Capítulo 65 Desempenho diagnóstico
65.1 Tabelas 2x2
65.1.1 O que é uma tabela de confusão 2x2?
- Tabela de confusão é uma matriz de 2 linhas por 2 colunas que permite analisar o desempenho de classificação de uma variável dicotômica (padrão-ouro ou referência) versus outra variável dicotômica (novo teste).518
65.1.2 Como analisar o desempenho diagnóstico em tabelas 2x2?
Verdadeiro-positivo (\(VP\)): caso com a condição presente e corretamente identificado como tal.519
Falso-negativo (\(FN\)): caso com a condição presente e erroneamente identificado como ausente.519
Verdadeiro-negativo (\(VN\)): controle sem a condição presente e corretamente identificados como tal.519
Falso-positivo (\(FP\)): controle sem a condição presente e erroneamente identificado como presente.519
| Condição presente | Condição ausente | Total | |
|---|---|---|---|
| Teste positivo | \(VP\) | \(FP\) | \(VP+FP\) |
| Teste negativo | \(FN\) | \(VN\) | \(FN+VN\) |
| Total | \(VP+FN\) | \(FP+VN\) | \(N=VP+VN+FP+FN\) |
- Tabelas de confusão também podem ser visualizadas em formato de árvores de frequência.518
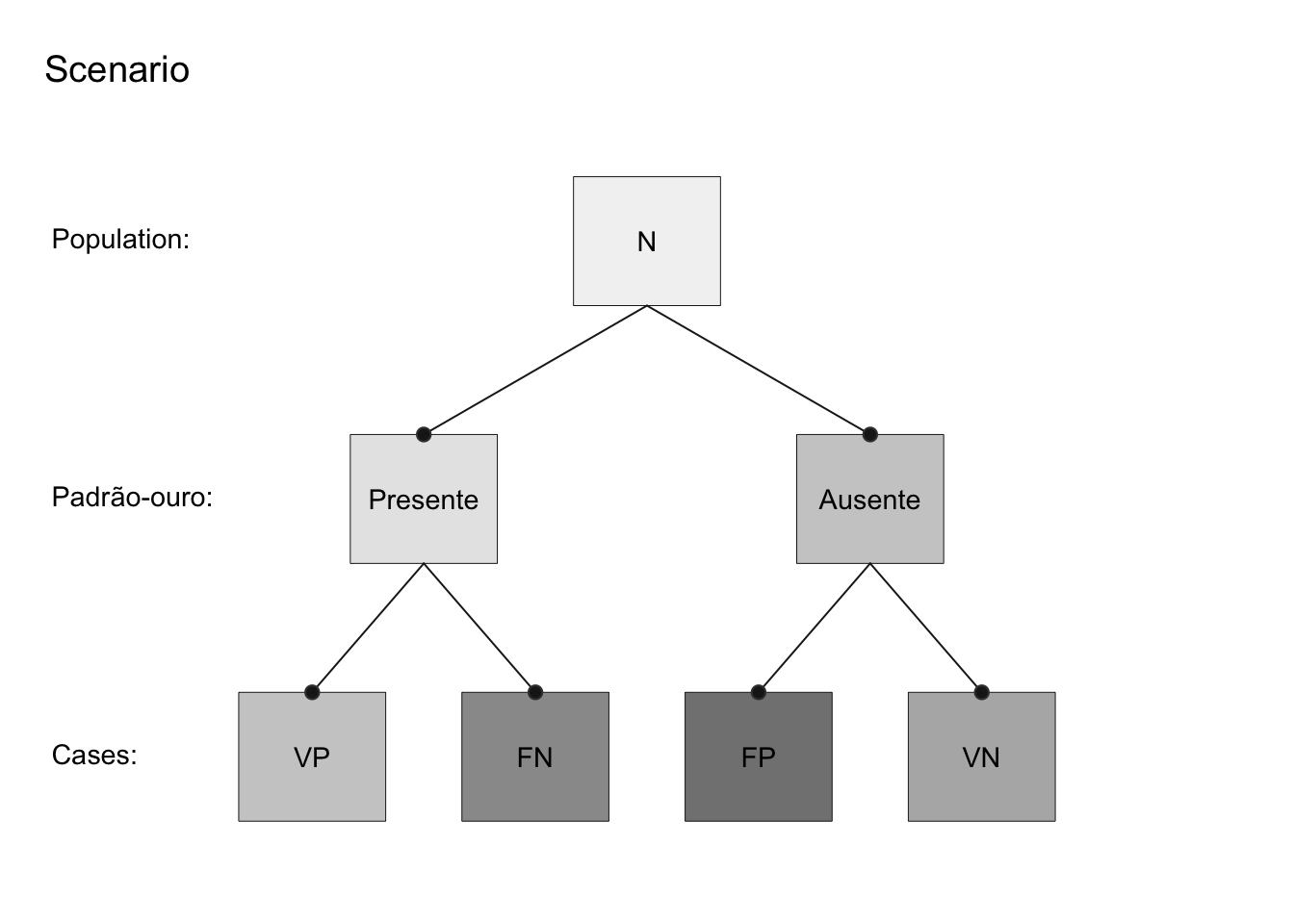
Figura 65.1: Árvore de frequência do desempenho diagnóstico de uma tabela de confusão 2x2 representando um método novo (dicotômico) comparado ao método padrão-ouro ou referência (dicotômico).
O pacote riskyr520 fornece a função plot_prism para construir árvores de frequência a partir de diferentes cenários.
65.1.3 Quais probabilidades caracterizam o desempenho diagnóstico de um teste em tabelas 2x2?
\[\begin{equation} \tag{65.1} SEN = \dfrac{VP}{VP+FN} \end{equation}\]
- Especificidade (\(ESP\)) (65.2): Proporção de verdadeiro-negativos dentre aqueles sem a condição.519
\[\begin{equation} \tag{65.2} ESP = \dfrac{VN}{VN+FP} \end{equation}\]
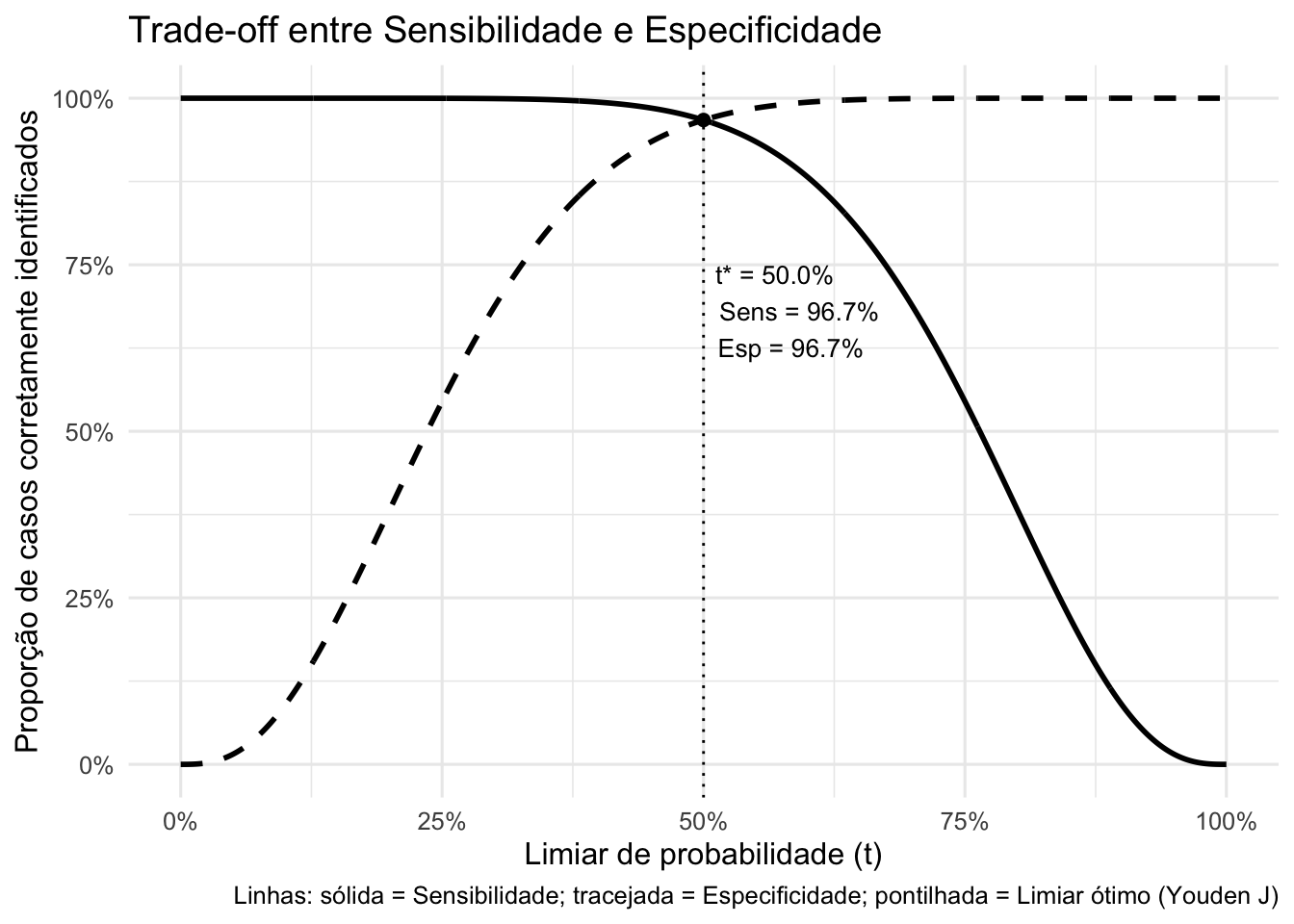
Figura 65.2: Trade-off entre sensibilidade e especificidade em função do limiar de probabilidade (t) para um modelo de classificação.
- Valor preditivo positivo (\(VPP\)) (65.3): Proporção de casos corretamente identificados como verdadeiro-positivos.519
\[\begin{equation} \tag{65.3} VPP = \dfrac{VP}{VP+FP} \end{equation}\]
- Valor preditivo negativo (\(VPN\)) (65.4): Proporção de controles corretamente identificados como verdadeiro-negativos.519
\[\begin{equation} \tag{65.4} VPN = \dfrac{VN}{VN+FN} \end{equation}\]
- Razão de verossimilhança positiva (\(LR+\)) (65.5): Quantifica o quanto a probabilidade de a condição estar presente aumenta quando o teste é positivo.521
\[\begin{equation} \tag{65.5} LR+ = \dfrac{SEN}{1 - ESP} = \dfrac{VP/(VP+FN)}{FP/(FP+VN)} \end{equation}\]
- Razão de verossimilhança negativa (\(LR-\)) (65.6): Quantifica o quanto a probabilidade de a condição estar presente diminui quando o teste é negativo.521
\[\begin{equation} \tag{65.6} LR- = \dfrac{1 - SEN}{ESP} = \dfrac{FN/(VP+FN)}{VN/(FP+VN)} \end{equation}\]
\[\begin{equation} \tag{50.8} ACU = \dfrac{VP+VN}{VP+VN+FP+FN} \end{equation}\]
- Razão de chances diagnóstica (\(DOR\)) (65.7), (65.8) e (65.9): Razão entre a chance de um teste ser positivo quando a condição está presente e a chance de um teste ser positivo quando a condição está ausente.522
\[\begin{equation} \tag{65.7} DOR = \dfrac{VP}{FN} \div \dfrac{FP}{VN} = \dfrac{VP \cdot VN}{FP \cdot FN} \end{equation}\]
\[\begin{equation} \tag{65.8} DOR = \dfrac{SEN/(1-SEN)}{(1-ESP)/ESP} = \dfrac{SEN \cdot ESP}{(1-SEN) \cdot (1-ESP)} \end{equation}\]
\[\begin{equation} \tag{65.9} DOR = \dfrac{LR+}{LR-} \end{equation}\]
| Condição presente | Condição ausente | Total | Probabilidades | |
|---|---|---|---|---|
| Teste positivo | \(VP\) | \(FP\) | \(VP+FP\) | \(VPP = \frac{VP}{VP+FP}\) |
| Teste negativo | \(FN\) | \(VN\) | \(FN+VN\) | \(VPN = \frac{VN}{VN+FN}\) |
| Total | \(VP+FN\) | \(FP+VN\) | \(N=VP+VN+FP+FN\) | |
| Probabilidades | \(SEN = \frac{VP}{VP+FN}\) | \(ESP = \frac{VN}{VN+FP}\) | \(ACU = \frac{VP+VN}{VP+VN+FP+FN}\) \(DOR = \frac{VP \cdot VN}{FP \cdot FN}\) |
O pacote riskyr520 fornece a função comp_prob para estimar 13 probabilidades relacionadas ao desempenho diagnóstico em tabelas 2x2.
O pacote caret424 fornece a função confusionMatrix para estimar 11 probabilidades relacionadas ao desempenho diagnóstico em tabelas 2x2.
65.2 Tabelas 2x3
65.2.1 O que é uma tabela de confusão 2x3?
É a extensão da tabela 2×2 que inclui uma terceira decisão (deferimento/boundary) além de aceitar (positivo) e rejeitar (negativo).523
As colunas** representam as decisões** (\(POS\), \(BND\), \(NEG\)) e as linhas representam a verdade de referência (condição presente versus ausente).523
Essa formulação vem do arcabouço de Three-Way Decisions (3WD), que particiona o universo em três regiões por dois limiares \(\alpha\) e \(\beta\).523
65.2.2 Como as regiões POS, BND e NEG são definidas?
- Dado um escore ou probabilidade condicional \(Pr(C\mid[x])\) para a classe \(C\), classifica-se como \(POS\) (aceitar) quando \(Pr(C\mid[x]) \ge \alpha\), como \(BND\) (deferir) quando \(\beta < Pr(C\mid[x]) < \alpha\) e como \(NEG\) (rejeitar) quando \(Pr(C\mid[x]) \le \beta\), sendo que os limiares \((\alpha,\beta)\) determinam simultaneamente as três regiões e os trade-offs entre acurácia e comprometimento.523
65.2.3 Qual é o formato de uma tabela 2×3?
- Estrutura geral (linhas = condição real; colunas = decisão):
| POS (aceitar) | BND (deferir) | NEG (rejeitar) | Total | |
|---|---|---|---|---|
| Condição presente (C) | \(|POS\cap C|\) | \(|BND\cap C|\) | \(|NEG\cap C|\) | \(|POS\cap C|+|BND\cap C|+|NEG\cap C|\) |
| Condição ausente (\(C^c\)) | \(|POS\cap C^c|\) | \(|BND\cap C^c|\) | \(|NEG\cap C^c|\) | \(|POS\cap C^c|+|BND\cap C^c|+|NEG\cap C^c|\) |
| Total | \(|POS\cap C|+|POS\cap C^c|\) | \(|BND\cap C|+|BND\cap C^c|\) | \(|NEG\cap C|+|NEG\cap C^c|\) | \(N\) |
65.2.4 Quais são as medidas básicas na 2×3?
- Acurácia em POS (\(M_{PT}\)), equação (65.10): Proporção de positivos corretamente identificados na região POS.523
\[\begin{equation} \tag{65.10} M_{PT} = \dfrac{|POS \cap C|}{|POS|} \end{equation}\]
- Erro em POS (\(M_{PF}\)), equação (65.11): Proporção de negativos incorretamente classificados na região POS.523
\[\begin{equation} \tag{65.11} M_{PF} = \dfrac{|POS \cap C^{c}|}{|POS|} \end{equation}\]
- Acurácia em NEG (\(M_{NF}\)), equação (65.12): Proporção de negativos corretamente identificados na região NEG.523
\[\begin{equation} \tag{65.12} M_{NF} = \dfrac{|NEG \cap C^{c}|}{|NEG|} \end{equation}\]
- Erro em NEG (\(M_{NT}\)), equação (65.13): Proporção de positivos incorretamente classificados na região NEG.523
\[\begin{equation} \tag{65.13} M_{NT} = \dfrac{|NEG \cap C|}{|NEG|} \end{equation}\]
- Frações em BND (\(M_{BT}\) e \(M_{BF}\)), equações (65.14) e (65.15): Proporção de deferimentos verdadeiros e falsos.523
\[\begin{equation} \tag{65.14} M_{BT} = \dfrac{|BND \cap C|}{|BND|} \end{equation}\]
\[\begin{equation} \tag{65.15} M_{BF} = \dfrac{|BND \cap C^{c}|}{|BND|} \end{equation}\]
65.2.5 Como escolher os limiares \(\alpha\) e \(\beta\)?
- Os limiares \((\alpha,\beta)\) controlam o tamanho das regiões \(POS\), \(NEG\) e \(BND\) e, portanto, os trade-offs entre “acertar mais” (acurácia nas regiões) e “decidir mais” (comprometimento; menos deferimentos).523
65.2.6 Quando preferir 3-vias em vez de 2×2?
Quando o custo de erro é assimétrico e/ou há incerteza relevante.523
O deferimento (\(BND\)) evita decisões precipitadas e permite avaliação adicional, equilibrando acurácia e cobertura.523
É particularmente útil em triagens diagnósticas com etapas confirmatórias.523
65.3 Curvas ROC
65.3.1 O que representa a curva ROC?
A curva característica de operação do receptor (ROC) apresenta a relação entre sensibilidade (\(SEN\)) no eixo vertical e \(1 - ESP\) no eixo horizontal.524
Cada ponto na curva corresponde a um ponto de corte possível do teste.524
65.3.2 Quais são os tipos de curva ROC?
Curva empírica: conecta diretamente os pontos obtidos a partir dos diferentes pontos de corte observados.525
Curva suavizada (paramétrica): assume uma distribuição binormal e gera uma curva ajustada por máxima verossimilhança.525
65.3.3 Como definir o melhor ponto de corte?
O ponto de corte em uma curva ROC representa um balanço entre sensibilidade e especificidade, ou seja, a taxa de verdadeiros positivos e a taxa de falsos positivos.524,525
O método de Youden (equação (65.16) maximiza a diferença entre a taxa de verdadeiros positivos e a taxa de falsos positivos. O ponto de corte ideal será aquele com maior valor de \(Y\).154
\[\begin{equation} \tag{65.16} Y = SEN + ESP - 1 \end{equation}\]
- O método da distância Euclidiana ((65.17) minimiza a distância entre um ponto da curva ROC e o ponto (0,1), que representa sensibilidade perfeita (\(SEN = 100%\)) e especificidade perfeita (\(ESP = 100%\)). O ponto de corte ideal será aquele com menor valor de \(D\).526
\[\begin{equation} \tag{65.17} D = \sqrt{(1 - SEN)^2 + (1 - ESP)^2} \end{equation}\]
65.3.4 O que é a área sob a curva (AUROC)?
A área sob a curva ROC (AUC ou AUROC) quantifica o poder de discriminação ou desempenho diagnóstico na classificação de uma variável dicotômica.527
A área sob a curva (\(AUC\)) resume o desempenho global e representa a probabilidade de o teste classificar corretamente um caso positivo selecionado aleatoriamente em relação a um caso negativo selecionado aleatoriamente.524
65.3.5 Como calcular a AUC?
- Método não paramétrico: soma das áreas trapezoidais sob a curva empírica (65.18). Pode subestimar AUC quando os dados são discretos.525
\[\begin{equation} \tag{65.18} AUC = \sum_{i=1}^{n-1} (x_{i+1} - x_i) \cdot \dfrac{y_i + y_{i+1}}{2} \end{equation}\]
- Método paramétrico (binormal): mais robusto para dados em escala ordinal, com viés reduzido (65.19), onde\(\Phi\) é a função de distribuição acumulada da Normal padrão, \(\mu_1\) e \(\mu_0\) são as médias dos escores para os grupos positivo e negativo, respectivamente, e \(\sigma_1^2\) e \(\sigma_0^2\) são as variâncias dos escores para os grupos positivo e negativo, respectivamente.525
\[\begin{equation} \tag{65.19} AUC = \Phi\left(\dfrac{\mu_1 - \mu_0}{\sqrt{\sigma_1^2 + \sigma_0^2}}\right) \end{equation}\]
- AUC deve sempre vir acompanhada de intervalo de confiança (IC95%).525
O pacote proc528 fornece a função plot.roc para criar uma curva ROC.
65.3.6 Como interpretar a área sob a curva (ROC)?
A área sob a curva AUC varia no intervalo \([0.5; 1]\), com valores mais elevados indicando melhor discriminação ou desempenho do modelo de classificação.527
As interpretações qualitativas (isto é: pobre/fraca/baixa, moderada/razoável/aceitável, boa ou muito boa/alta/excelente) dos valores de área sob a curva são arbitrários e não devem ser considerados isoladamente.527
Modelos de classificação com valores altos de área sob a curva podem ser enganosos se os valores preditos por esses modelos não estiverem adequadamente calibrados.527
Diferenças pequenas entre AUCs podem não ser estatisticamente significativas.524
A interpretação clínica pode ser equivocada se não houver teste estatístico adequado.524
Se as curvas vêm do mesmo conjunto de pacientes, aplique o teste de DeLong.524
Se as curvas vêm de amostras independentes, use métodos como Dorfman-Alf.524
65.3.7 Por que uma AUC menor que 0.5 está errada?
Porque indica desempenho pior que o acaso.524
Geralmente decorre de seleção incorreta da direção do teste ou da variável de estado.524
Verifique se o software está configurado para maiores valores indicam presença do evento ou o inverso.524
Ajuste a direção do teste para que \(AUC \geq 0.5\).524
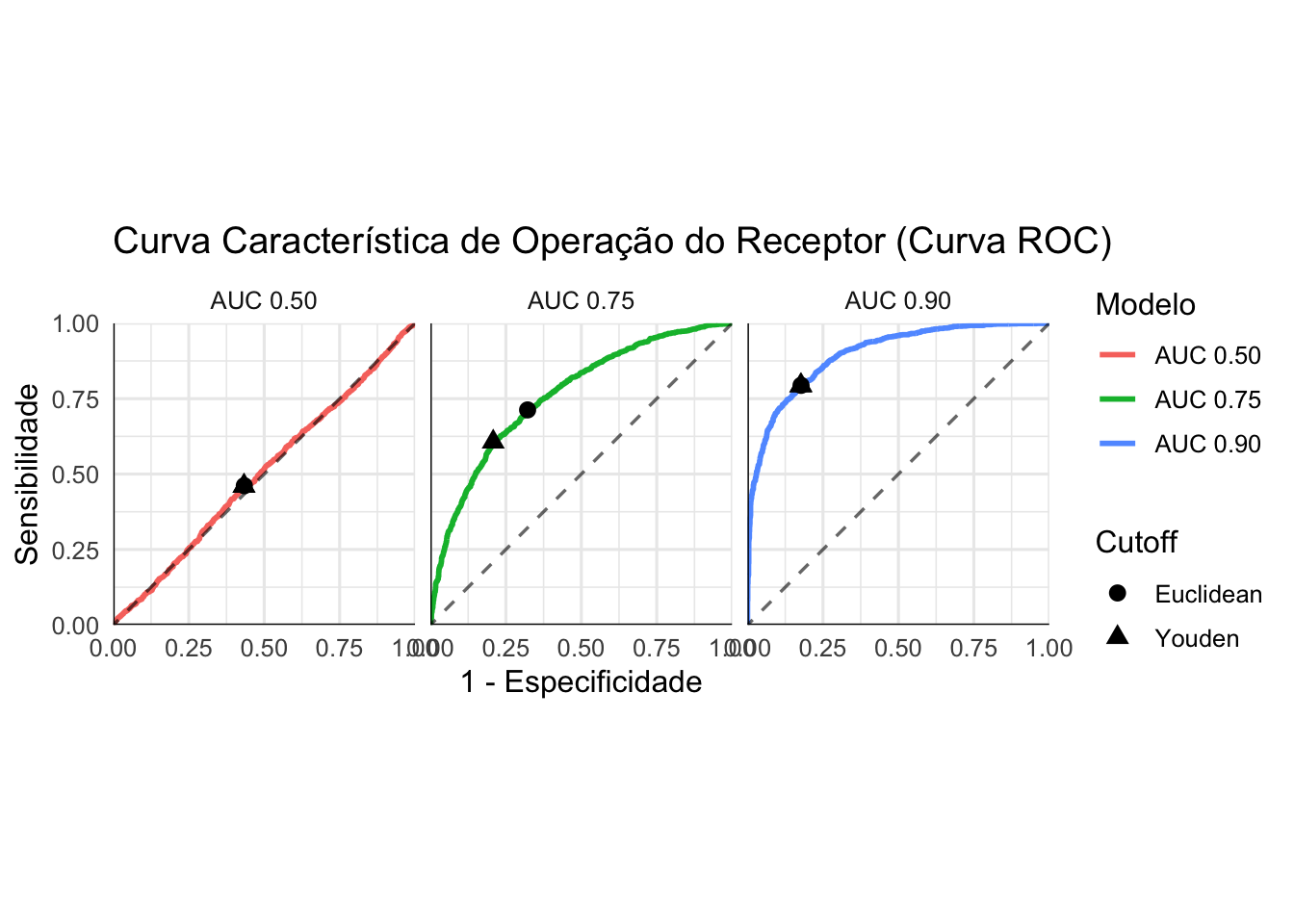
Figura 65.3: Curva ROC (Receiver Operating Characteristic) para um modelos de classificação com diferentes desempenhos diagnósticos.
65.3.8 Como analisar o desempenho diagnóstico em desfechos com distribuição trimodal na população?
- Limiares duplos podem ser utilizados para análise de desempenho diagnóstico de testes com distribuição trimodal.529
65.4 Interpretação da validade de um teste
65.4.1 Que itens devem ser verificados na interpretação de um estudo de validade?
O novo teste foi comparado junto ao método padrão-ouro.519
As probabilidades pontuais estimadas que caracterizam o desempenho diagnóstico do novo teste são altas e adequadas para sua aplicação clínica.519
Os intervalos de confiança estimados para as probabilidades do novo teste são estreitos e adequadas para sua aplicação clínica.519
O novo teste possui adequada confiabilidade intra/inter examinadores.519
O estudo de validação incluiu um espectro adequado da amostra.519
Todos os participantes realizaram ambos o novo teste e o padrão-ouro no estudo de validação.519
Os examinadores do novo teste estavam cegados para o resultado do teste padrão-ouro.519
65.5 Diretrizes para redação
65.5.1 Quais são as diretrizes para redação de estudos diagnósticos?
Visite a rede Enhancing the QUAlity and Transparency Of health Research (EQUATOR Network) para encontrar diretrizes específicas.
STARD 2015: An Updated List of Essential Items for Reporting Diagnostic Accuracy Studies.530
Ferreira, Arthur de Sá. Ciência com R: Perguntas e respostas para pesquisadores e analistas de dados. Rio de Janeiro: 1a edição,