Capítulo 25 Análise exploratória de dados
25.1 Análise exploratória de dados
25.1.1 O que é análise exploratória de dados?
Análise exploratória de dados consiste em um processo iterativo de elaboração e interpretação da síntese de dados, tabelas e gráficos, considerando os aspectos teóricos do estudo.274
Análise exploratória deve ser separada da análise inferencial de testes de hipóteses; a decisão sobre os modelos a testar deve ser feita a priori.286
25.1.2 Quais são os objetivos centrais da análise exploratória de dados?
A análise exploratória de dados (EDA) tem dois objetivos principais: (a) descrição dos dados e (b) formulação de modelos.273
A descrição envolve resumir os dados e destacar características essenciais.273
A formulação de modelos auxilia na geração de hipóteses e na escolha de procedimentos estatísticos adequados.273
25.1.3 Por que conduzir a análise exploratória de dados?
A condução de análise exploratória de dados pode ajudar a identificar padrões e pode orientar trabalhos futuros, mas os resultados não devem ser interpretados como inferências sobre uma população.286
A análise exploratória não deve ser usada para definir as questões e hipóteses científicas do estudo.286
O pacote explore278 fornece a função explore para análise exploratória de um banco de dados.
O pacote dataMaid279 fornece a função makeDataReport para criar um relatório de análise exploratória de um banco de dados.
O pacote DataExplorer280 fornece a função create_report para criar um relatório de análise exploratória de um banco de dados.
O pacote SmartEDA281 fornece a função ExpReport para criar um relatório de análise exploratória de um banco de dados.
O pacote gtExtras287 fornece a função gt_plt_summary para criar uma tabela descritiva síntese com histogramas ou gráficos de barra a partir de um banco de dados.
O pacote radiant288 fornece a função radiant para executar uma interface interativa para análise exploratória de dados.
25.2 Quarteto de Anscombe
25.2.1 O que é o Quarteto de Anscombe?
O Quarteto de Anscombe é um conjunto de quatro bancos de dados bivariados criado para demonstrar a importância da visualização gráfica na análise estatística.289
O conjunto de dados mostra que medidas numéricas isoladas podem ocultar padrões relevantes, outliers e estruturas não lineares.289
| ID | x1 | x2 | x3 | x4 | y1 | y2 | y3 | y4 |
|---|---|---|---|---|---|---|---|---|
| 1 | 10 | 10 | 10 | 8 | 8.04 | 9.14 | 7.46 | 6.58 |
| 2 | 8 | 8 | 8 | 8 | 6.95 | 8.14 | 6.77 | 5.76 |
| 3 | 13 | 13 | 13 | 8 | 7.58 | 8.74 | 12.74 | 7.71 |
| 4 | 9 | 9 | 9 | 8 | 8.81 | 8.77 | 7.11 | 8.84 |
| 5 | 11 | 11 | 11 | 8 | 8.33 | 9.26 | 7.81 | 8.47 |
| 6 | 14 | 14 | 14 | 8 | 9.96 | 8.10 | 8.84 | 7.04 |
| 7 | 6 | 6 | 6 | 8 | 7.24 | 6.13 | 6.08 | 5.25 |
| 8 | 4 | 4 | 4 | 19 | 4.26 | 3.10 | 5.39 | 12.50 |
| 9 | 12 | 12 | 12 | 8 | 10.84 | 9.13 | 8.15 | 5.56 |
| 10 | 7 | 7 | 7 | 8 | 4.82 | 7.26 | 6.42 | 7.91 |
| 11 | 5 | 5 | 5 | 8 | 5.68 | 4.74 | 5.73 | 6.89 |
- Embora os quatro conjuntos apresentem estatísticas descritivas e modelos de regressão praticamente idênticos, seus gráficos de dispersão revelam relações completamente diferentes entre as variáveis.289
| X1Y1 | X2Y2 | X3Y3 | X4Y4 | |
|---|---|---|---|---|
| Observações | 11.00 | 11.00 | 11.00 | 11.00 |
| Média x | 9.00 | 9.00 | 9.00 | 9.00 |
| Média y | 7.50 | 7.50 | 7.50 | 7.50 |
| Variância x | 11.00 | 11.00 | 11.00 | 11.00 |
| Variância y | 4.13 | 4.13 | 4.12 | 4.12 |
| Correlação | 0.82 | 0.82 | 0.82 | 0.82 |
| Coeficiente angular | 0.50 | 0.50 | 0.50 | 0.50 |
| Coeficiente linear | 3.00 | 3.00 | 3.00 | 3.00 |
| Coeficiente de determinação | 0.67 | 0.67 | 0.67 | 0.67 |
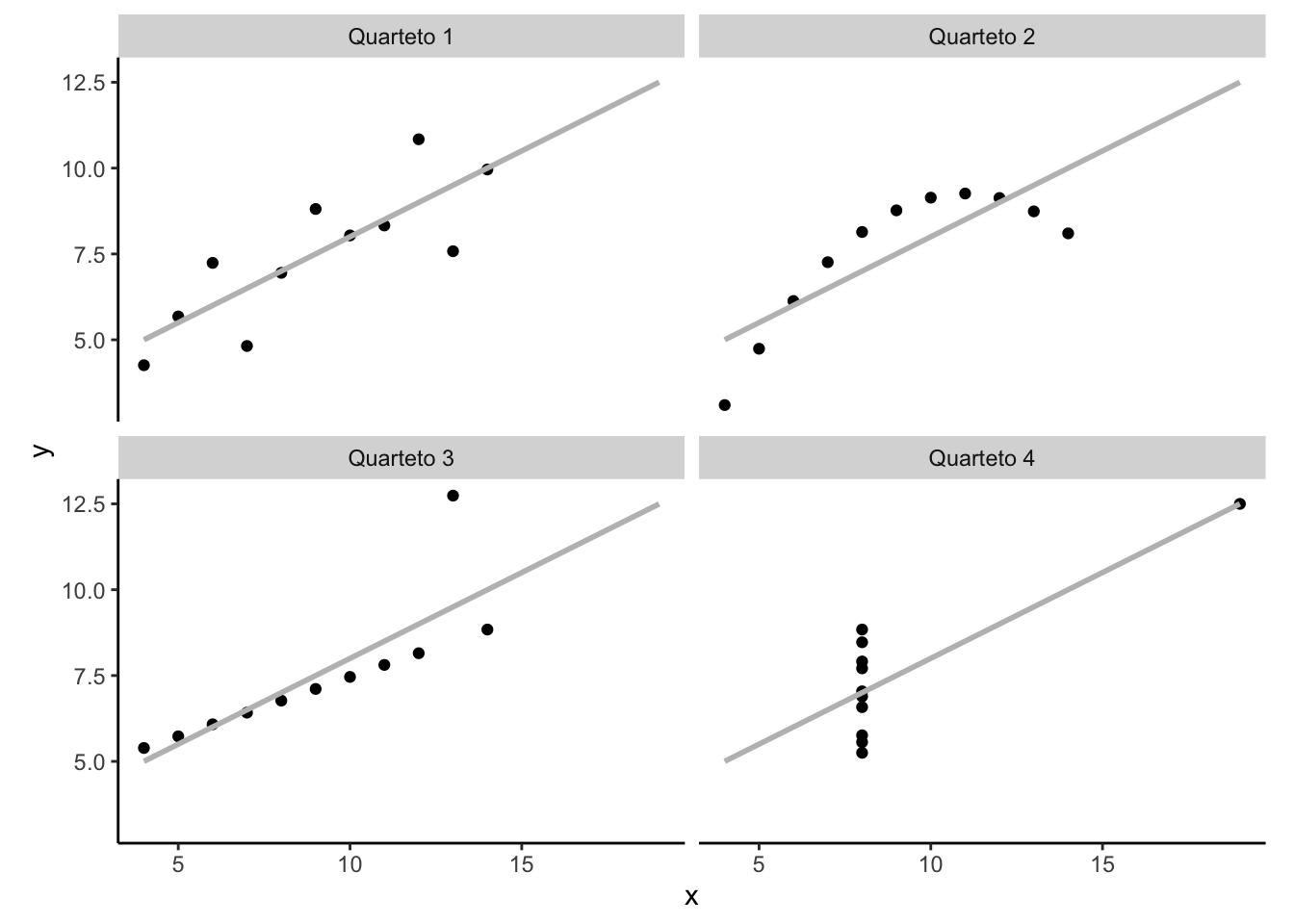
Figura 25.1: Gráfico de dispersão do Quarteto de Anscombe para representação gráfica de conjuntos de dados bivariados com parâmetros quase idênticos e relações muito distintas.
O pacote anscombiser290 fornece a função anscombise para gerar bancos de dados que compartilham os mesmos valores de parâmetros do Quarteto de Anscombe.
25.3 Ingredientes da análise exploratória de dados
25.3.1 Quais são os principais elementos que compõem a análise exploratória de dados?
Verificação da qualidade dos dados (erros, ausências, outliers).273
Representações gráficas como histogramas, diagramas de dispersão, boxplots e gráficos de séries temporais.273
Cálculo de estatísticas descritivas (média, desvio-padrão, intervalos, correlações).273
Técnicas multivariadas exploratórias, como análise de componentes principais e análise de clusters, podem revelar padrões em dados complexos.273
25.3.2 Quais etapas constituem a análise exploratória de dados?
Cada combinação de problema de pesquisa e delineamento de estudo pode demandar um plano de análise exploratório distinto.286
Verifique a existência e/ou influência de valores discrepantes (“fora da curva” ou outliers) com boxplots e gráficos quantil-quantil (Q-Q).273,274,286
A análise exploratória valoriza o uso de gráficos interativos e técnicas de brushing e linking, que permitem explorar padrões ocultos, relacionar múltiplas variáveis e destacar subconjuntos de observações.291
O pacote ggplot2199 fornece a função geom_boxplot para construção de gráficos boxplot.
Verifique a homoscedasticidade (homogeneidade da variância):286
Boxplots condicionais (por fator de análise)
Análise dos resíduos do modelo de regressão
Gráfico resíduos vs. valores ajustados
Verifique a normalidade da distribuição dos dados:273,286
Histograma das variáveis (por fator de análise)
Histograma dos resíduos da regressão
Verifique a existência de grande quantidade de valores nulos (=0):286
- Histograma das variáveis (por fator de análise)
Verifique a existência de colinearidade entre variáveis independentes de um modelo de regressão:286
Fator de inflação de variância (variance inflation factor, VIF)
Coeficiente de correlação de Pearson (\(r\))
Gráfico de dispersão entre variáveis
Verifique possíveis relações entre as variáveis dependente(s) e independente(s) de um modelo de regressão:286
- Gráfico de dispersão entre variáveis independente e dependente
Verifique possíveis interações entre as variáveis dependente(s) de um modelo de regressão:286
- Gráfico coplot de dispersão entre variáveis dependentes
O pacote ggcleveland292 fornece a função gg_coplot para construção de gráficos boxplot condicionais.
Medidas como mediana, trimean, distância absoluta mediana e procedimentos de winsorizing ou trimming são preferidos, pois reduzem a influência de valores extremos e oferecem resumos mais fiéis.291
A análise exploratória adota o esquema
dados = ajuste + resíduo, no qual o analista ajusta modelos provisórios, examina resíduos e refina os modelos em ciclos sucessivos de aproximação.291Valores discrepantes (outliers) não devem ser ignorados; eles podem indicar erros de coleta ou fenômenos relevantes.291
Transformar variáveis em novas formas (por exemplo, log ou inverso) pode revelar simetrias ocultas e tornar relações mais claras e lineares.291
Ferreira, Arthur de Sá. Ciência com R: Perguntas e respostas para pesquisadores e analistas de dados. Rio de Janeiro: 1a edição,