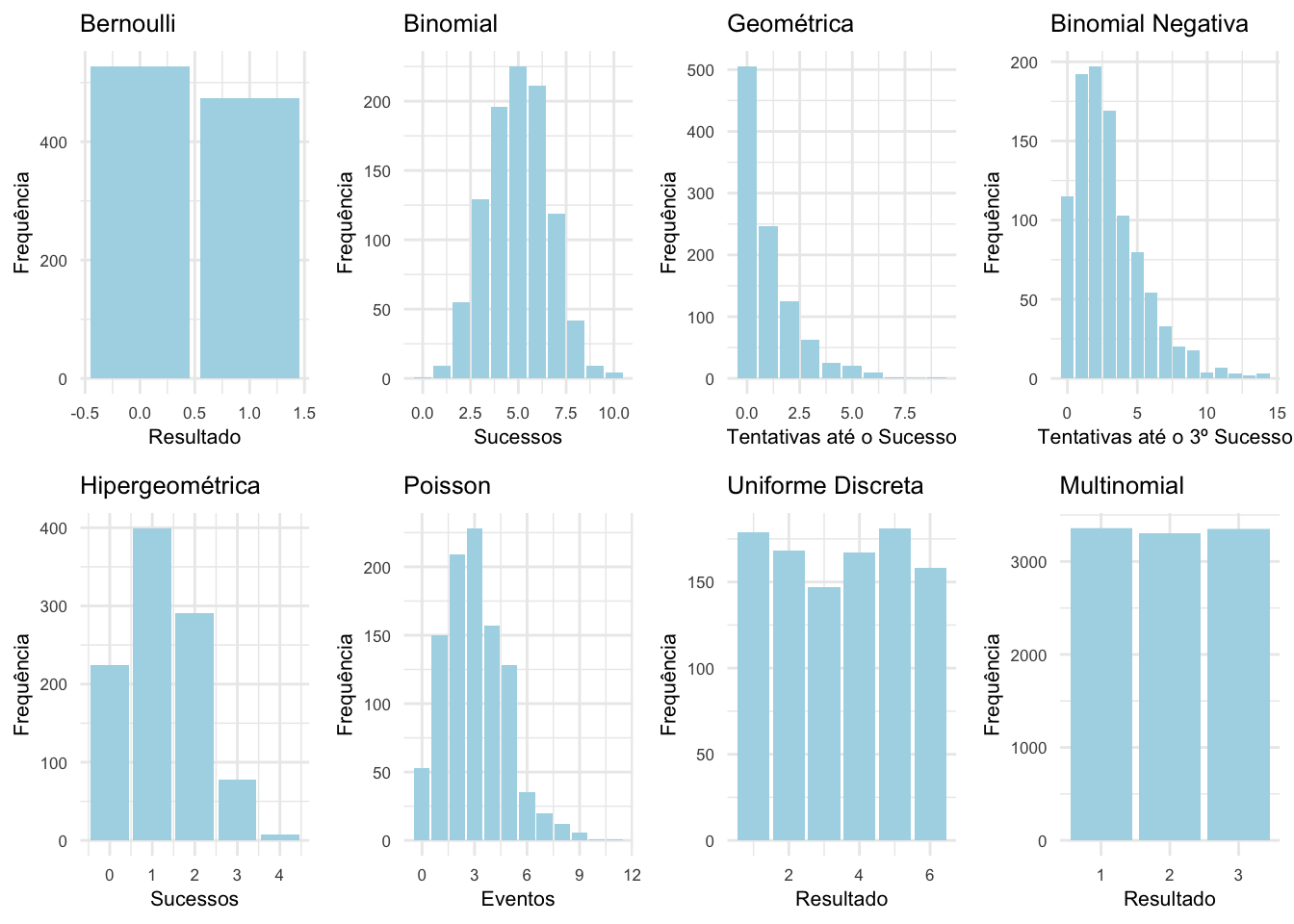
Figura 17.2: Distribuições discretas e suas funções de probabilidade.
Distribuições contínuas:
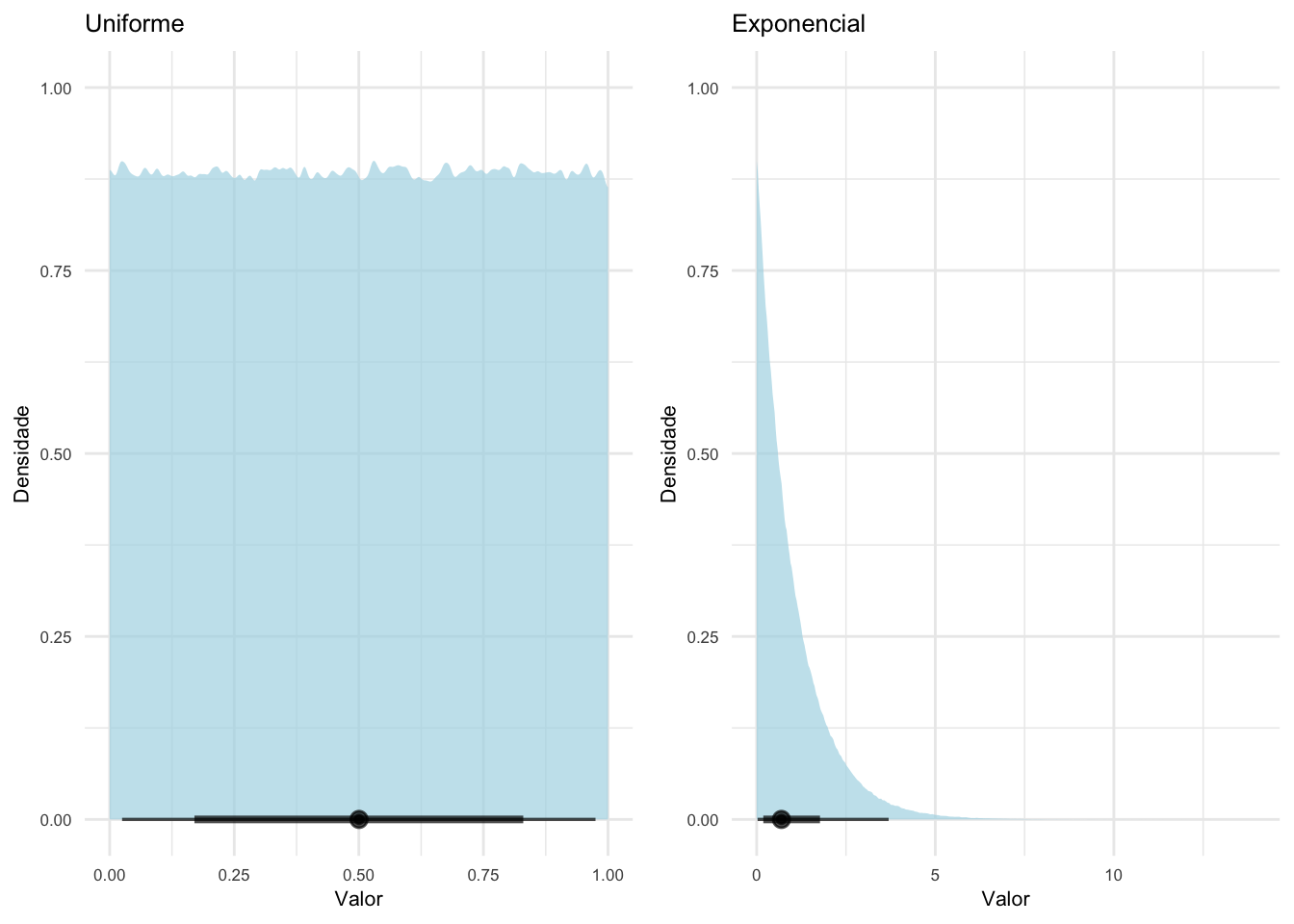
Figura 17.3: Distribuições contínuas básicas e suas funções de densidade.
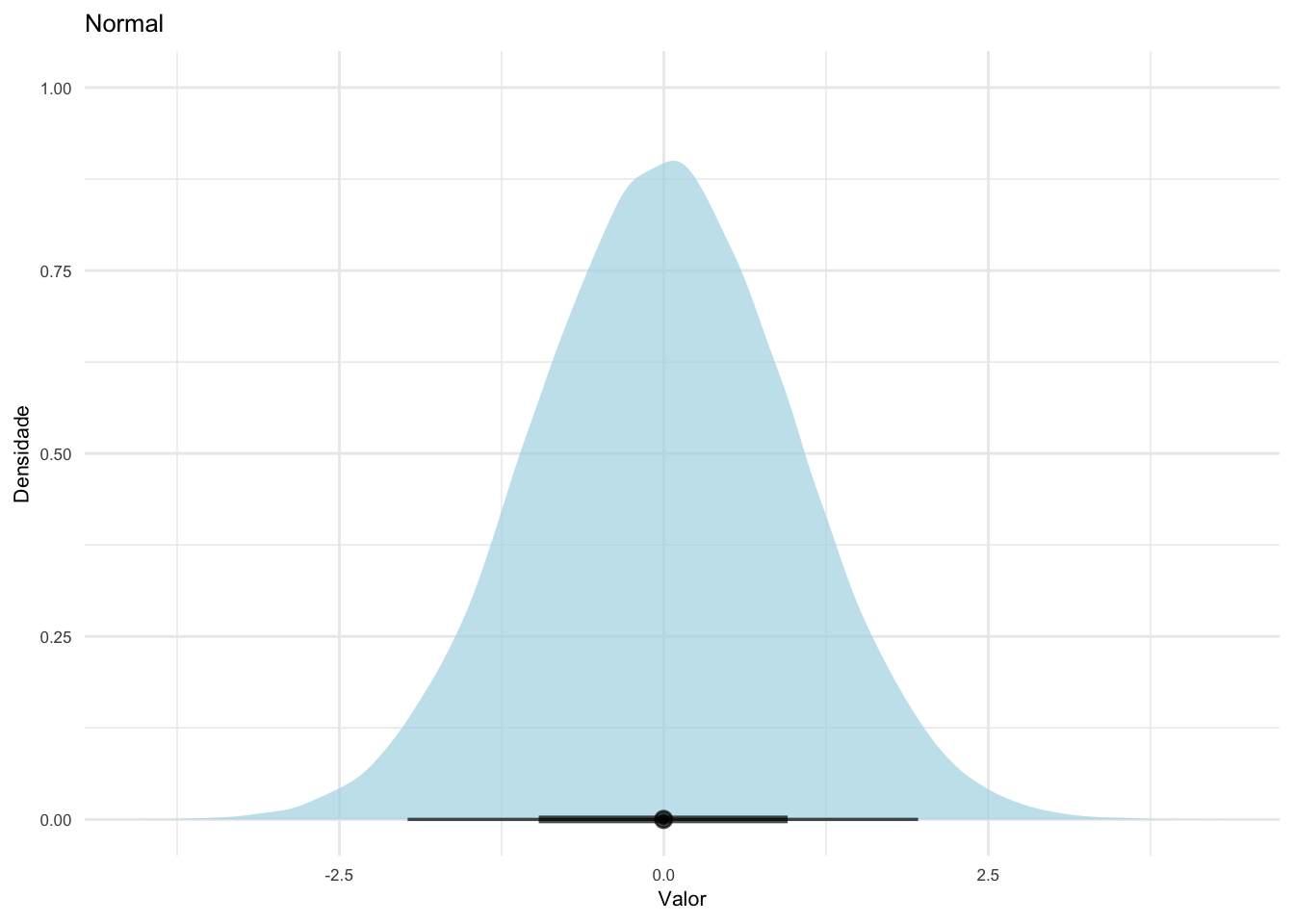
Figura 17.4: Distribuições contínuas aproximadas e suas funções de densidade.
Figura 17.5: Distribuições contínuas aproximadas e suas funções de densidade.
Figura 17.6: Distribuições contínuas para inferência e suas funções de densidade.
Figura 17.7: Distribuições contínuas para dados específicos e suas funções de densidade.
Figura 17.8: Distribuições contínuas para probabilidades e proporções e suas funções de densidade.
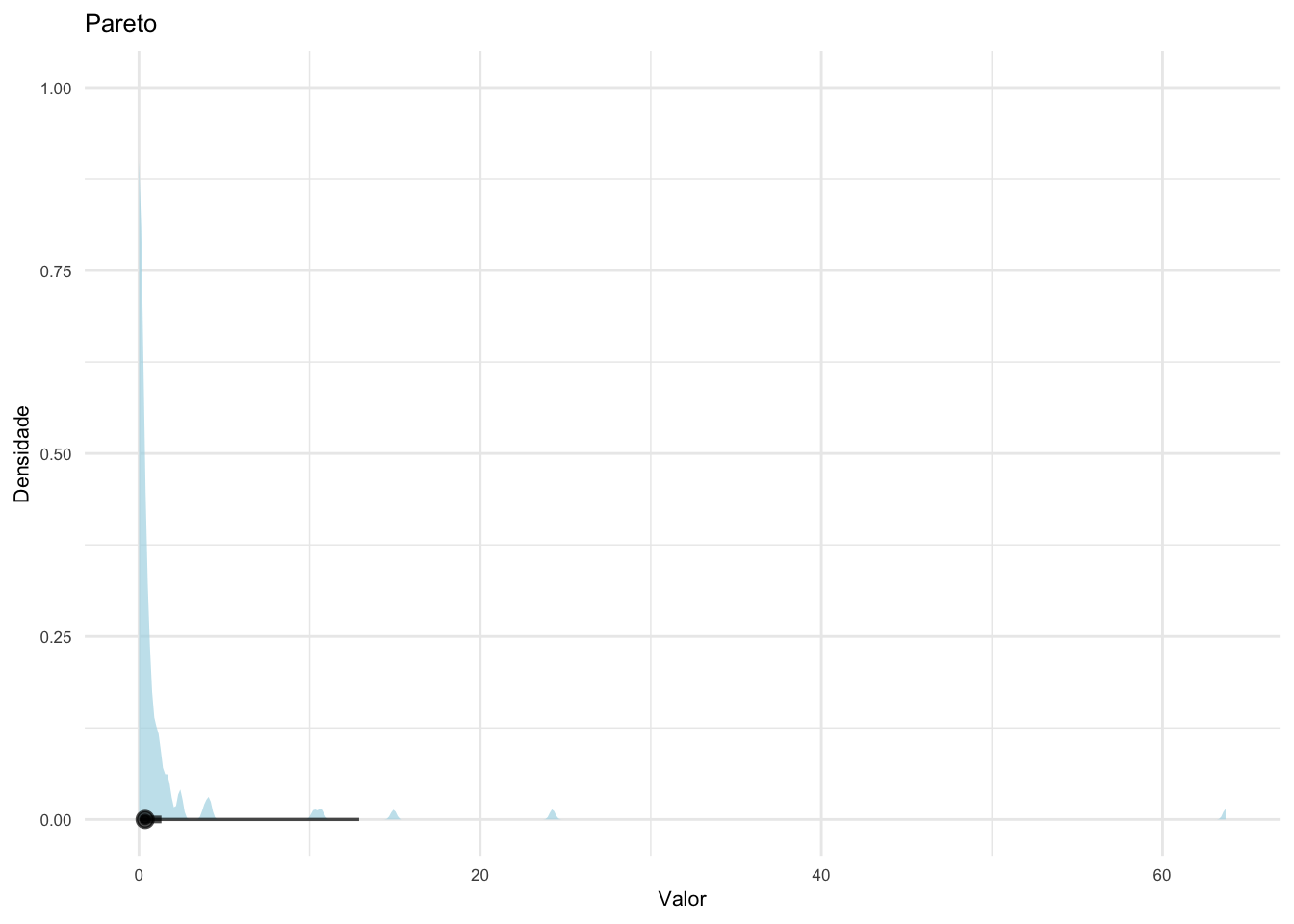
Figura 17.9: Distribuições contínuas com caudas pesadas e suas funções de densidade.
17.4.2 Quais são as funções de uma distribuição?
Função de massa de probabilidade (probability mass function, pmf) para variáveis discretas.REF?
Função de densidade de probabilidade (probability density function, pdf) para variáveis contínuas.REF?
Função de distribuição acumulada (cumulative distribution function, cdf).REF?
Função quantílica (quantile function).REF?
Função geradora de números aleatórios.REF?
O pacote stats159 fornece funções de distribuição e funções geradores de números aleatórios para as distribuições normal, binomial, qui-quadrado e uniforme, dentre outras.
O pacote ggdist200 fornece a função geom_slabinterval para criar gráficos de distribuição de probabilidade (p) e funções de densidade (d) as distribuições.
O pacote ggfortify201 fornece a função ggdistribution para criar gráficos de distribuição de probabilidade (p), funções de densidade (d), funções quantílicas (q) e funções geradores de números aleatórios (r) para as distribuições.
17.4.3 O que é a distribuição normal?
A distribuição normal (ou gaussiana) é uma distribuição com desvios simétricos positivos e negativos em torno de um valor central.137
A relação entre média e desvio-padrão permite interpretar a dispersão dos dados em distribuições aproximadamente normais. A regra empírica estabelece que cerca de 68,2% dos valores situam-se no intervalo \(\bar{x} \pm \sigma\), cerca de 95,4% no intervalo \(\bar{x} \pm 2\sigma\).137,202
O desvio-padrão fornece uma medida direta da variabilidade dos dados em torno da média, permitindo avaliar quão dispersos ou concentrados estão os valores observados em uma amostra.202
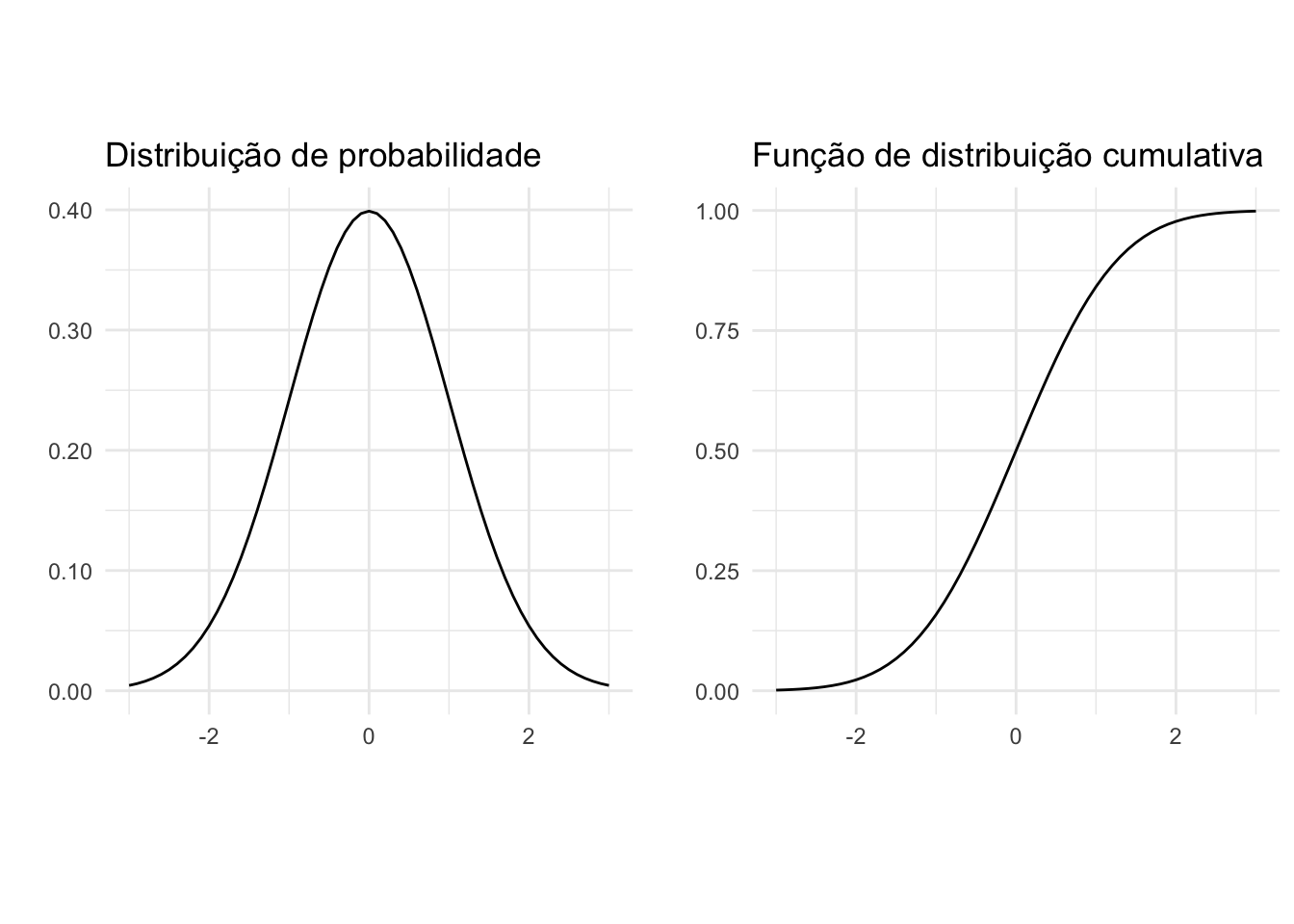
Figura 17.10: Distribuições e funções de probabilidade.
17.5 Distribuições bivariadas
17.5.1 O que são distribuições bivariadas?
- .REF?
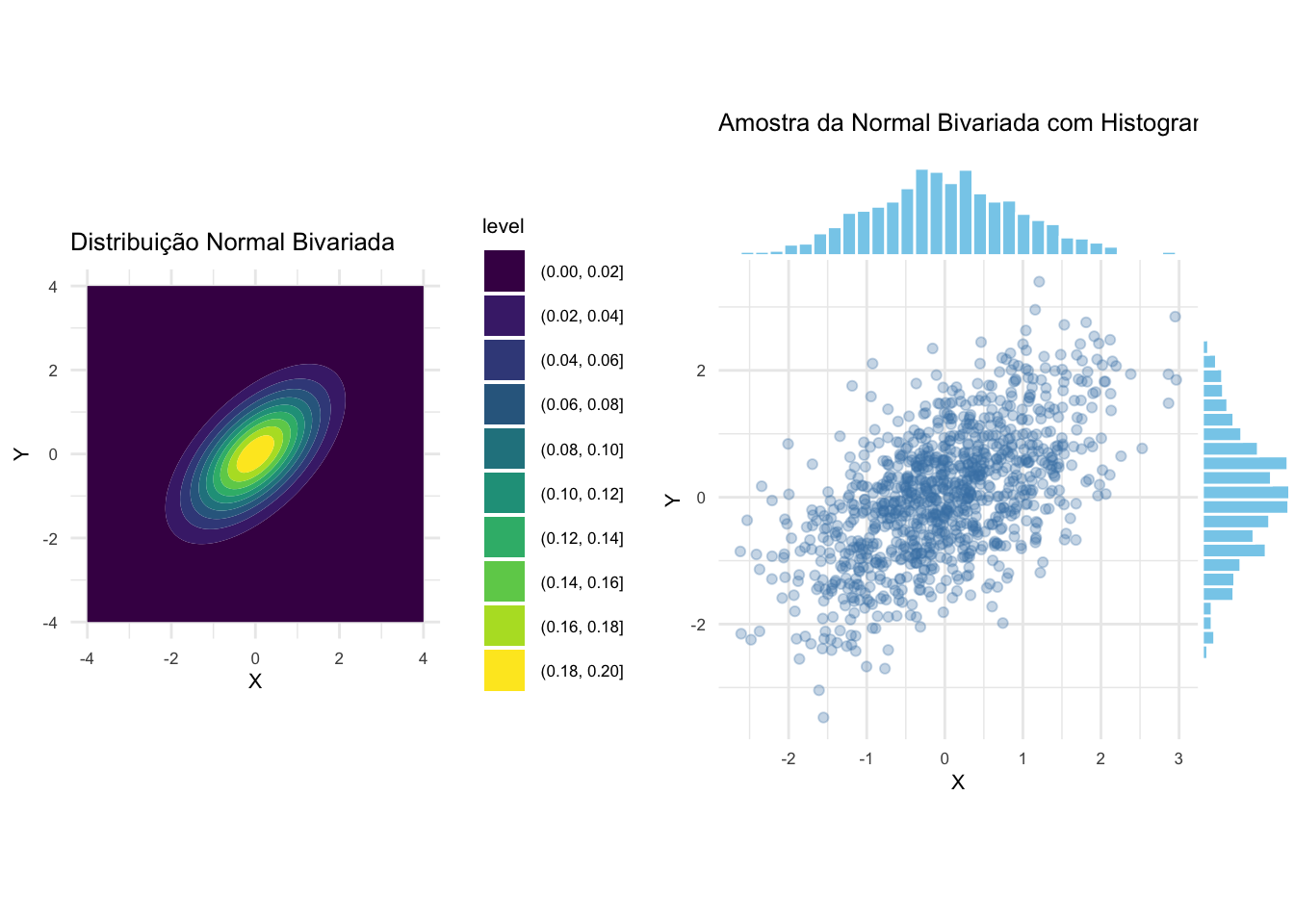
Figura 17.12: Distribuição normal bivariada e amostra simulada com histogramas marginais.
17.6 Distribuições multivariadas
17.6.1 O que são distribuições multivariadas?
Distribuições multivariadas descrevem a probabilidade conjunta de duas ou mais variáveis aleatórias.REF?
Exemplos de distribuições multivariadas incluem a distribuição normal multivariada, a distribuição t multivariada, a distribuição binomial multinomial e a distribuição de Dirichlet.REF?
17.7 Parâmetros
17.7.1 O que são parâmetros?
Parâmetros são informações que definem um modelo teórico, como propriedades de uma coleção de indivíduos.135
Parâmetros definem características de uma população inteira, tipicamente não observados por ser inviável ter acesso a todos os indivíduos que constituem tal população.136
O pacote base31 fornece a função summary para calcular diversos parâmetros descritivos.
17.8 Tendência central
17.8.1 Que parâmetros de tendência central podem ser estimados?
\[\begin{equation} \tag{17.1} \bar{x} = \frac{\sum_{i=1}^{n} x_i}{n} \end{equation}\]
\[\begin{equation} \tag{17.2} \bar{x}_p = \frac{\sum_{i=1}^{n} w_i x_i}{\sum_{i=1}^{n} w_i} \end{equation}\]
\[\begin{equation} \tag{17.3} \bar{x}_g = \left( \prod_{i=1}^{n} x_i \right)^{\frac{1}{n}} \end{equation}\]
\[\begin{equation} \tag{17.4} \bar{x}_h = \frac{n}{\sum_{i=1}^{n} \frac{1}{x_i}} \end{equation}\]
\[\begin{equation} \tag{17.5} \tilde{x} = \begin{cases} x_{\left(\frac{n+1}{2}\right)}, & \text{se } n \text{ é ímpar} \\ \frac{x_{\left(\frac{n}{2}\right)} + x_{\left(\frac{n}{2} + 1\right)}}{2}, & \text{se } n \text{ é par} \end{cases} \end{equation}\]
- Moda (17.6), onde \(f(x)\) é a função de frequência absoluta ou relativa e \(x_1, x_2, \ldots, x_n\) são os valores observados.137,203,207
\[\begin{equation} \tag{17.6} \operatorname{Mo} \in \arg\max_{x \in \{x_1,\ldots,x_n\}} f(x) \end{equation}\]
- Moda (dados agrupados) (17.7), onde: \(L\) = limite inferior da classe modal; \(f_1\) = frequência da classe modal; \(f_0\) = frequência da classe anterior à classe modal; \(f_2\) = frequência da classe posterior à classe modal; \(h\) = amplitude da classe modal.
\[\begin{equation} \tag{17.7} \operatorname{Mo} = L + \frac{(f_1 - f_0)}{(f_1 - f_0) + (f_1 - f_2)} \cdot h \end{equation}\]
A posição relativa das medidas de tendência central (média, mediana e moda) depende da forma da distribuição.207
Em uma distribuição normal, as três medidas são idênticas.207
A média é sempre puxada para os valores extremos, por isso é deslocada para a cauda em distribuições assimétricas.207
A mediana fica entre a média e a moda em distribuições assimétricas.207
A moda é o valor mais frequente e, portanto, se localiza no pico da distribuição assimétrica.207
Uma distribuição pode uma moda (unimodal), duas modas (bimodal) ou três ou mais modas (multimodal), indicando a presença de mais de um valor com alta frequência.207
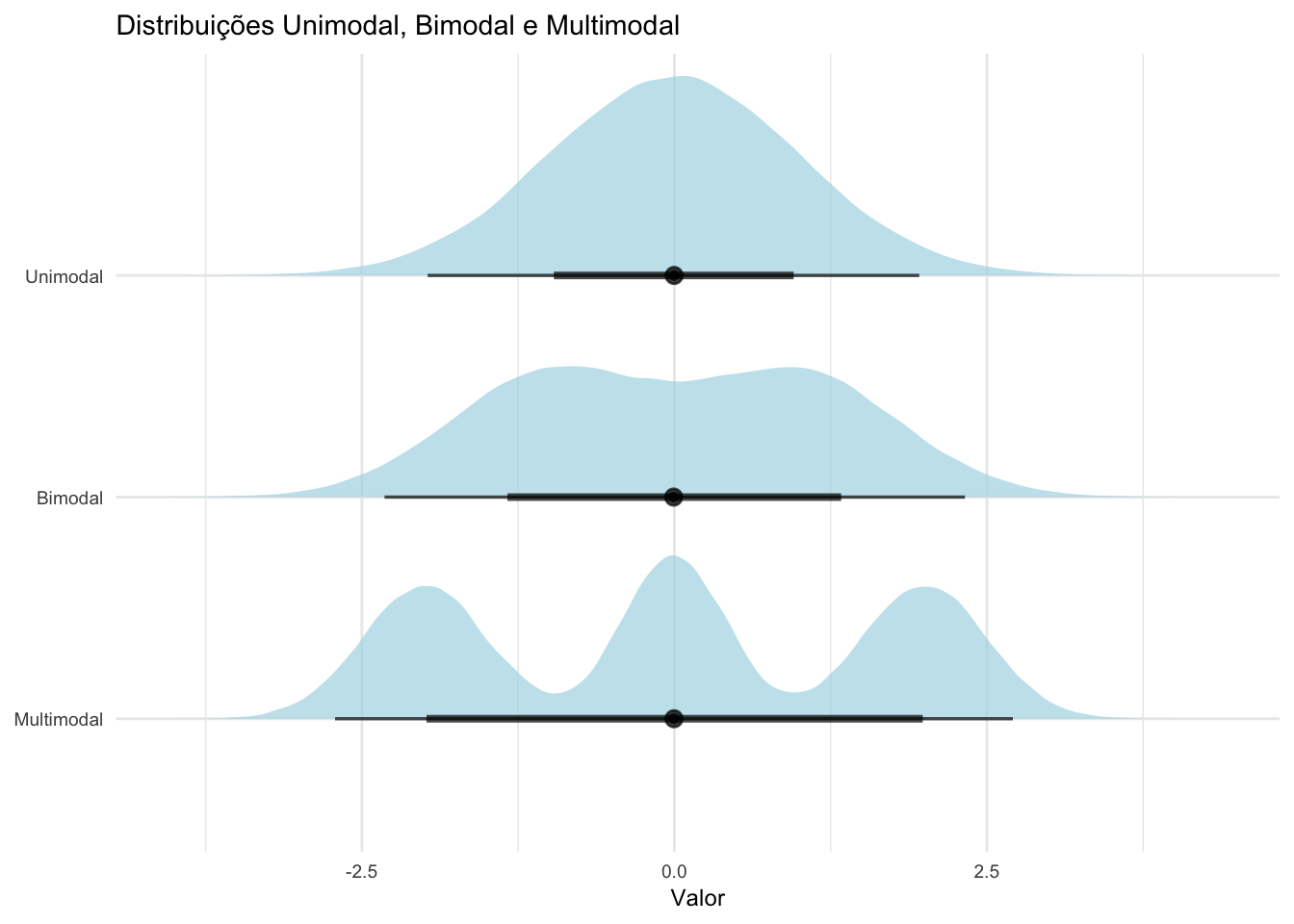
Figura 17.13: Distribuições unimodal, bimodal e multimodal.
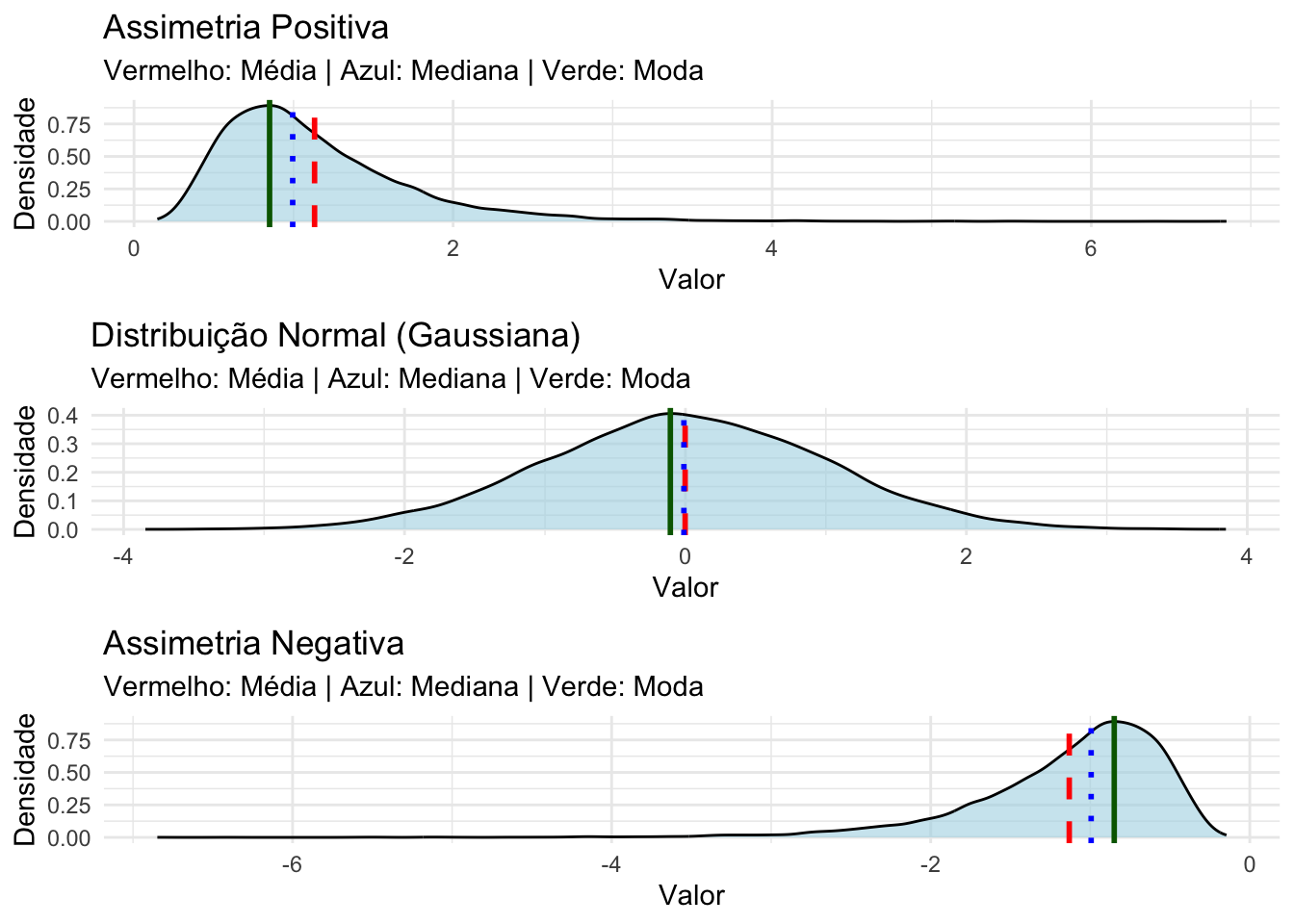
Figura 17.14: Parâmetros de tendência central em distribuições assimétricas e normais.
O pacote base31 fornece a função summary para calcular diversos parâmetros descritivos.
17.8.2 Como escolher o parâmetro de tendência central?
A mediana é preferida à média quando existem poucos valores extremos na distribuição, alguns valores são indeterminados, ou há uma distribuição aberta, ou os dados são medidos em uma escala ordinal.207
A moda é preferida quando os dados são medidos em uma escala nominal.207
A média geométrica é preferida quando os dados são medidos em uma escala logarítmica.207
17.9 Dispersão
17.9.1 Que parâmetros de dispersão podem ser estimados?
\[\begin{equation} \tag{17.8} s^2 = \frac{\sum_{i=1}^{n} (x_i - \bar{x})^2}{n-1} \end{equation}\]
\[\begin{equation} \tag{17.9} s = \sqrt{\frac{\sum_{i=1}^{n} (x_i - \bar{x})^2}{n-1}} \end{equation}\]
\[\begin{equation} \tag{17.10} A = x_{\max} - x_{\min} \end{equation}\]
\[\begin{equation} \tag{17.11} IQR = Q_3 - Q_1 \end{equation}\]
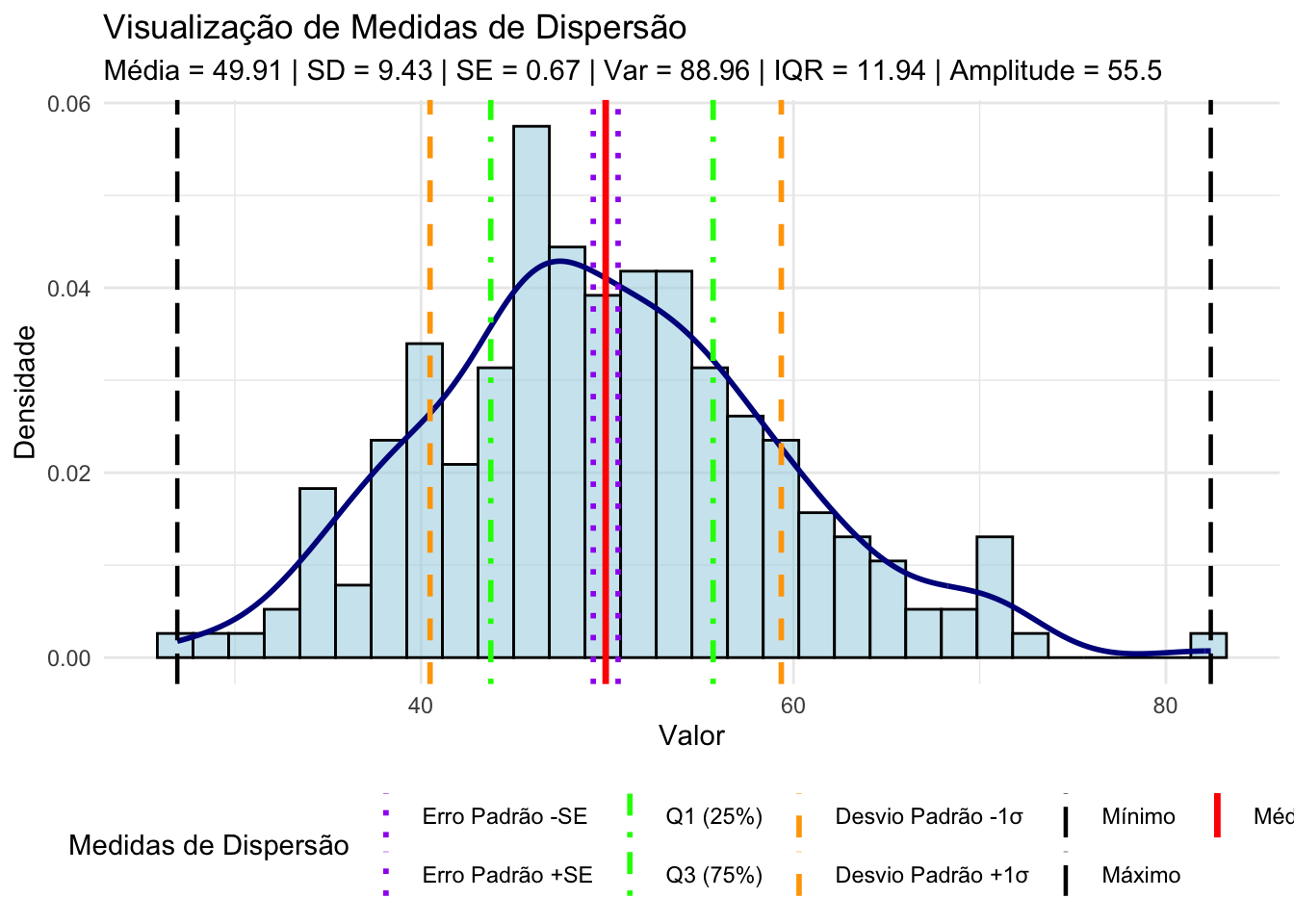
Figura 17.15: Parâmetros de dispersão em distribuições normais.
O pacote base31 fornece a função summary para calcular diversos parâmetros descritivos.
O pacote stats159 fornece a função confint para calcular o intervalo de confiança em um nível de significância \(\alpha\).
17.9.2 Como escolher o parâmetro de dispersão?
Desvio-padrão \(\sigma\) é apropriado quando a média é utilizada como parâmetro de tendência central em distribuições simétricas.209
Amplitude ou intervalo interquartil são apropriadas para variáveis ordinais ou distribuições assimétricas.209
17.9.3 O que é a correção de Bessel para variância?
Correção de Bessel é um ajuste feito no denominador da fórmula de variância da amostra — ou seja, o número de graus de liberdade — para evitar que a variância amostral seja menor do que a variância populacional.210
A correção de Bessel é feita subtraindo-se 1 do número de observações da amostra, ou seja, \(n - 1\) (17.12).210
\[\begin{equation} \tag{17.12} s^2 = \frac{\sum_{i=1}^{n} (x_i - \bar{x})^2}{n-1} \end{equation}\]
17.9.4 Por que a correção de Bessel para variância é importante?
A correção de Bessel é importante porque a variância amostral tende a ser menor do que a variância populacional, especialmente em amostras pequenas.210
A correção de Bessel ajuda a garantir que a variância amostral seja uma estimativa mais precisa da variância populacional, o que é fundamental para a validade dos testes estatísticos e das inferências feitas a partir da amostra.210
17.10 Proporção
17.10.1 Que parâmetros de proporção podem ser estimados?
\[\begin{equation} \tag{17.13} f_i = n_i \end{equation}\]
\[\begin{equation} \tag{17.14} fr_i = \frac{n_i}{N} \end{equation}\]
- Percentil (17.15), onde \(k\) é o percentil desejado (0 a 100) e \(n\) é o número total de observações na amostra.137,203,205
\[\begin{equation} \tag{17.15} P_k = x_{\left(\frac{k}{100} \cdot (n+1)\right)} \end{equation}\]
Quantil: é o ponto de corte que define a divisão da amostra em grupos de tamanhos iguais. Portanto, não se referem aos grupos em si, mas aos valores que os dividem:205
Tercil: 2 valores que dividem a amostra em 3 grupos de tamanhos iguais.205
Quartil: 3 valores que dividem a amostra em 4 grupos de tamanhos iguais.205
Quintil: 4 valores que dividem a amostra em 5 grupos de tamanhos iguais.205
Decil: 9 valores que dividem a amostra em 10 grupos de tamanhos iguais.205
O pacote base31 fornece a função summary para calcular diversos parâmetros descritivos.
O pacote base31 fornece a função table para calcular proporções.
O pacote stats31 fornece a função quantile para executar análise de percentis.
17.11 Extremos
17.12 Erro
17.12.1 Que parâmetros de erro podem ser estimados?
- Margem de erro (ME).(17.18).
\[\begin{equation} \tag{17.18} ME = z_{\alpha/2} \cdot \frac{\sigma}{\sqrt{n}} \end{equation}\]
\[\begin{equation} \tag{17.19} EPM = \frac{\sigma}{\sqrt{n}} \end{equation}\]
\[\begin{equation} \tag{17.20} \widehat{EPM} = \frac{s}{\sqrt{n}} \end{equation}\]
17.13 Distribuição
17.13.1 Que parâmetros de distribuição podem ser estimados?
\[\begin{equation} \tag{17.21} \gamma_1 = \frac{\frac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})^3}{\left(\frac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})^2\right)^{3/2}} \end{equation}\]
\[\begin{equation} \tag{17.22} \gamma_2 = \frac{\frac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})^4}{\left(\frac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})^2\right)^{2}} \end{equation}\]
\[\begin{equation} \tag{17.23} \kappa = \gamma_2 - 3 \end{equation}\]
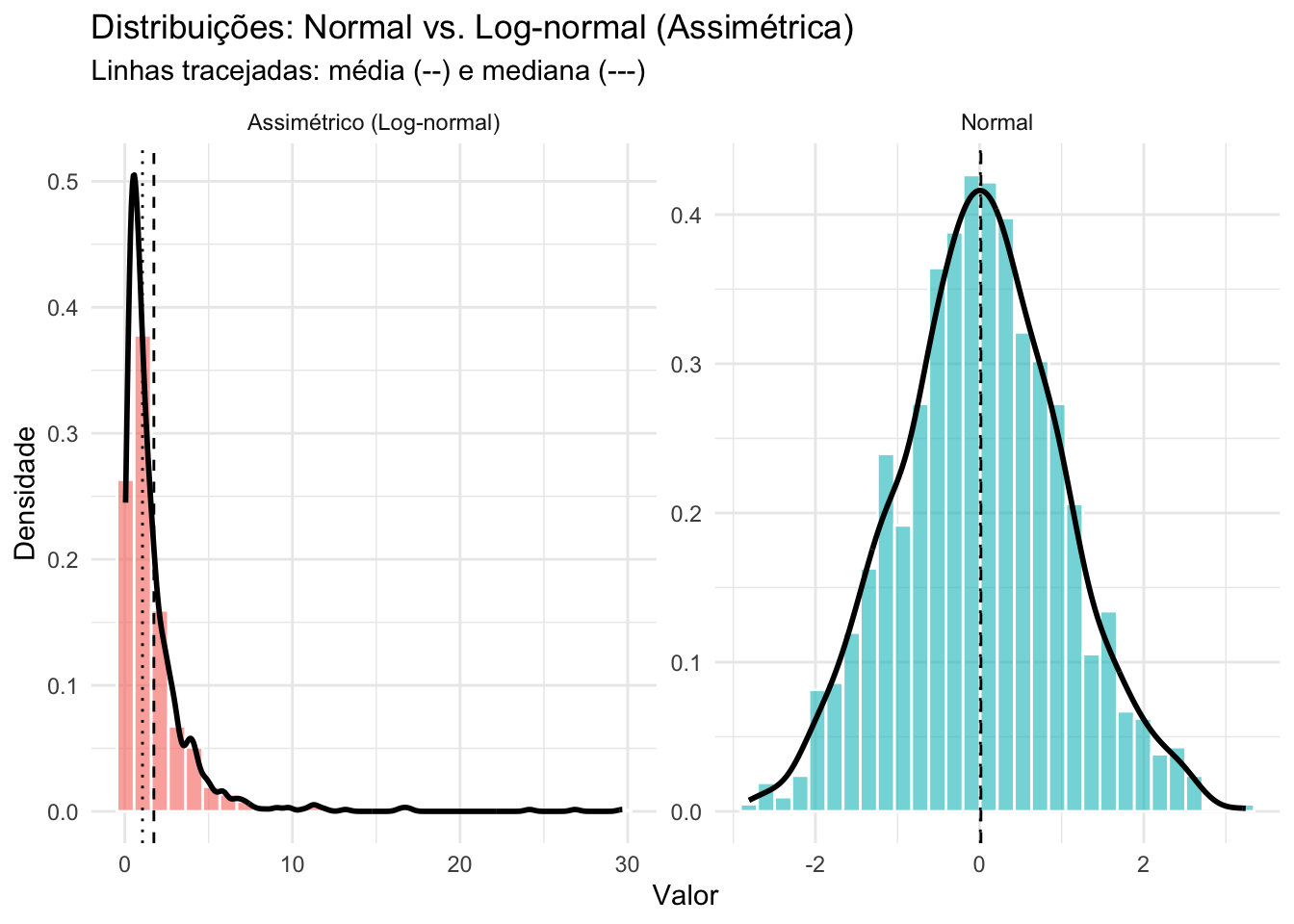
Figura 17.17: Parâmetros de distribuição: Assimetria e Curtose.
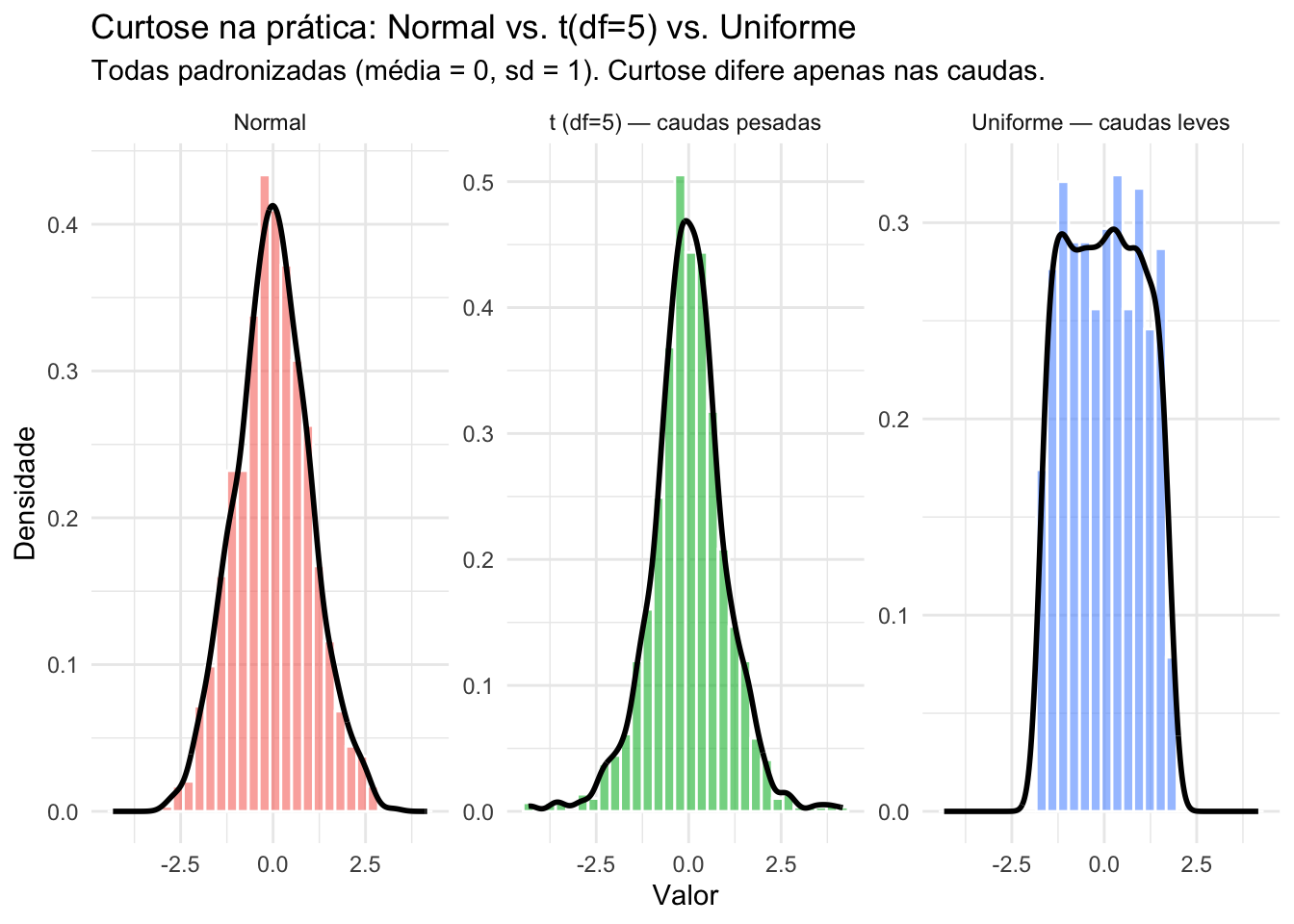
Figura 17.18: Parâmetros de distribuição: Curtose em distribuições simétricas (normal vs. uniforme).
17.14 Parâmetros robustos
17.14.1 O que são parâmetros robustos?
- Parâmetros robustos são medidas de posição e dispersão que permanecem estáveis mesmo na presença de valores discrepantes.211
17.14.2 Por que utilizar parâmetros robustos?
Parâmetros robustos garantem maior confiabilidade quando os dados não seguem a normalidade ou apresentam contaminação por outliers.211
Parâmetros robustos permitem análises mais estáveis em estudos exploratórios, evitando decisões equivocadas sobre variabilidade ou tendência central.211
17.14.3 O que é ponto de quebra?
- É a menor proporção de contaminação que pode levar o estimador a resultados arbitrariamente errados; quanto maior, mais robusto.212
17.14.4 Que parâmetros robustos podem ser estimados?
Média e variância Winsorizadas como opções intermediárias, reduzindo a influência dos outliers.211
Mediana, com \(~50%\) de ponto de quebra e função influência limitada.211,212
Median Absolute Deviation (MAD) (17.24), com correção 1,483 para normalidade, com \(~50%\) de ponto de quebra.211,212
\[\begin{equation} \tag{17.24} MAD = 1.483 \cdot \text{median}(|x_i - \text{median}(x)|) \end{equation}\]
\[\begin{equation} \tag{17.25} Qn = 2.2219 \cdot \text{first quartile}(|x_i - x_j|; i < j) \end{equation}\]
- O intervalo interquartil (\(IQR\)) (17.11) é robusto, com ponto de quebra \(~25%\), sendo simples de interpretar e útil em boxplots.212
Ferreira, Arthur de Sá. Ciência com R: Perguntas e respostas para pesquisadores e analistas de dados. Rio de Janeiro: 1a edição,