Capítulo 16 Dados perdidos e imputados
16.1 Dados perdidos
16.1.1 O que são dados perdidos?
- Dados perdidos são dados não coletados de um ou mais participantes, para uma ou mais variáveis.182
| id | Grupo | Idade | Sexo | Desfecho (pré) | Desfecho (pós) |
|---|---|---|---|---|---|
| 1 | Controle | 53 | F | 57.0 | 41.3 |
| 2 | Controle | 64 | F | 45.3 | 70.0 |
| 3 | Controle | 65 | M | 39.3 | NA |
| 4 | Intervenção | 66 | F | 47.8 | NA |
| 5 | Controle | 44 | M | 39.7 | 65.7 |
| 6 | Intervenção | NA | F | 42.7 | NA |
| 7 | Intervenção | 67 | M | 43.7 | 64.9 |
| 8 | Intervenção | NA | F | 33.1 | 63.3 |
| 9 | Controle | 68 | F | 58.4 | 61.6 |
| 10 | Controle | 74 | M | 51.5 | 54.3 |
O pacote base31 fornece a função is.na para identificar que elementos de um objeto são dados perdidos.
16.1.2 Qual o problema de um estudo ter dados perdidos?
Uma grande quantidade de dados perdidos pode comprometer a integridade científica do estudo, considerando-se que o tamanho da amostra foi estimado para observar um determinado tamanho de efeito mínimo.182
Perda de participantes no estudo por dados perdidos pode reduzir o poder estatístico (erro tipo II).182
Não existe solução globalmente satisfatória para o problema de dados perdidos.182
16.2 Mecanismos geradores de dados perdidos
16.2.1 Quais são os mecanismos geradores de dados perdidos?
- Dados perdidos completamente ao acaso (missing completely at random, MCAR), em que os dados perdidos estão distribuídos aleatoriamente nos dados da amostra.183,184
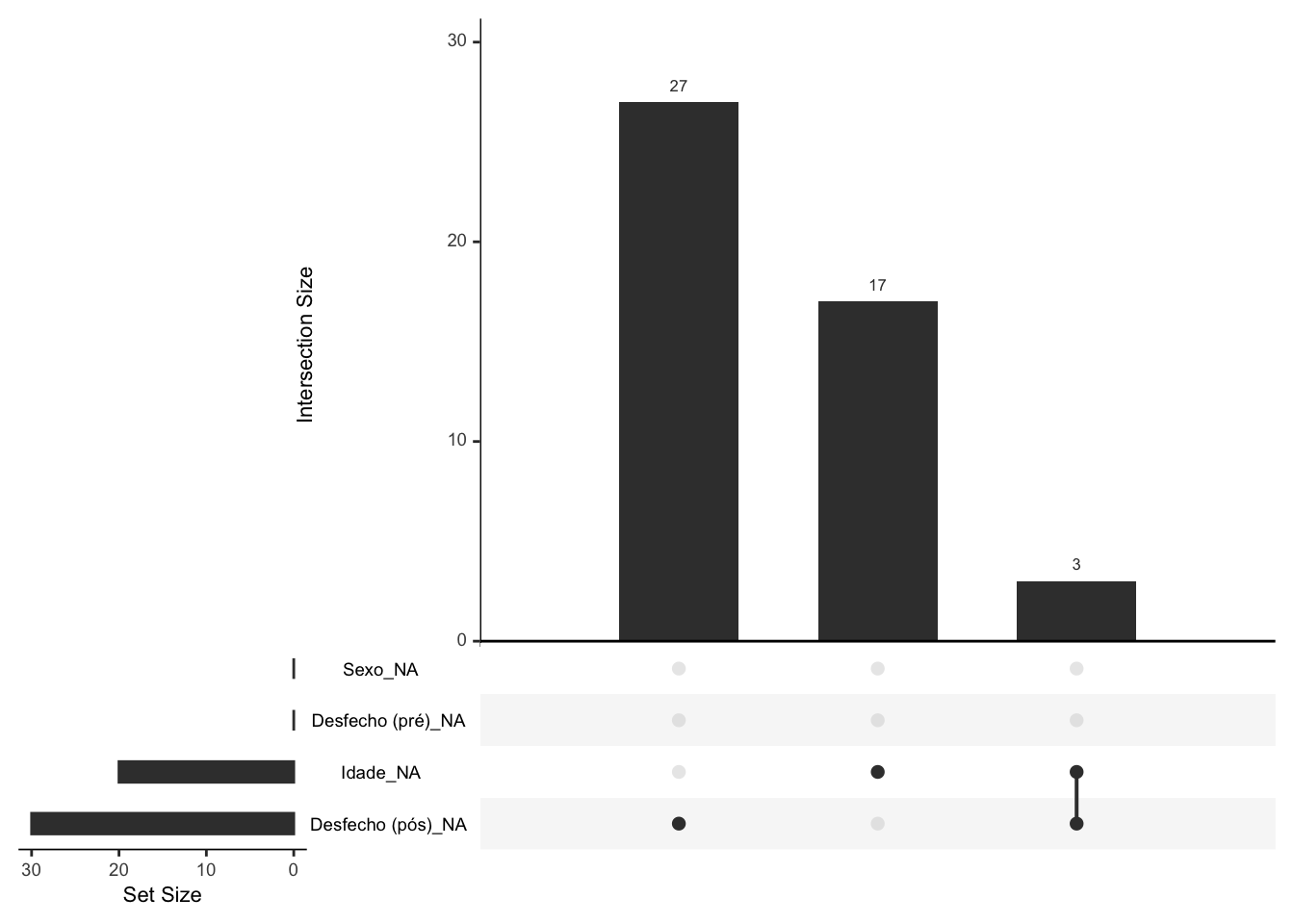
Figura 16.1: Representação gráfica de dados perdidos completamente ao acaso (MCAR) em um estudo randomizado controlado (RCT).
- Dados perdidos ao acaso (missing at random, MAR), em que a probabilidade de ocorrência de dados perdidos é relacionada a outras variáveis medidas.183,184
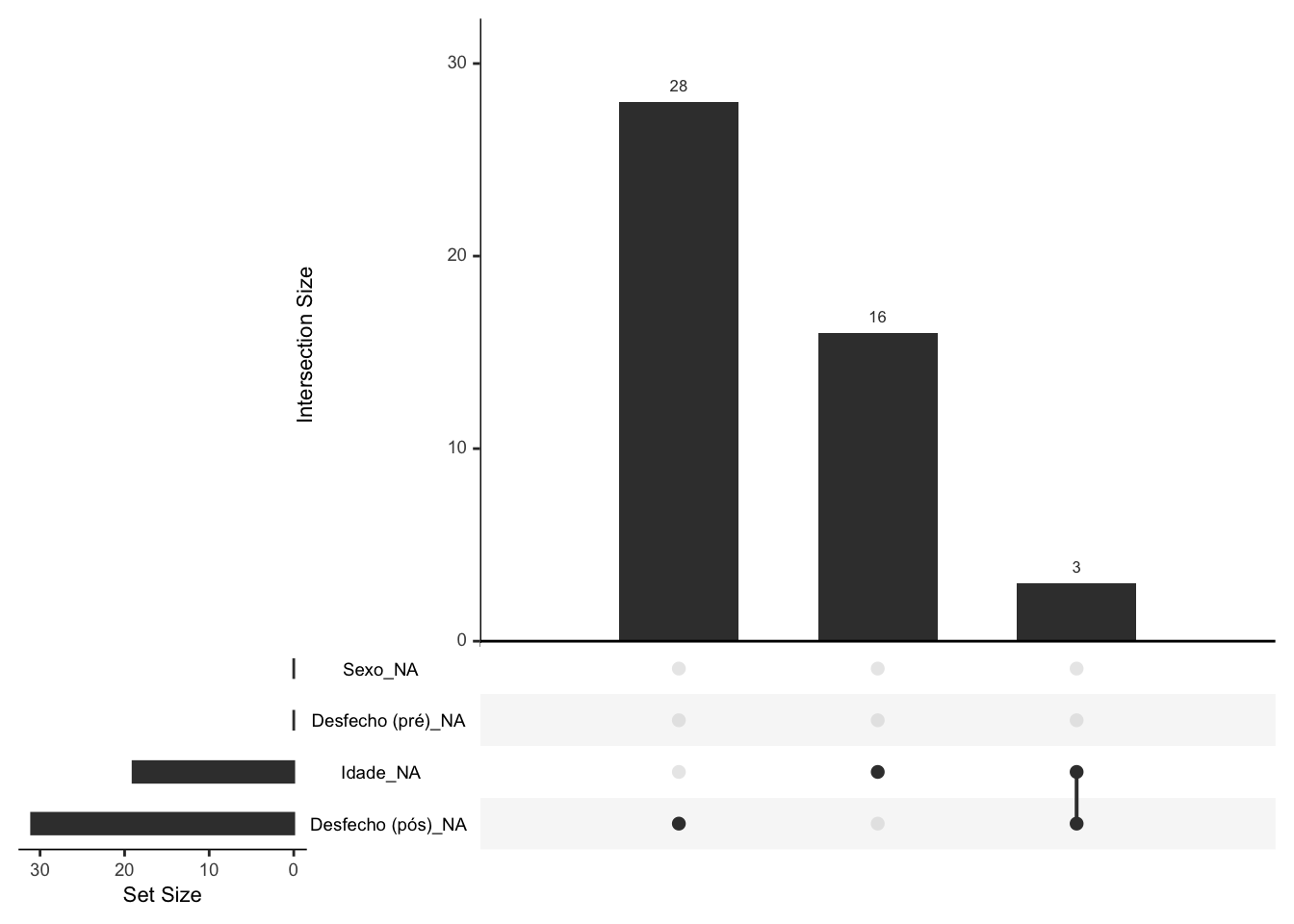
Figura 16.2: Representação gráfica de dados perdidos ao acaso (MAR) em um estudo randomizado controlado (RCT).
- Dados perdidos não ao acaso (missing not at random, MNAR), em que a probabilidade da ocorrência de dados perdidos é relacionada com a própria variável.183,184
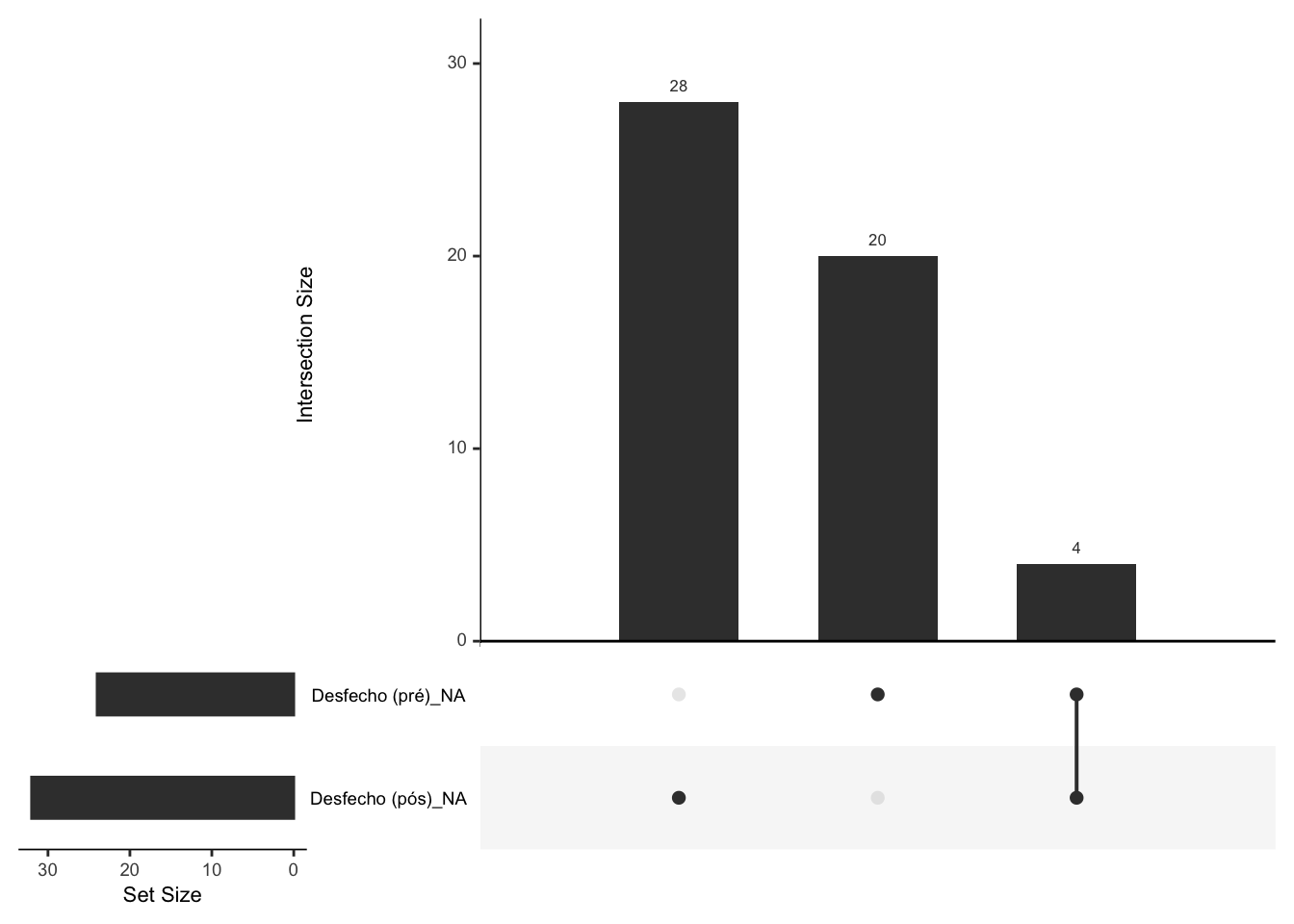
Figura 16.3: Representação gráfica de dados perdidos não ao acaso (MNAR) em um estudo randomizado controlado (RCT).
16.2.2 Como identificar o mecanismo gerador de dados perdidos em um banco de dados?
Por definição, não é possível avaliar se os dados foram perdidos ao acaso (MAR) ou não (MNAR).183
Testes t e regressões logísticas podem ser aplicados para identificar relações entre variáveis com e sem dados perdidos, criando um fator de análise (‘dado perdido’ = 1, ‘dado observado’ = 0).183
O pacote misty185 fornece a função na.test para executar o Little’s Missing Completely at Random (MCAR) test186.
O pacote naniar187 fornece a função mcar_test para executar o Little’s Missing Completely at Random (MCAR) test186.
O pacote naniar187 fornece a função gg_miss_upset para gerar o gráfico Upset para visualizar padrões de dados perdidos.
16.3 Estratégias para lidar com dados perdidos
16.3.1 Que estratégias utilizar na coleta quando há expectativa de perda?
- Recomenda-se ampliar o tamanho da amostra com um percentual correspondente a tal estimativa (ex.: 10%), embora ainda não corrija potenciais vieses pela perda.182
16.3.2 Que estratégias utilizar na análise quando há dados perdidos?
A análise mais comum compreende apenas os ‘casos completos’, com exclusão de participantes com algum dado perdido nas variáveis do estudo. Em casos de grande quantidade de dados perdidos, pode-se perder muito poder estatístico (erro tipo II elevado).182
A análise de dados completos é válida quando pode-se argumentar que a probabilidade de o participante ter dados completos depende apenas das covariáveis e não dos desfechos.184
A análise de dados completos é eficiente quando todos os dados perdidos estão no desfecho, ou quando cada participante com dados perdidos nas covariáveis também possui dados perdidos nos desfechos.184
O pacote base31 fornece a função na.omit para remover dados perdidos de um objeto em um banco de dados.
O pacote stats159 fornece a função complete.cases para identificar os casos completos em um banco de dados.
16.3.3 O que reportar em estudos com dados perdidos?
Métodos para tratamento de dados perdidos.188
Número de participantes com dados perdidos por variável.188
Motivos dos dados perdidos.188
Padrão de perda.188
Diferenças entre os participantes com e sem dados perdidos.188
Resultados de análises de sensibilidade.188
Implicações na interpretação do resultados.188
16.4 Dados imputados
16.4.1 Quando a imputação de dados é indicada?
A análise com imputação de dados pode ser útil quando pode-se argumentar que os dados foram perdidos ao acaso (MAR); quando o desfecho foi observado e os dados perdidos estão nas covariáveis; e variáveis auxiliares (preditoras do desfecho e não dos dados perdidos) estão disponíveis.184
Na ocorrência de dados perdidos, a imputação de dados pode ser uma alternativa para manter o erro tipo II estipulado no plano de análise.182
16.4.2 Quais são os métodos de imputação de dados?
Imputação multivariada por equações encadeadas (Multivariate Imputation by Chained Equations, MICE)189
Correspondência média preditiva (Predictive Mean Matching, PMM).190,191
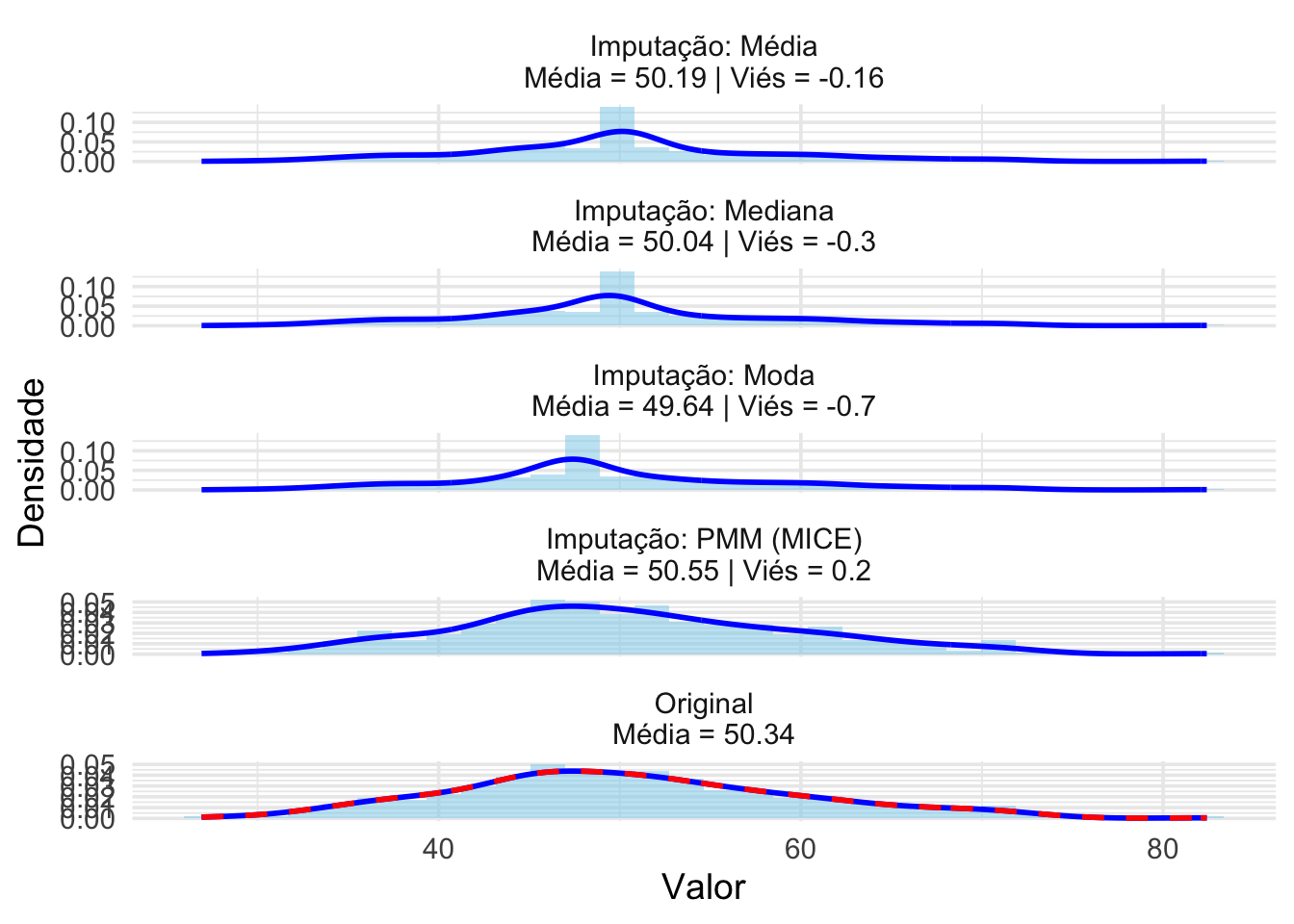
Figura 16.4: Impacto de métodos de imputação na distribuição de uma variável contínua com dados perdidos.
Os pacotes mice189 e miceadds192 fornecem funções mice e mi.anova para imputação multivariada por equações encadeadas, respectivamente, para imputação de dados.
Ferreira, Arthur de Sá. Ciência com R: Perguntas e respostas para pesquisadores e analistas de dados. Rio de Janeiro: 1a edição,