Capítulo 31 Suposições inferenciais
31.1 Suposições gerais em análises inferenciais
31.1.1 Quais são as suposições gerais em análises inferenciais?
- .REF?
O pacote AssumpSure339 fornece um Shiny App para validação de suposições estatísticas.
31.1.2 Quais são as suposições ao nível dos dados (condicionais ao modelo)?
Independência (ou dependência corretamente modelada) das observações.REF?
Forma da distribuição dos erros ou resíduos (normalidade, assimetria, caudas).REF?
homoscedasticidade (igualdade de variâncias condicionais).REF?
31.2 Suposições implícitas e explícitas nos testes
31.3 Suposições causais que conectam dados observados a efeitos causais
31.3.1 Quais são as suposições causais que conectam dados observados a efeitos causais?
Ausência de correlação espúria: associações observadas refletem relações sistemáticas e não flutuações aleatórias; quanto maior a amostra, mais plausível essa condição.REF?
Consistência: os valores observados do tratamento correspondem a intervenções bem definidas e coincidem com os valores dos contrafactuais relevantes.REF?
Intercambialidade: condicionalmente às covariáveis medidas, a atribuição do tratamento é independente dos desfechos potenciais.REF?
Positividade: para todos os valores das covariáveis consideradas, a probabilidade de receber cada nível do tratamento é maior que zero.REF?
Fidelidade: efeitos causais não se cancelam sistematicamente no agregado populacional, de modo que efeitos médios nulos correspondem à ausência de efeito causal relevante.REF?
31.3.2 Qual a relação dessas suposições com as demais suposições inferenciais?
Essas suposições operam antes do modelo estatístico.REF?
Não são verificáveis por diagnóstico residual ou testes de ajuste.REF?
Mesmo com todas as suposições estatísticas satisfeitas, a inferência causal pode falhar se qualquer uma dessas suposições não for atendida.REF?
31.4 Diagnóstico e verificação
31.4.1 O que fazer quando suposições gerais falham?
Transformações.REF?
Métodos robustos (estimadores e testes).REF?
Reamostragem.REF?
Modelos alternativos.REF?
31.4.2 O que fazer quando as suposições causais falham?
Clarificar o alvo causal: redefinir a população, o tratamento ou o efeito de interesse.REF?
Análise de sensibilidade: avaliar quanto confundimento não medido seria necessário para invalidar as conclusões.REF?
Restringir o suporte: limitar a análise a regiões com positividade plausível (suporte comum).REF?
Estratificação ou ajuste enriquecido: incluir covariáveis adicionais relevantes, quando disponíveis.REF?
Modelagem causal explícita: usar diagramas acíclicos direcionados para tornar suposições transparentes e discutíveis.REF?
Estimativas parciais ou locais: reportar efeitos condicionais ou locais quando o efeito médio não é identificável.REF?
Conclusões mais fracas: interpretar resultados como associações ajustadas, não como efeitos causais.REF?
Relato explícito das falhas: documentar quais suposições não são plausíveis e por quê.REF?
O pacote performance315 fornece a função check_model para analisar a colinearidade entre variáveis, a normalidade da distribuição das variáveis e a heteroscedasticidade.
31.4.3 Como avaliar as suposições de uma regressão?
- Usando diagnóstico de regressão (ex.: análise de resíduos, gráficos de valores observados vs. preditos) e comparação com análises estratificadas.340
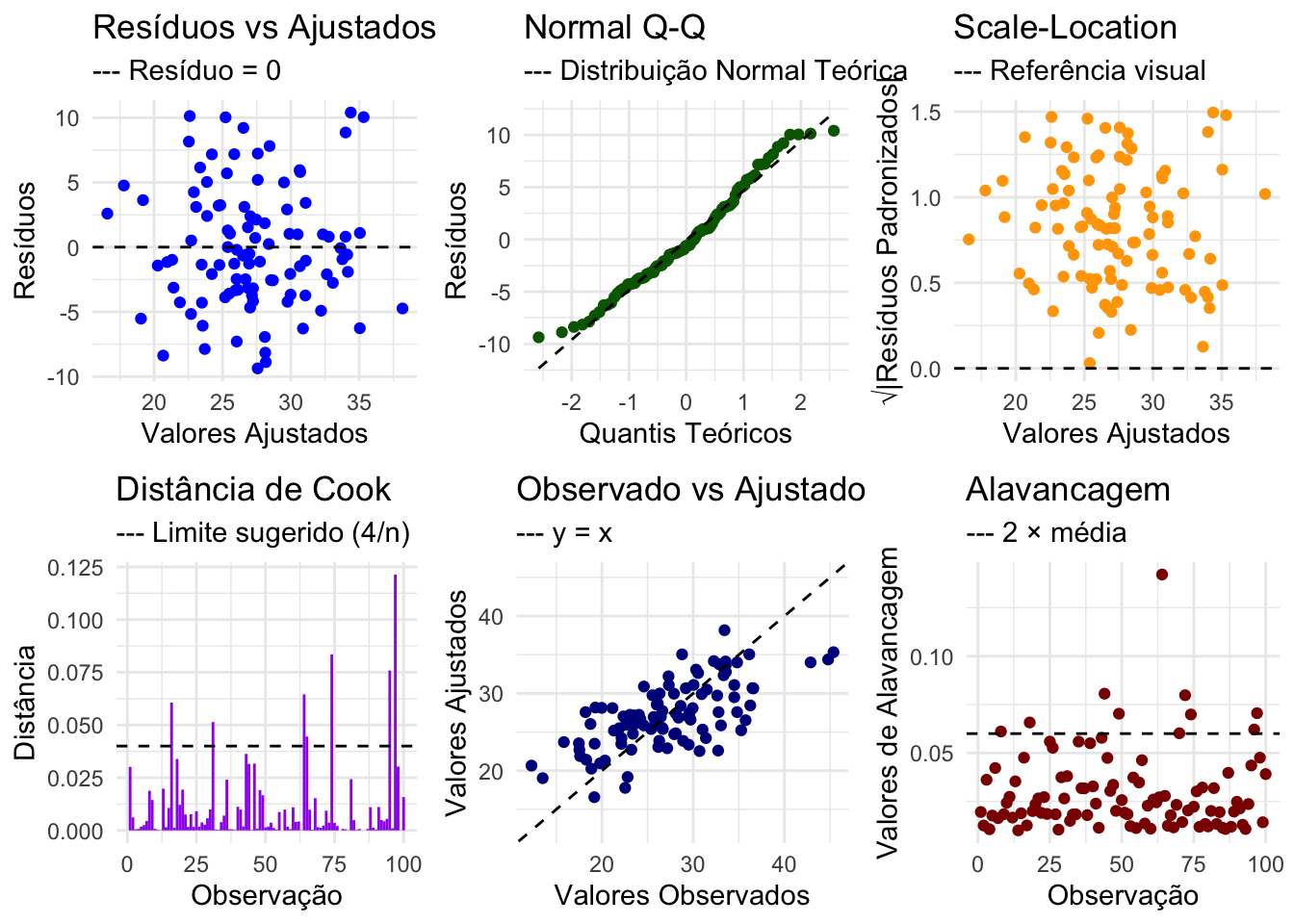
Figura 31.1: Diagnóstico de regressão para avaliar suposições do modelo: linearidade, normalidade dos resíduos, homoscedasticidade e alavancagem.
31.4.4 Como avaliar a independência entre variáveis?
Verifique por dependência entre variáveis de um modelo de regressão:286
Gráfico de série temporal das variáveis
Gráfico de autocorrelação entre as variáveis
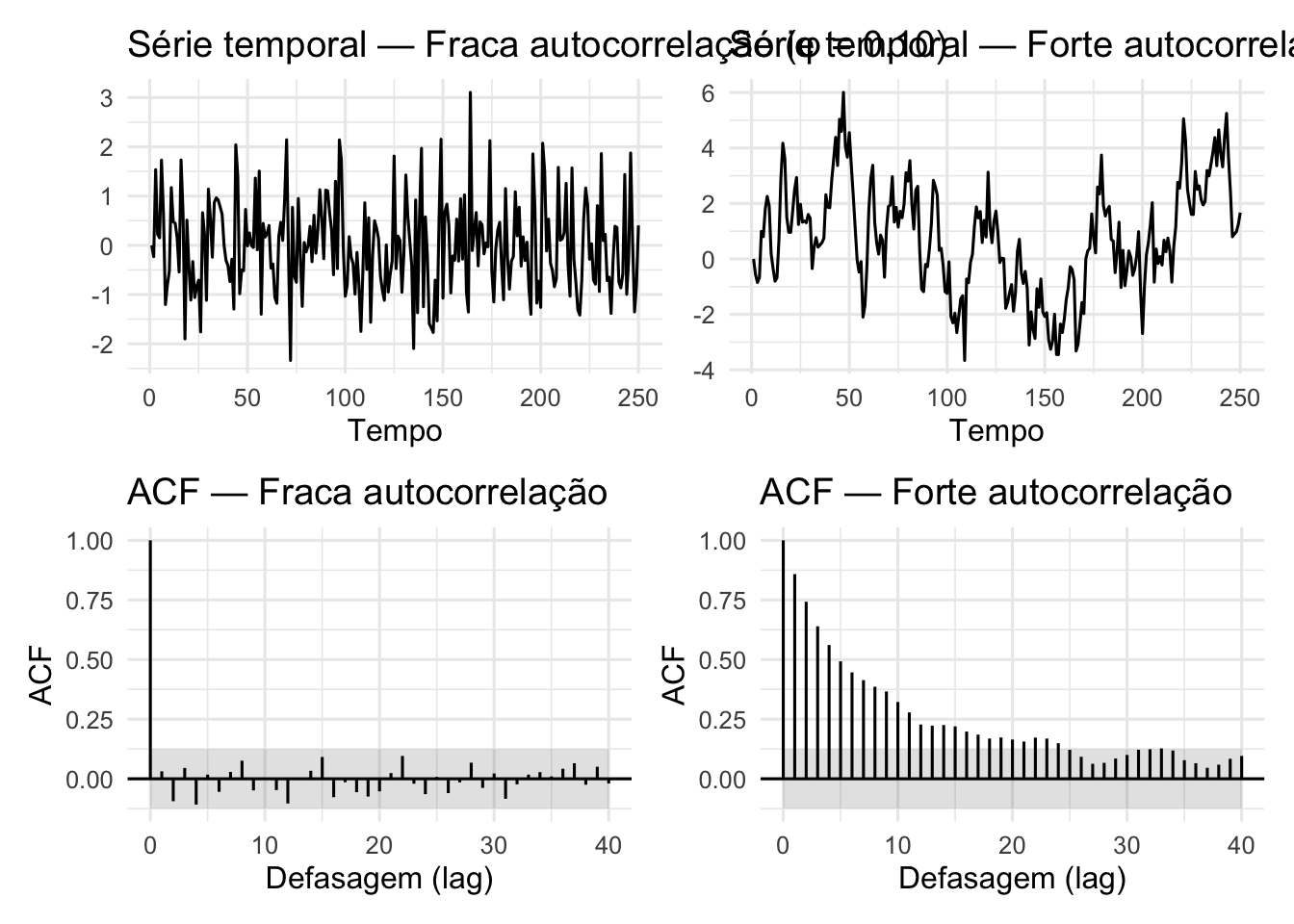
Figura 31.2: Séries temporais e autocorrelação de duas séries simuladas com fraca e forte autocorrelação.
31.6 Escolha entre métodos paramétricos e não paramétricos
31.6.1 O que é análise paramétrica?
Testes não paramétricos fazem suposições sobre a forma da distribuição, as características e/ou parâmetros da distribuição dos dados na população.136,137
Testes paramétricos são baseados na suposição de que os dados amostrais provêm de uma população com parâmetros fixos determinando sua distribuição de probabilidade.60
31.6.2 O que é análise não paramétrica?
Testes não-paramétricos fazem poucas suposições, ou menos rigorosas, sobre as características e/ou parâmetros da distribuição dos dados na população.136,137
Testes não-paramétricos são úteis quando as suposições de normalidade não podem ser sustentadas.137
31.6.3 Por que análises paramétricas são preferidas?
Quando as suposições são atendidas, testes paramétricos tendem a apresentar maior poder estatístico que testes não-paramétricos correspondentes.136,232,342
Testes não-paramétricos apresentam menor poder estatístico (maior erro tipo II) comparados aos testes paramétricos correspondentes.137
Ferreira, Arthur de Sá. Ciência com R: Perguntas e respostas para pesquisadores e analistas de dados. Rio de Janeiro: 1a edição,