Capítulo 52 Inteligência artificial
52.2 Inteligência artificial explicável (eXplainable Artificial Intelligence, XAI)
52.2.1 O que é inteligência artificial explicável?
Explicabilidade: capacidade de revelar e resumir, em termos compreensíveis, os motivos por trás das decisões de um modelo, incluindo métodos post-hoc que explicam resultados após a predição.437
Interpretabilidade: capacidade de compreender o funcionamento interno do modelo a partir de suas próprias estruturas, por meio de técnicas intrínsecas que tornam o processo decisório inteligível.437
Transparência: geração de explicações claras e legíveis por humanos sobre as decisões do modelo, essencial para avaliar sua qualidade e resistir a usos adversariais.437
Equidade: capacidade do modelo de tomar decisões imparciais, sem favorecer ou discriminar grupos, mitigando vieses associados a características sociais, econômicas ou demográficas.437
Robustez: capacidade do modelo de manter desempenho estável diante de incertezas ou pequenas perturbações nos dados de entrada, incluindo ataques adversariais.437
Satisfação: grau em que técnicas de explicabilidade aumentam a utilidade, a usabilidade e a aceitação do sistema baseado em aprendizado de máquina.437
Estabilidade: capacidade de produzir explicações consistentes para entradas semelhantes, evitando variações arbitrárias nas interpretações.437
Responsabilidade: alinhamento do modelo a valores sociais, éticos e morais, sustentado por transparência, responsabilização, equidade e ética, como base para uma IA responsável.437
52.2.2 Por que explicar modelos de IA?
Para tornar as decisões defensáveis: compreender como e por que um modelo chega a determinado resultado é essencial para avaliar a legitimidade de suas decisões e sustentar seu uso em contextos críticos.438,439
Para tornar o sistema governável: explicações permitem enxergar o funcionamento interno do modelo, facilitando sua supervisão, auditoria, correção de erros e detecção de vieses ou fragilidades.438,439
Para aperfeiçoar o desempenho: ao revelar como o modelo utiliza informações, as explicações orientam ajustes que aumentam sua precisão, eficiência e robustez.438,439
Para ampliar o conhecimento: modelos explicáveis não apenas produzem previsões, mas também ajudam a identificar padrões, relações e hipóteses novas, contribuindo para a geração de conhecimento científico.438,439
O pacote keras440 possuu funções para criar, treinar e avaliar modelos de redes neurais.
O pacote tensorflow441 fornece uma interface para uma biblioteca de código aberto amplamente utilizada para aprendizado de máquina e redes neurais.
O pacote torch permite criar e treinar redes neurais com alto desempenho.
O pacote reticulate442 integra R e Python em um mesmo ambiente de trabalho, permitindo chamar funções Python a partir de R e facilitar o uso de bibliotecas de IA disponíveis nesse ecossistema.
52.3 Inteligência artificial generativa
52.3.2 Como funcionam modelos os grandes modelos de linguagem?
- .REF?
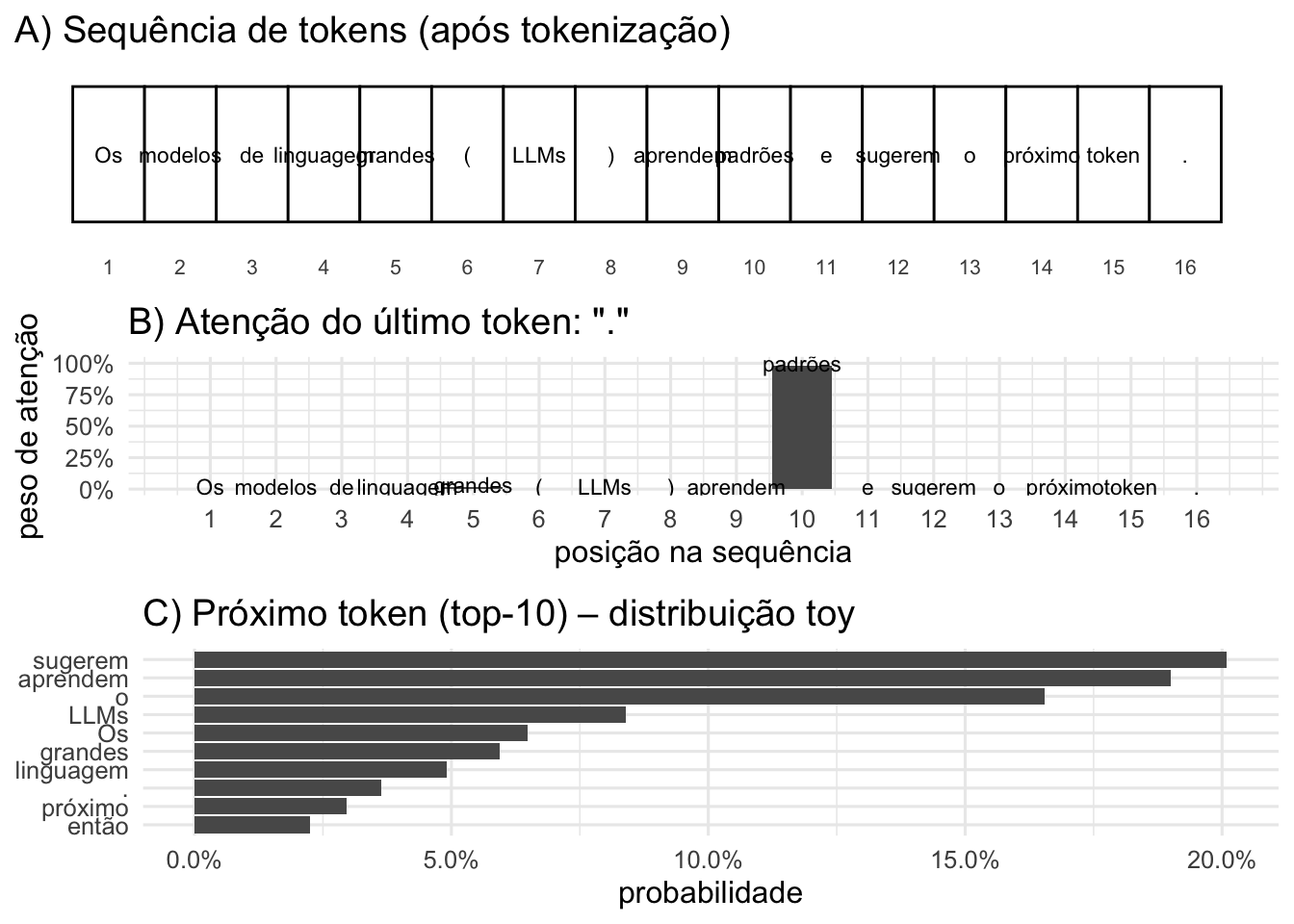
Figura 52.1: Representação esquemática de um modelo de linguagem grande (LLM)
52.4 Limitações fundamentais de modelos generativos
52.4.1 O que são alucinações em modelos generativos?
- Alucinações ocorrem quando um modelo produz saídas linguisticamente plausíveis, porém factualmente incorretas, inexistentes ou não verificáveis, sem que haja erro numérico ou falha no processo de treinamento.REF?
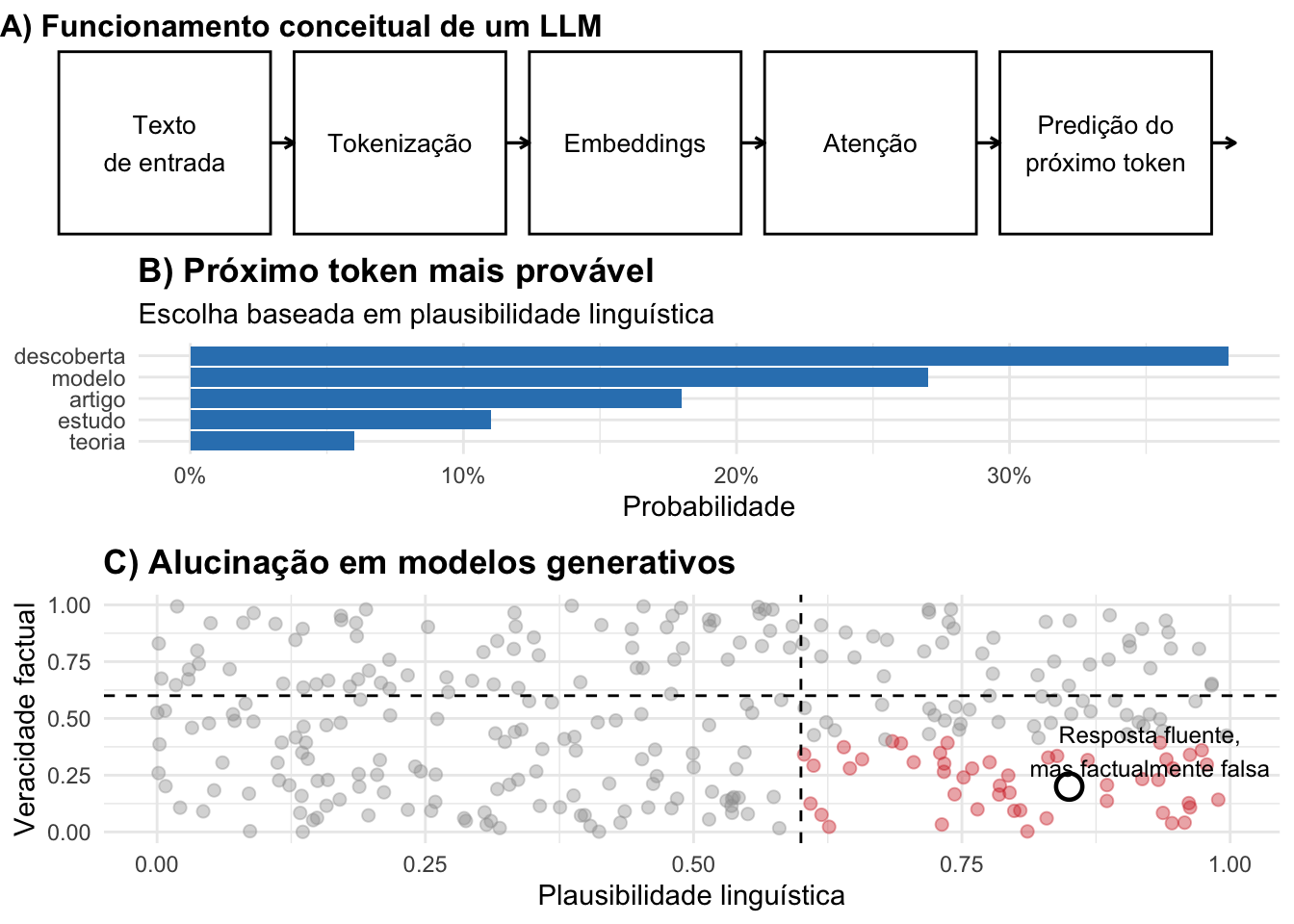
Figura 52.2: Funcionamento conceitual de modelos de linguagem e origem das alucinações. Painel A: Fluxo abstrato de um LLM até a predição do próximo token. Painel B: Escolha baseada em plausibilidade linguística. Painel C: Otimização probabilística pode gerar respostas fluentes, porém factualmente falsas.
52.4.2 Por que modelos generativos alucinam?
Modelos generativos são treinados para maximizar a probabilidade do próximo token dado um contexto, e não para verificar fatos ou manter correspondência com a realidade externa.REF?
O critério de otimização privilegia a verossimilhança estatística da linguagem, não a veracidade epistemológica do conteúdo.REF?
52.4.3 Alucinações indicam erro do modelo?
Alucinações não indicam que o modelo “aprendeu errado”, mas que ele aprendeu exatamente o que foi solicitado: produzir linguagem plausível, não conhecimento verdadeiro.REF?
Do ponto de vista matemático, uma resposta alucinatória pode ser ótima segundo a função de perda, mesmo sendo incorreta no mundo real.REF?
52.4.4 Qual a diferença entre erro estatístico e alucinação?
Erros estatísticos decorrem de limitações de generalização, ruído nos dados ou inadequação do modelo ao problema.REF?
Alucinações decorrem da ausência de mecanismos internos de checagem factual e constituem um fenômeno semântico e comunicacional, não um erro numérico.REF?
52.4.5 Quais tipos de alucinação são mais comuns?
Alucinação factual: afirmação de fatos inexistentes ou incorretos.REF?
Alucinação de fonte: citação de autores, artigos ou documentos inexistentes.REF?
Alucinação causal: inferência de relações de causa e efeito sem fundamento empírico.REF?
52.4.6 Por que alucinações são um problema prático?
- Porque a fluência linguística do modelo pode induzir confiança indevida em informações erradas, especialmente em contextos científicos, clínicos, jurídicos e educacionais.REF?
52.4.7 É possível eliminar completamente as alucinações?
Até o momento, não. Alucinações são uma consequência estrutural do paradigma generativo probabilístico e podem apenas ser mitigadas, não eliminadas.REF?
Estratégias como prompting controlado, ajuste de temperatura, recuperação de informações externas e validação pós-geração reduzem sua frequência, mas não suprimem o fenômeno.REF?
Ferreira, Arthur de Sá. Ciência com R: Perguntas e respostas para pesquisadores e analistas de dados. Rio de Janeiro: 1a edição,