Capítulo 11 Variáveis e fatores
11.1 Variáveis
11.1.1 O que são variáveis?
Variáveis são informações que podem variar entre medidas em diferentes indivíduos e/ou repetições.135
Variáveis definem características de uma amostra extraída da população, tipicamente observados por aplicação de métodos de amostragem (isto é, seleção) da população de interesse.136
11.1.2 Como são classificadas as variáveis?
Quanto ao conteúdo: contínua (intervalo ou discreta) ou categórica (ordinal ou nominal).136–140
Quanto à interpretação: dependente (desfecho); independente (preditora, covariável, confundidora, controle); moderadora (interação); mediadora; auxiliar; indicadora; latente.136–139
O pacote base31 fornece a função class para identificar qual é o tipo do objeto.
O pacote base31 fornece as funções as.numeric e as.character para criar objetos numéricos e categóricos, respectivamente.
O pacote base31 fornece as funções as.Date e as.logical para criar objetos em formato de data e lógicos (VERDADEIRO, FALSO), respectivamente.
11.2 Transformação de variáveis
11.2.1 Por que é importante classificar as variáveis?
- Identificar corretamente os tipos de variáveis da pesquisa é uma das etapas da escolha dos métodos estatísticos adequados para as análises e representações no texto, tabelas e gráficos.138
11.2.2 O que é transformação de variáveis?
Transformação significa aplicar uma função matemática à variável medida em sua unidade original.141
A transformação visa atender aos pressupostos dos modelos estatísticos quanto à distribuição da variável, em geral a distribuição gaussiana.136,141
A dicotomização pode ser interpretada como um caso particular de agrupamento.142
11.2.3 Por que transformar variáveis?
Muitos procedimentos estatísticos supõem que as variáveis (ou seus termos de erro, mais especificamente) são normalmente distribuídas. A violação dessa suposição pode aumentar suas chances de cometer um erro do tipo I ou II.143
Mesmo quando se está usando análises consideradas robustas para violações dessas suposições ou testes não paramétricos (que não assumem explicitamente termos de erro normalmente distribuídos), atender a essas questões pode melhorar os resultados das análises.143
11.2.4 Quais transformações de variáveis podem ser aplicadas?
- Distribuições com assimetria à direita: raiz quadrada, logaritmo natural, logaritmo base 10, transformação inversa.143
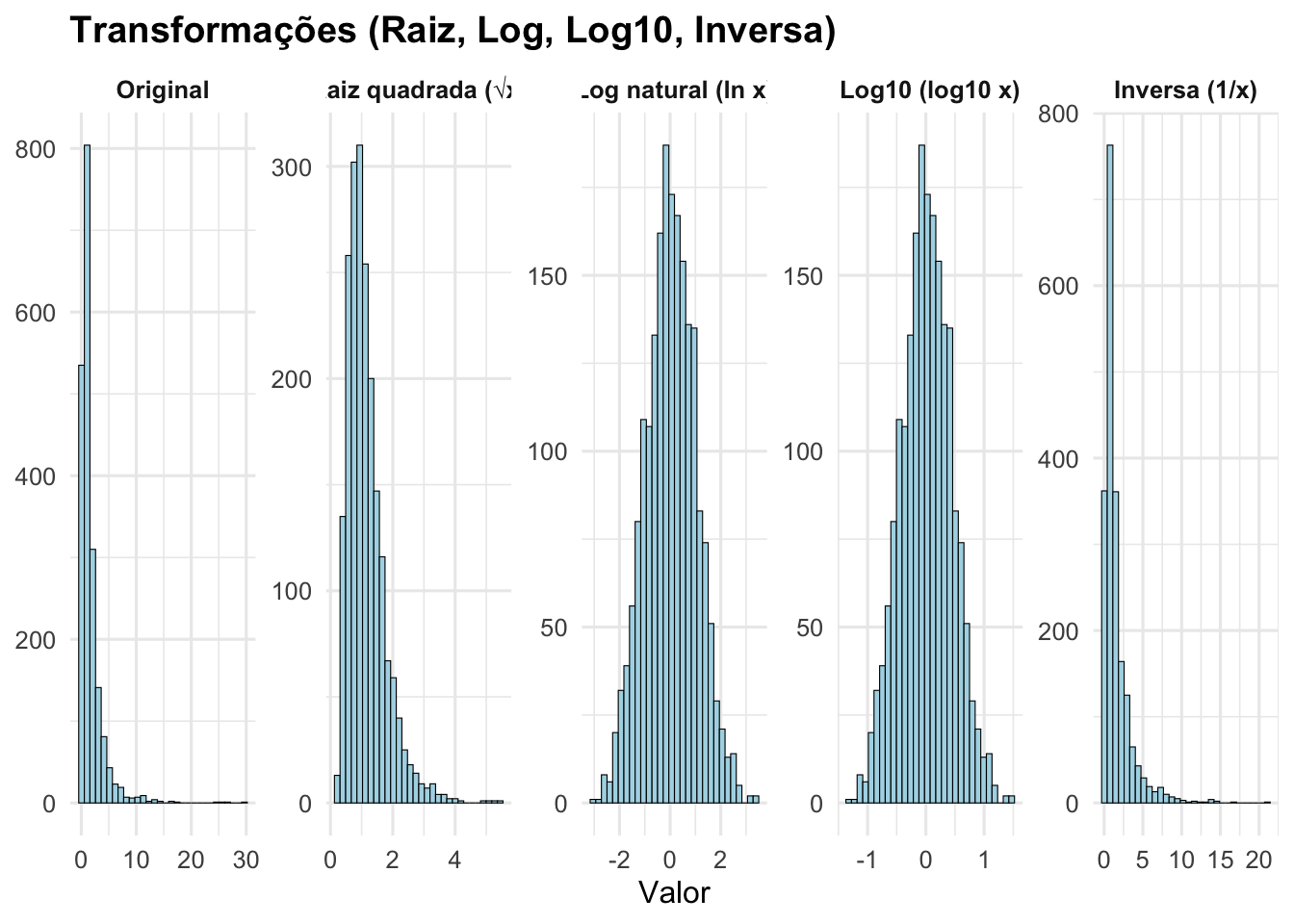
Figura 11.1: Transformações de variáveis com assimetria à direita (Original, Raiz quadrada, Log natural, Log10, Inversa).
- Distribuições com assimetria à esquerda: reflexão e raiz quadrada, reflexão e logaritmo natural, reflexão e logaritmo base 10, reflexão e transformação inversa.143
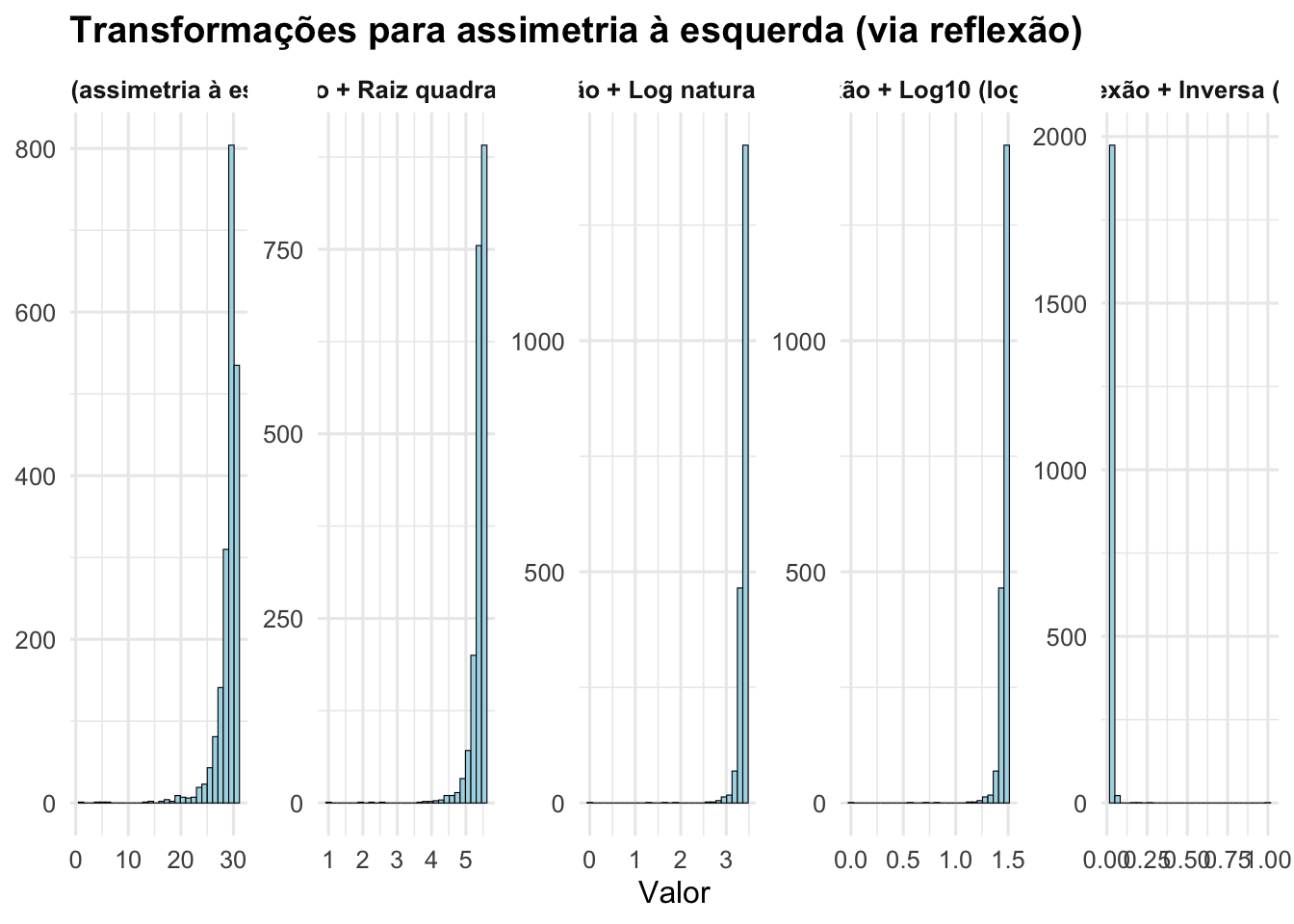
Figura 11.2: Transformações de variáveis com assimetria à esquerda (Original, Reflexão + Raiz quadrada, Reflexão + Log natural, Reflexão + Log10, Reflexão + Inversa).
\[\begin{equation} \tag{11.1} Z = \frac{1}{2} \ln\left(\frac{1 + r}{1 - r}\right) \end{equation}\]
\[\begin{equation} \tag{11.2} Y(\lambda) = \begin{cases} \frac{Y^{\lambda} - 1}{\lambda}, & \text{se } \lambda \neq 0 \\ \ln(Y), & \text{se } \lambda = 0 \end{cases} \end{equation}\]
\[\begin{equation} \tag{11.3} Y' = \arcsin(\sqrt{Y}) \end{equation}\]
Diferenciação.
Categorização.
Dicotomização.
11.3 Centralização de variáveis
11.3.1 O que é centralização de variáveis?
- É uma transformação linear em que se subtrai a média da variável de cada observação. O objetivo é recentrar a variável em torno de zero, sem alterar a sua variabilidade.REF?
11.4 Padronização de variáveis
11.4.1 O que é padronização de variáveis?
- Padronização é a transformação de uma variável contínua para uma escala comum, permitindo comparações entre variáveis medidas em diferentes unidades ou magnitudes.REF?
11.4.2 Por que padronizar variáveis?
Facilita a interpretação em análises multivariadas.REF?
Evita que variáveis em escalas maiores dominem os resultados de algoritmos que dependem de distância.REF?
Melhora a comparabilidade entre estudos e bases de dados diferentes.REF?
11.4.3 Quais são os métodos de padronização mais comuns?
\[\begin{equation} \tag{11.4} Z = \frac{X - \mu}{\sigma} \end{equation}\]
\[\begin{equation} \tag{11.5} X_{norm} = \frac{X - X_{min}}{X_{max} - X_{min}} \end{equation}\]
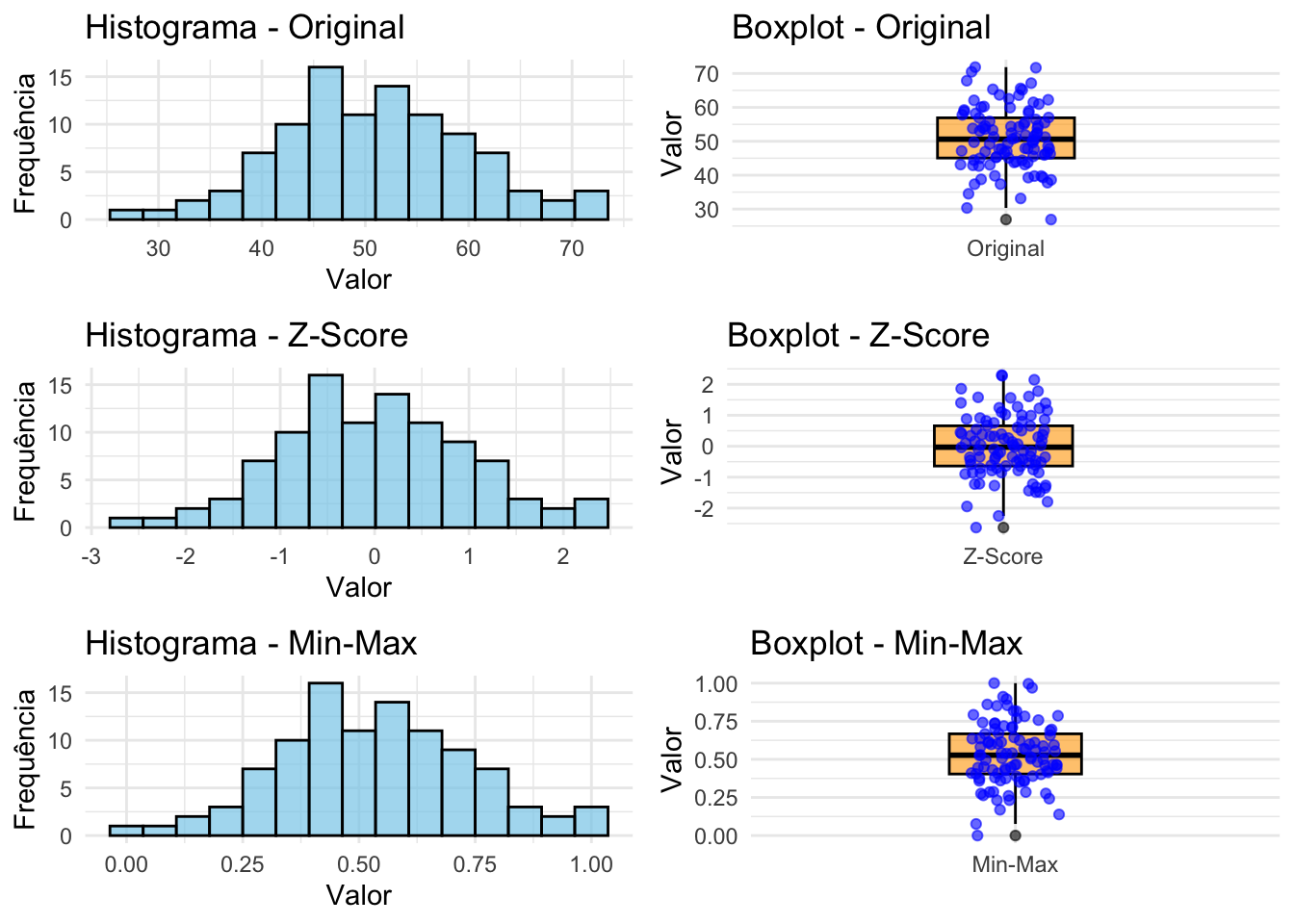
Figura 11.3: Comparação entre variáveis originais e padronizadas (Z-score e Min-Max).
11.4.4 Quais são as melhores práticas de nomenclatura ao padronizar variáveis?
Usar sufixos como
_zou_stdpara indicar padronização (altura_z,peso_std).REF?Documentar no dicionário de dados como cada variável foi transformada.REF?
Evitar substituir a variável original: manter sempre a versão bruta e a padronizada.REF?
O pacote base31 fornece a função scale para calcular automaticamente a padronização (média = 0, desvio padrão = 1).
11.5 Categorização de variáveis contínuas
11.5.1 Por que não é recomendado categorizar variáveis contínuas?
Nenhum dos argumentos usados para defender a categorização de variáveis se sustenta sob uma análise técnica rigorosa.146
Categorizar variáveis não é necessário para conduzir análises estatísticas. Ao invés de categorizar, priorize as variáveis contínuas.147–149
Em geral, não existe uma justificativa racional (plausibilidade biológica) para assumir que as categorias artificiais subjacentes existam.147–149
Caso exista um ponto de corte ou limiar verdadeiro que discrimine três ou mais grupos independentes, identificar tal ponto de corte ainda é um desafio.150
Categorização de variáveis contínuas aumenta a quantidade de testes de hipótese para comparações pareadas entre os quantis, inflando, portanto, o erro tipo I.151
Categorização de variáveis contínuas requer uma função teórica que pressupõe a homogeneidade da variável dentro dos grupos, levando tanto a uma perda de poder como a uma estimativa imprecisa.151
Categorização de variáveis contínuas pode dificultar a comparação de resultados entre estudos devido aos pontos de corte baseados em dados de um banco usados para definir as categorias.151
O pacote questionr152 fornece a função irec para executar uma interface interativa para codificação de variáveis categóricas.
11.6 Dicotomização de variáveis contínuas
11.6.1 O que são variáveis dicotômicas?
Variáveis dicotômicas (ou binárias) podem representar categorias naturais tipo “presente/ausente”, “sim/não”.REF?
Variáveis dicotômicas podem representar categorias fictícias, criadas a partir de variáveis multinominais, em que cada nível é convertido em uma variável dicotômica indicatoda (dummy).REF?
Dicotomização é considerado um artefato da análise de dados, uma vez que é realizada após a coleta de dados.153
Geralmente são representadas por “1” (presente, sucesso) e “0” (ausente, falha).REF?
11.6.2 Quais argumentos defendem a dicotomização de variáveis contínuas?
O argumento principal para dicotomização de variáveis é que tal procedimento facilita e simplifica a apresentação dos resultados, principalmente para o público em geral.142
Os pesquisadores não conhecem as consequências estatísticas da dicotomização.146
Os pesquisadores não conhecem os métodos adequados de análise não-paramétrica, não-linear e robusta.146
As categorias representam características existentes dos participantes da pesquisa, de modo que as análises devam ser feitas por grupos e não por indivíduos.146
A confiabilidade da(s) variável(eis) medida(s) é baixa e, portanto, categorizar os participantes resultaria em uma medida mais confiável.146
11.6.3 Por que a dicotomização não é recomendada?
Nenhum dos argumentos usados para defender a dicotomização de variáveis se sustenta sob uma análise técnica rigorosa.146
Dicotomizar variáveis não é necessário para conduzir análises estatísticas. Ao invés de dicotomizar, priorize as variáveis contínuas.147–149
Em geral, não existe uma justificativa racional (plausibilidade biológica) para assumir que as categorias artificiais subjacentes existam.147–149
Dicotomização causa perda de informação e consequentemente perda de poder estatístico para detectar efeitos.146,147
Dicotomização também classifica indivíduos com valores próximos na variável contínua como indivíduos em pontos opostos e extremos, artificialmente sugerindo que são muito diferentes.147
Dicotomização pode diminuir a variabilidade das variáveis.147
Dicotomização pode ocultar não-linearidades presentes na variável contínua.146,147
A média ou a mediana, embora amplamente utilizadas, não são bons parâmetros para dicotomizar variáveis.142,147
Caso exista um ponto de corte ou limiar verdadeiro que discrimine dois grupos independentes, identificar tal ponto de corte ainda é um desafio.150
11.6.4 Quais cenários legitimam a dicotomização das variáveis contínuas?
Quando existem dados e/ou análises que suportem a existência — não apenas a suposição ou teorização — de categorias com um ponto de corte claro e com significado entre elas.146
Quando a distribuição da variável contínua é muito assimétrica, de modo que uma grande quantidade de observações está em um dos extremos da escala.146
11.6.5 Quais métodos são usados para dicotomizar variáveis contínuas?
Em termos de tabelas de contingência 2x2, os seguintes métodos permitem150 a identificação do limiar verdadeiro:
11.7 Representação de variáveis categóricas
11.7.1 O que são variáveis indicadoras (dummy variables)?
Variáveis indicadoras são variáveis dicotômicas criadas a partir dos níveis de um fator.REF?
Cada variável indicadora assume o valor \(1\) quando a observação pertence àquela categoria e \(0\) caso contrário.REF?
Variáveis indicadoras não representam magnitude ou ordem, apenas a presença ou ausência de uma categoria.REF?
| ID | Sexo | Grupo | Sexo_Feminino | Grupo_TratA | Grupo_TratB |
|---|---|---|---|---|---|
| 1 | Masculino | Tratamento A | 1 | 1 | 0 |
| 2 | Masculino | Controle | 1 | 0 | 0 |
| 3 | Masculino | Tratamento A | 1 | 1 | 0 |
| 4 | Feminino | Tratamento B | 0 | 0 | 1 |
| 5 | Masculino | Controle | 1 | 0 | 0 |
| 6 | Feminino | Tratamento B | 0 | 0 | 1 |
| 7 | Feminino | Tratamento B | 0 | 0 | 1 |
| 8 | Feminino | Controle | 0 | 0 | 0 |
| 9 | Masculino | Controle | 1 | 0 | 0 |
| 10 | Masculino | Controle | 1 | 0 | 0 |
| 11 | Feminino | Controle | 0 | 0 | 0 |
| 12 | Feminino | Tratamento B | 0 | 0 | 1 |
O pacote stats159 fornece a função model.matrix para expandir variáveis categóricas em variáveis indicadoras.
11.7.2 Por que variáveis indicadoras são importantes?
Permitem a inclusão de fatores em modelos estatísticos.REF?
Tornam explícitas as comparações entre categorias.REF?
Garantem coerência matemática sem perder o significado conceitual das categorias.REF?
11.7.3 Quantas variáveis indicadoras são necessárias para um fator?
Um fator com k níveis é representado por \(k − 1\) variáveis indicadoras.REF?
O nível que não gera uma variável indicadora explícita é chamado de nível de referência.REF?
11.7.4 O que é o nível de referência?
O nível de referência é a categoria usada como base de comparação para as demais.REF?
Os coeficientes associados às variáveis indicadoras representam diferenças em relação a esse nível de referência.REF?
11.7.5 Por que não se usam \(k\) variáveis indicadoras para \(k\) níveis?
Utilizar \(k\) variáveis indicadoras gera redundância perfeita entre as variáveis.REF?
Essa redundância causa problemas de identificabilidade nos modelos, fenômeno conhecido como dummy trap.REF?
11.7.6 Variáveis indicadoras são uma forma de dicotomização?
Variáveis indicadoras são dicotômicas, mas não resultam da dicotomização de variáveis contínuas.REF?
Variáveis indicadoras são criadas a partir de variáveis categóricas multinominais, preservando toda a informação original do fator.REF?
Variáveis indicadoras não reduzem informação, enquanto a dicotomização de variáveis contínuas descarta informação por construção.REF?
11.8 Fatores
11.8.1 O que são fatores?
Na modelagem, fator é sinônimo de variável preditora, em particular quando se refere à modelagem de efeitos fixos e aleatórios – os fatores (variáveis) são fatores fixos ou fatores aleatórios.REF?
Fatores são variáveis controladas pelos pesquisadores em um experimento para determinar seu efeito na(s) variável(ies) de resposta. Um fator pode assumir apenas um pequeno número de valores, conhecidos como níveis. Os fatores podem ser uma variável categórica ou baseados em uma variável contínua, mas usam apenas um número limitado de valores escolhidos pelos experimentadores.REF?
O pacote base31 fornece a função as.factor para converter uma variável em fator.
11.8.2 O que são níveis de um fator?
- Níveis de um fator são as possíveis categorias que descrevem um fator.REF?
O pacote base31 fornece as funções levels e nlevels para listar os níveis e a quantidade deles em um fator.
Ferreira, Arthur de Sá. Ciência com R: Perguntas e respostas para pesquisadores e analistas de dados. Rio de Janeiro: 1a edição,