Capítulo 50 Aprendizado de máquina
50.1 Aprendizado de máquina
50.1.1 O que é aprendizado de máquina?
Treinar um modelo significa resolver um problema matemático no qual um conjunto de observações (dados) é usado para ajustar um modelo.414
Modelos de aprendizado de máquina buscam capturar tendências gerais dos dados, ignorando particularidades excessivas para evitar sobreajuste (overfitting).414
O processo deriva do conceito estatístico de regressão e corresponde, em essência, à solução de um problema em que há mais restrições do que graus de liberdade.414
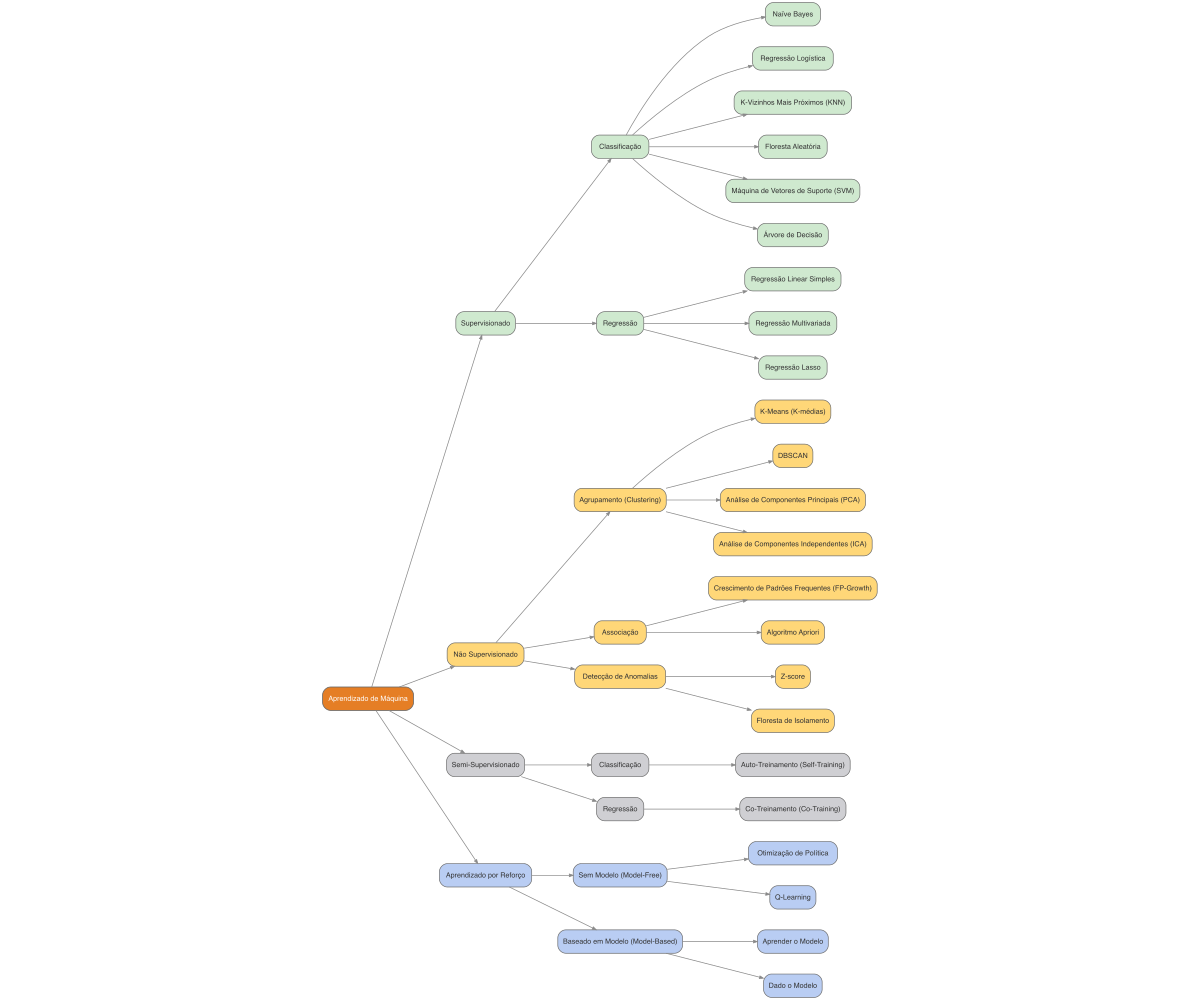
Figura 50.1: Mapa mental de algoritmos de aprendizado de máquina.
O pacote fastml415 fornece a função train_models para treinar algoritmos de aprendizado de máquina em dados de treinamento pré-processados.
50.2 Tipos de aprendizado
50.2.1 O que é aprendizado supervisionado?
Aprendizado supervisionado é um paradigma em que um conjunto de variáveis preditoras (entradas) é utilizado para prever uma variável resposta previamente rotulada, seja ela quantitativa (regressão) ou qualitativa (classificação).416
O algoritmo aprende padrões gerais a partir de exemplos observados, guiado por um objetivo explícito de predição.416
Durante o treinamento, o modelo ajusta seus parâmetros para minimizar uma função de erro que compara valores previstos com rótulos verdadeiros, buscando equilíbrio entre ajuste aos dados e capacidade de generalização.416
50.2.2 O que é aprendizado não supervisionado?
Aprendizado não supervisionado é um paradigma em que o modelo tenta identificar padrões ou estruturas ocultas nos dados sem rótulos ou desfechos pré-definidos.417
Diferentemente do aprendizado supervisionado, que busca prever um desfecho conhecido, o aprendizado não supervisionado é frequentemente utilizado para gerar descobertas orientadas por dados.417
Esses métodos permitem identificar estruturas, agrupamentos, relações multivariadas e padrões latentes que não haviam sido previamente formulados como hipóteses.417
50.2.4 Quais são os limites do progresso em classificadores supervisionados?
Os maiores ganhos de acurácia vêm de modelos simples, como análise discriminante linear; métodos mais sofisticados oferecem apenas ganhos marginais.418
O aumento da complexidade do modelo traz retornos decrescentes em termos de redução da taxa de erro.418
50.2.5 Quais problemas práticos limitam a generalização de classificadores?
Population drift: mudanças na distribuição dos dados ao longo do tempo degradam a performance de modelos.418
Sample selectivity bias: amostras de treino podem não representar a população futura, levando a superestimação de desempenho.418
Erros de rótulo e definições arbitrárias de classes comprometem a validade dos modelos.418
50.3 Fluxo de desenvolvimento de modelos
50.3.1 Qual é o fluxo para descoberta científica usando aprendizado de máquina?
Formulação de uma pergunta científica validável.417
Preparação e exploração dos dados.417
Aplicação de múltiplos métodos de modelagem.417
Validação dos resultados.417
Comunicação e documentação dos achados.417
O planejamento do processo deve ocorrer antes da análise, incluindo estratégias de validação e critérios para comparação dos modelos.417
50.3.2 Qual é o fluxo de desenvolvimento de modelos de aprendizado de máquina?
Preparação e limpeza dos dados.419
Divisão em conjuntos de treinamento, validação e teste.419
Treinamento do modelo.419
Ajuste de hiperparâmetros.419
Avaliação do desempenho do modelo.419
Validação em dados independentes.419
50.3.3 O que são conjuntos de treinamento, validação e teste?
Conjunto de treinamento e validação são subdivisões dos dados, permitindo avaliar o desempenho do modelo em dados não utilizados durante o ajuste dos parâmetros.419
Conjunto de treinamento: usado para ajustar os parâmetros do modelo.419
Conjunto de validação: usado para comparar modelos e ajustar hiperparâmetros.419
Conjunto de teste: usado apenas para avaliar o desempenho final do modelo.419
50.4 Principais algoritmos
50.4.1 Quais são os principais algoritmos de aprendizado de máquina?
Modelos de regressão não penalizados, modelos de regressão penalizados, modelos baseados em árvores, modelos baseados em vizinhos, redes neurais, máquinas de vetores de suporte, Naive Bayes e ensembles do tipo superlearner.420
Do ponto de vista matemático, redes neurais não contradizem a estatística clássica; elas a estendem, substituindo modelos explícitos por representações aprendidas.REF?
| Modelos de regressão | Redes neurais artificiais | Papel conceitual |
|---|---|---|
| Variável preditora (x) | Neurônio de entrada | Informação observada fornecida ao modelo |
| Coeficiente (β) | Peso (w) | Intensidade e direção da influência da variável |
| Intercepto (β₀) | Viés (b) | Deslocamento da fronteira de decisão |
| Combinação linear (β₀ + Σ βᵢxᵢ) | Soma ponderada (Σ wᵢxᵢ + b) | Agregação das entradas antes da não linearidade |
| Função de ligação (link) | Função de ativação | Introdução de não linearidade |
| Regressão linear | Neurônio linear | Modelo puramente linear |
| Regressão logística | Perceptron com ativação sigmoide | Classificação binária probabilística |
| Log-odds | Entrada da função sigmoide | Escala interna antes da probabilidade |
| Predição (ŷ) | Saída do neurônio | Resposta estimada do modelo |
| Função de perda | Função de perda (loss) | Quantificação do erro de predição |
| Máxima verossimilhança | Otimização da função de perda | Ajuste dos parâmetros do modelo |
| Gradiente da verossimilhança | Retropropagação (backpropagation) | Direção de atualização dos parâmetros |
| Regularização (L1, L2) | Penalização de pesos (weight decay) | Controle de complexidade e overfitting |
| Interações explícitas | Interações aprendidas implicitamente | Modelagem de efeitos combinados |
| Modelo interpretável | Modelo geralmente opaco | Trade-off entre interpretação e flexibilidade |
50.4.2 Por que estudos comparativos entre classificadores podem ser enganosos?
Resultados dependem da experiência do pesquisador com cada método, da escolha dos conjuntos de dados e do critério de avaliação usado.418
Diferenças pequenas em acurácia frequentemente desaparecem quando se consideram incertezas reais de aplicação.418
50.5 Regressão logística
50.5.1 O que é regressão logística?
Modelos logísticos são casos de regressão linear generalizada em que a resposta \(Y\) é binária.381
A equação (43.8) modela a razão de chances (odds) em função dos preditores.381
\[\begin{equation} \tag{43.8} \log\left(\frac{p}{1-p}\right) = \beta_0 + \beta_1 X + ... + \beta_n X_n \end{equation}\]
\[\begin{equation} \tag{43.9} g(p) = \log\left(\frac{p}{1-p}\right) \end{equation}\]
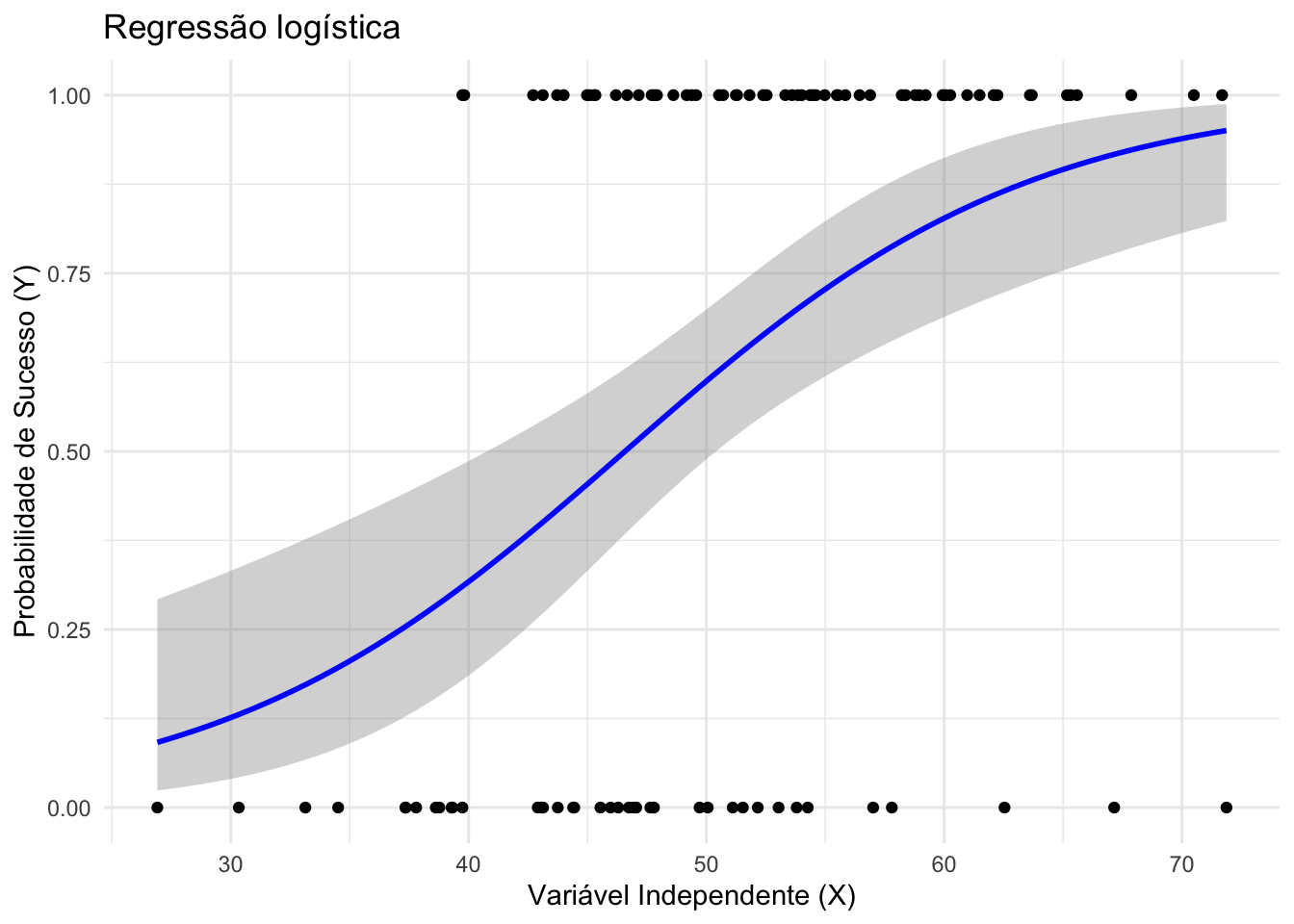
Figura 50.2: Regressão logística.
50.5.2 Por que utilizar regressão logística em problemas de classificação?
Quando a variável resposta é categórica, um método comum para estimar probabilidades e realizar classificação é a regressão logística, que modela a probabilidade de pertencimento a uma classe em função de variáveis preditoras.421
Diferentemente da regressão linear, que pode produzir valores fora do intervalo \([0,1]\), a regressão logística utiliza uma função sigmoide que transforma combinações lineares de preditores em probabilidades válidas.421
A função logística relaciona a probabilidade \(p\) ao logaritmo da razão de chances (log-odds), produzindo uma relação linear entre o log-odds e os preditores.421
Essa formulação permite interpretar os coeficientes do modelo como efeitos aditivos sobre o log-odds do evento de interesse.421
Uma vez estimados os parâmetros, a probabilidade prevista pode ser obtida pela transformação inversa, o que gera uma curva signmóide, adequada para modelar transições graduais entre classes.421
50.6 Máquina de vetores de suporte
50.6.1 O que são máquinas de vetores de suporte?
Máquinas de Vetores de Suporte (SVM) são métodos supervisionados que buscam encontrar um hiperplano que maximize a margem entre classes, utilizando apenas os vetores de suporte — os pontos mais próximos da fronteira decisória.416
O equilíbrio entre margem e penalização de erros é controlado pelo hiperparâmetro \(C\), que regula o trade-off entre viés e variância.416
Valores elevados de \(C\) reduzem violações da margem, mas aumentam risco de overfitting; valores menores favorecem margens mais amplas e maior regularização.416
50.7 K-nearest neighbours
50.7.1 O que é k-nearest neighbours?
O algoritmo k-nearest neighbors (kNN) classifica novos pontos com base na maioria de votos entre os \(k\) vizinhos mais próximos.416
O kNN não assume fronteira paramétrica específica, sendo considerado método não paramétrico.416
O valor de \(k\) atua como parâmetro de regularização: valores pequenos produzem fronteiras altamente flexíveis (alta variância), enquanto valores maiores produzem fronteiras mais suaves (maior viés).416
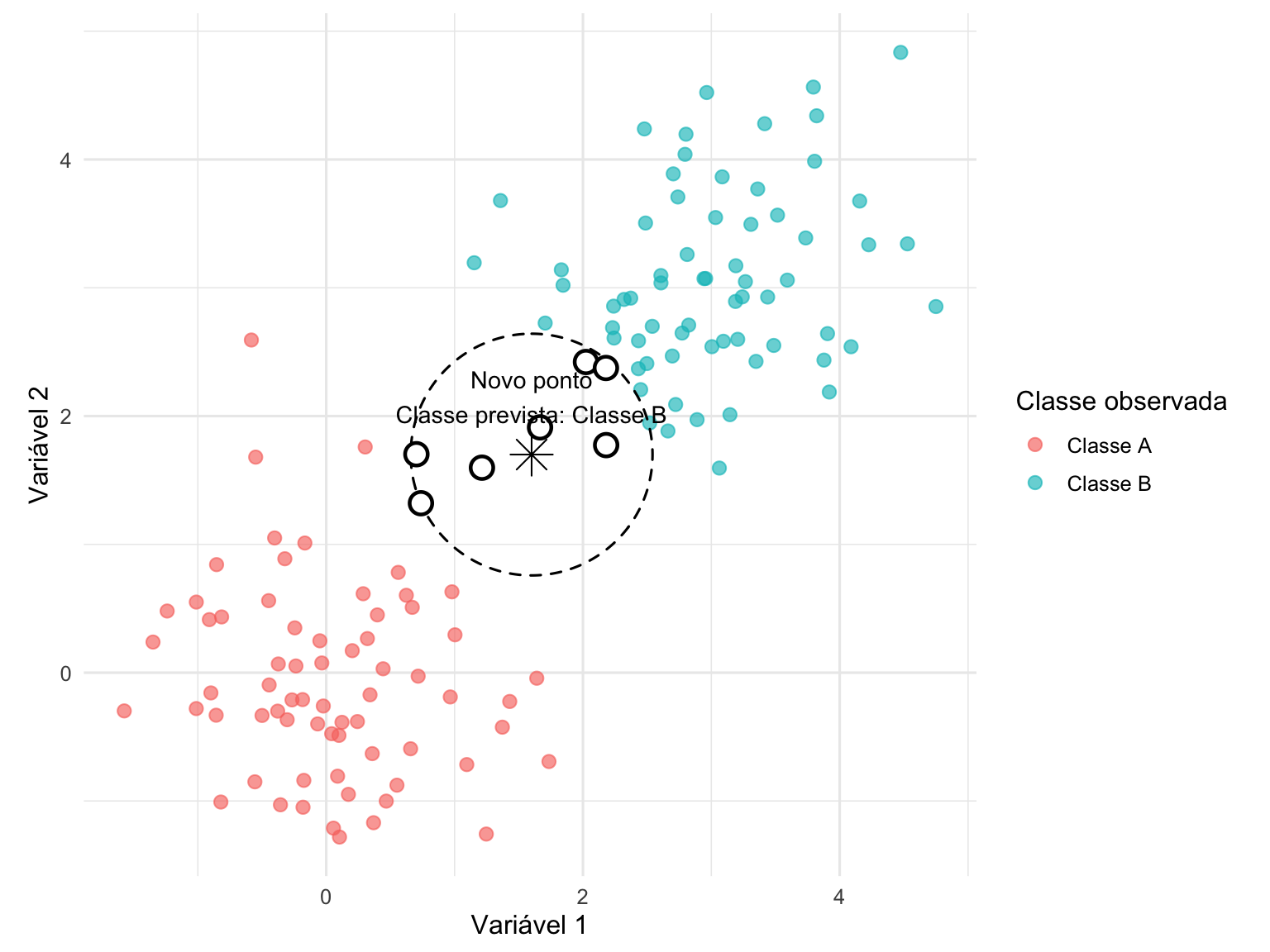
Figura 50.3: Classificação usando o algoritmo KNN.
50.8 Árvores de decisão
50.8.1 O que são árvores de decisão?
São modelos de aprendizado supervisionado que dividem os dados em ramos e folhas, representando regras de decisão de forma hierárquica.307
Podem lidar eficientemente com grandes conjuntos de dados sem pressupor estrutura paramétrica complexa.305
São aplicáveis a variáveis contínuas e discretas, tanto como preditoras quanto como desfechos.305
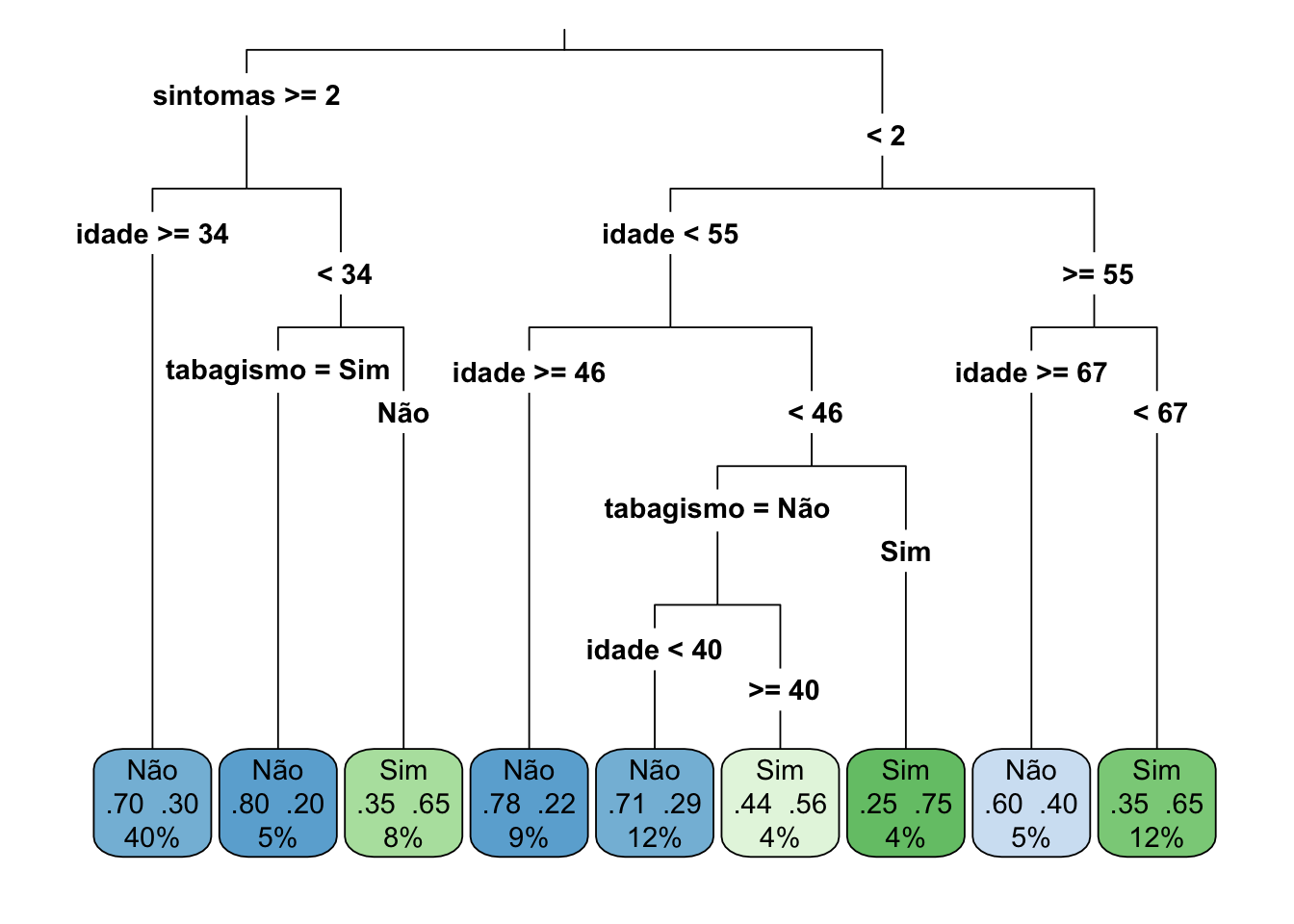
Figura 50.4: Árvore de decisão para predizer depressão a partir de idade, tabagismo e sintomas.
50.8.2 Quais são os principais usos de árvores de decisão?
Seleção de variáveis relevantes em cenários com muitos preditores, como registros clínicos eletrônicos.305
Avaliação da importância relativa das variáveis, com base na redução da pureza dos nós ou da acurácia ao remover variáveis.305
Tratamento de valores ausentes, seja classificando-os como categoria própria ou imputando-os por previsão dentro da árvore.305
Predição de novos casos a partir de dados históricos.305
Manipulação de dados, colapsando categorias muito numerosas ou subdividindo variáveis contínuas assimétricas.305
50.8.3 Quais são os componentes básicos de uma árvore de decisão?
Nós raiz (ou de decisão): subdividem todos os registros iniciais.305
Nós internos (ou de chance): representam subdivisões intermediárias.305
Nós folha (ou finais): resultados finais após sucessivas divisões.305
Ramos: representam condições “se-então”, ligando nós em sequência até a classificação final.305
50.8.4 Como árvores de decisão realizam as divisões nos dados?
Árvores de decisão são construídas por um processo iterativo de particionamento do espaço dos preditores, no qual os dados são divididos em subconjuntos cada vez mais homogêneos em relação ao desfecho.422
Em cada etapa, o algoritmo avalia todos os possíveis pontos de divisão de uma variável preditora e seleciona aquele que maximiza o ganho de informação, isto é, a redução da mistura de classes entre os subconjuntos resultantes.422
O processo de divisão continua recursivamente até que seja atingido um critério de parada, como número mínimo de observações por nó, profundidade máxima da árvore ou redução mínima do erro.422
Alternativamente, a árvore pode ser inicialmente construída em sua forma completa e posteriormente simplificada por poda (pruning), geralmente utilizando validação cruzada para remover ramos pouco informativos e reduzir o risco de overfitting.422
50.8.5 Como funcionam splitting, stopping e pruning?
Splitting: divide registros em subconjuntos mais homogêneos com base em métricas como entropia, índice de Gini e ganho de informação.305
Stopping: evita árvores excessivamente complexas ao definir parâmetros como número mínimo de registros por nó ou profundidade máxima.305
Pruning: reduz árvores grandes eliminando ramos pouco informativos, usando validação ou métodos como qui-quadrado.305
50.8.6 Quais são as vantagens e limitações de árvores de decisão?
Vantagens: simplificam relações complexas; são intuitivas e fáceis de interpretar; não exigem pressupostos de distribuição; lidam bem com valores ausentes e dados enviesados; são robustas a outliers.305
Limitações: podem sofrer overfitting ou underfitting em amostras pequenas; podem selecionar variáveis correlacionadas sem relação causal real.305
50.8.7 Espaço de decisão em árvores de decisão vs. regressão logística
A regressão logística assume relações lineares entre variáveis e log-odds.307
Árvores de decisão permitem capturar relações não lineares e interações de forma automática.307
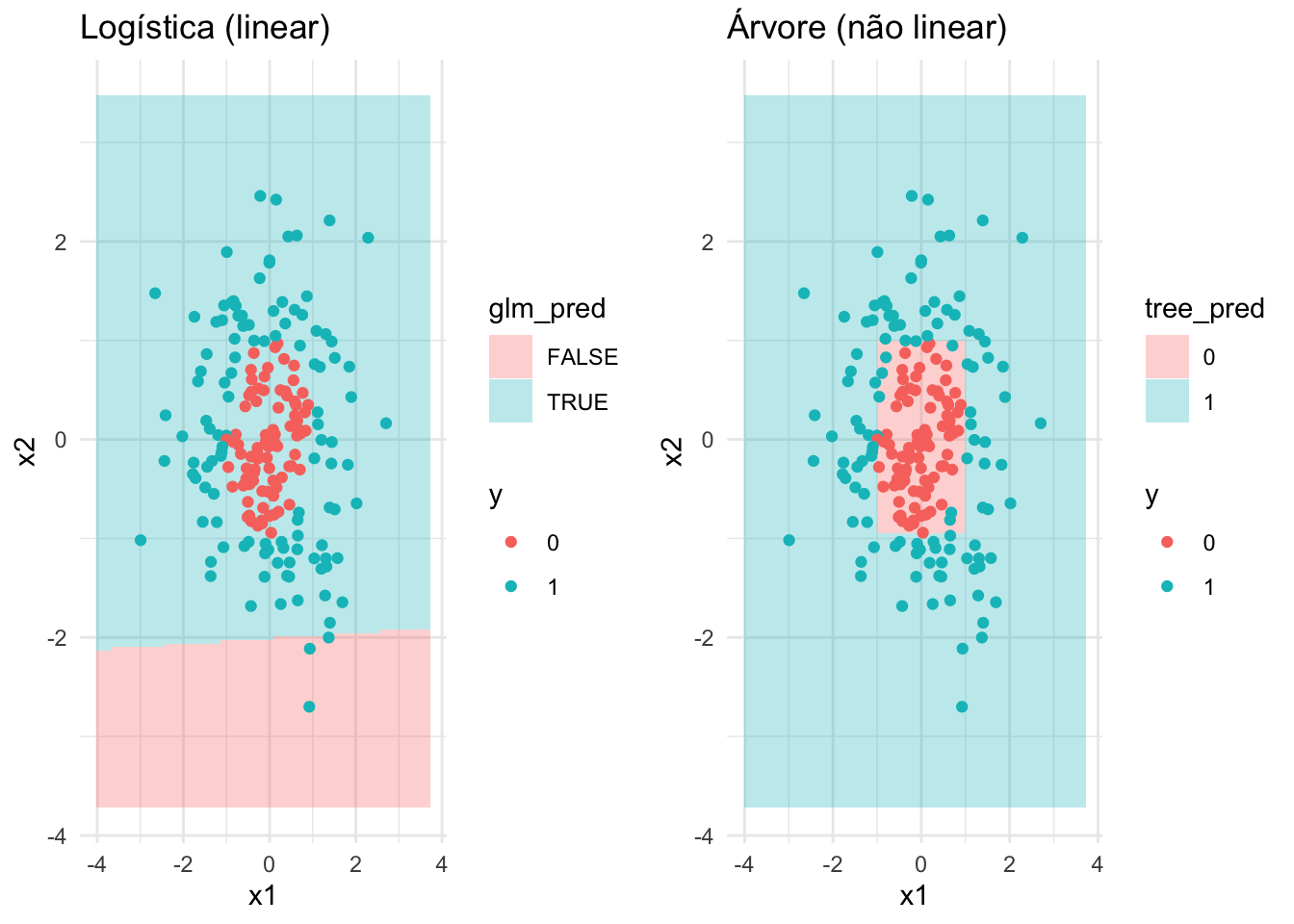
Figura 50.5: Comparação entre modelos de regressão logística e árvore de decisão.
O pacote h2o423 fornece funções construir modelos de aprendizado de máquina.
O pacote correctR399 fornece as funções kfold_ttest, repkfold_ttest e resampled_ttest para calcular estatística para comparação de modelos de aprendizado de máquina em amostras dependentes.
O pacote caret424 fornece um conjunto de funções para pré-processamento, ajuste, avaliação e comparação de modelos de aprendizado de máquina.
O pacote mlr3425 fornece funções para fluxos de trabalho complexos, incluindo pré-processamento, ajuste de hiperparâmetros e integração com diversos algoritmos.
50.11 K-means Clustering
50.11.1 O que é K-means clustering?
O k-means clustering é um algoritmo de aprendizado não supervisionado utilizado para particionar um conjunto de dados em \(k\) grupos, de modo que observações dentro do mesmo grupo apresentem maior similaridade entre si do que em relação às observações de outros grupos.426
O método pode ser interpretado como um problema de quantização de dados, no qual se busca representar um conjunto de \(N\) observações em um espaço vetorial \(d\) d-dimensional por meio de \(k\) centros ou centroides.426
O objetivo do algoritmo é minimizar a soma dos quadrados das distâncias entre cada ponto e o centroide do cluster ao qual pertence, conhecida como within-cluster sum of squares (\(WCSS\)) ou sum of squared errors (\(SSE\)).426
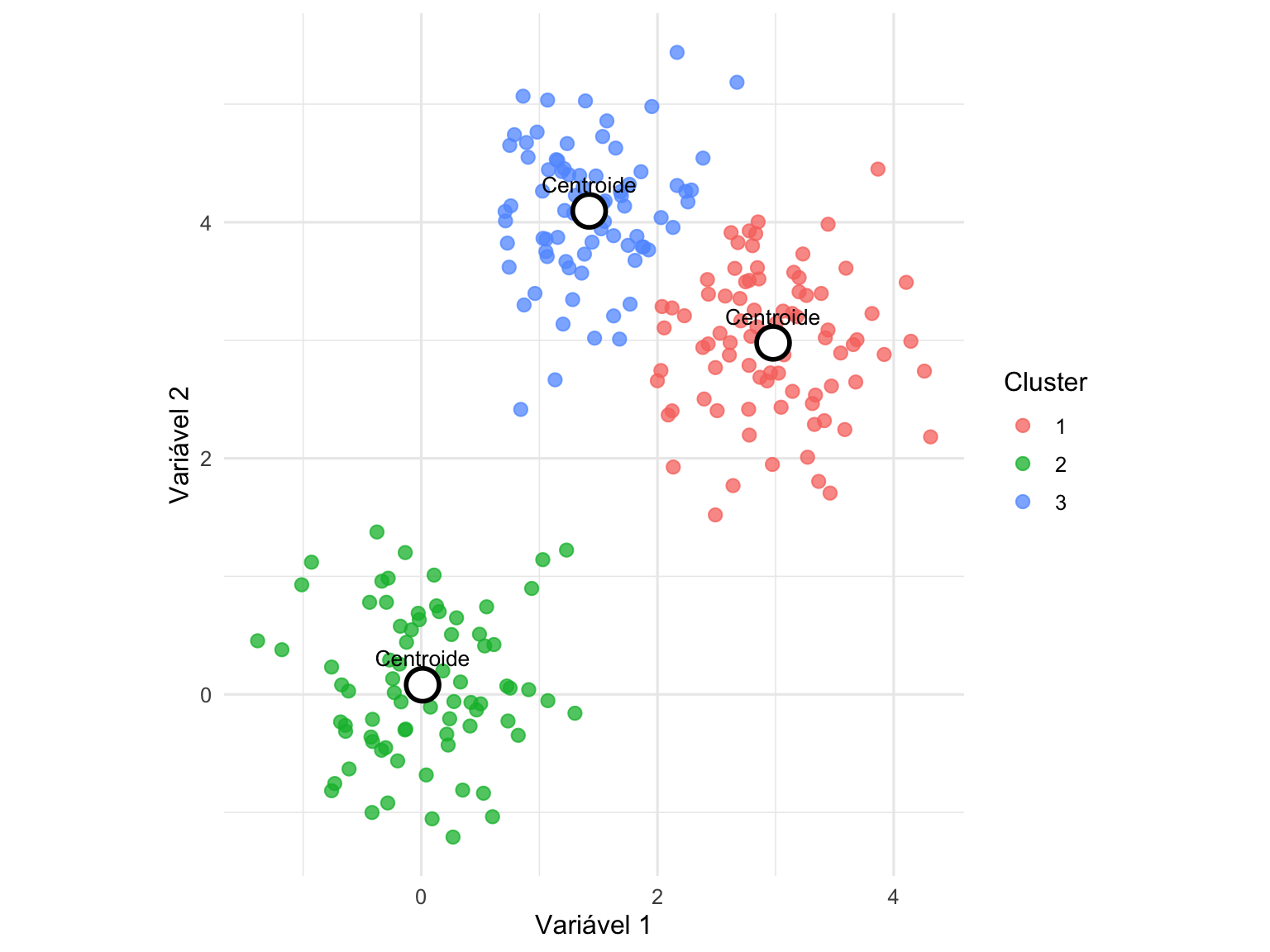
Figura 50.6: Aplicação do algoritmo k-means para identificar grupos em um conjunto de dados bidimensional.
50.11.2 Existe um número ótimo de clusters?
Diferentemente de muitos problemas de aprendizado supervisionado, não existe necessariamente um único número correto de clusters.426
A análise de clusters deve ser vista como uma técnica exploratória, na qual diferentes soluções podem revelar estruturas relevantes em diferentes níveis de granularidade.426
A escolha do número de clusters deve considerar não apenas critérios quantitativos, mas também interpretação substantiva e conhecimento do domínio.426
50.11.3 Como escolher o número de clusters?
Um dos principais desafios na aplicação do algoritmo k-means é determinar o número apropriado de clusters \(k\), uma vez que esse parâmetro precisa ser especificado antes da execução do algoritmo.426
O algoritmo busca minimizar a soma dos quadrados das distâncias entre cada observação e o centroide do cluster mais próximo, conhecida como soma dos quadrados dentro dos clusters (within-cluster sum of squares, \(WCSS\) ou \(SSE\)).426
Como o valor da \(SSE\) tende a diminuir conforme aumenta o número de clusters, torna-se necessário utilizar algum critério para identificar um valor de \(k\) que represente uma boa estrutura nos dados.426
50.11.4 Por que o método do “cotovelo” pode ser problemático?
O método do cotovelo (elbow method) consiste em plotar a \(SSE\) em função do número de clusters e escolher o ponto em que ocorre uma mudança abrupta na inclinação da curva.426
A intuição é que, após certo número de clusters, o ganho em redução do erro passa a apresentar retornos decrescentes.426
Entretanto, curvas semelhantes podem surgir mesmo quando os dados não possuem estrutura de clusters real.426
Em muitos conjuntos de dados reais, o ponto de “cotovelo” não é claramente identificável, o que torna a escolha subjetiva.426
- Diferentes heurísticas para detectar automaticamente o cotovelo frequentemente produzem resultados inconsistentes ou dependentes da escala dos dados.426
50.12 Análise de componentes principais
50.12.1 O que é análise de componentes principais?
A análise de componentes principais é uma técnica estatística amplamente utilizada para redução de dimensionalidade, para representar dados de alta dimensão por um conjunto menor de variáveis, preservando o máximo possível da variabilidade original.427
O primeiro componente principal é definido como a direção, de comprimento unitário, que maximiza a variância dos dados projetados. Ele corresponde ao eixo ao longo do qual os dados apresentam a maior dispersão, concentrando a maior quantidade de informação estatística disponível.427
O segundo componente principal é a direção que maximiza a variância restante, sob a condição de ser ortogonal ao primeiro componente. Essa restrição garante que cada novo componente adicione informação nova, não redundante, à representação dos dados.427
Esse procedimento é repetido para os componentes subsequentes, de forma que cada componente principal seja ortogonal aos anteriores e capture a maior variância possível ainda não explicada, resultando em uma ordenação natural dos componentes por importância.427
A análise de componentes principais produz uma base ortogonal que impõe uma geometria específica à representação dos dados, restringindo a forma como os dados podem ser reconstruídos a partir dos componentes principais.427
Embora os componentes principais descrevam de maneira eficiente a variabilidade dos dados, eles nem sempre correspondem aos fatores geradores subjacentes do fenômeno estudado.427
A análise de componentes principais pode ainda introduzir padrões artificiais, criando uma aparência de estrutura que não reflete necessariamente os processos reais de geração dos dados.427
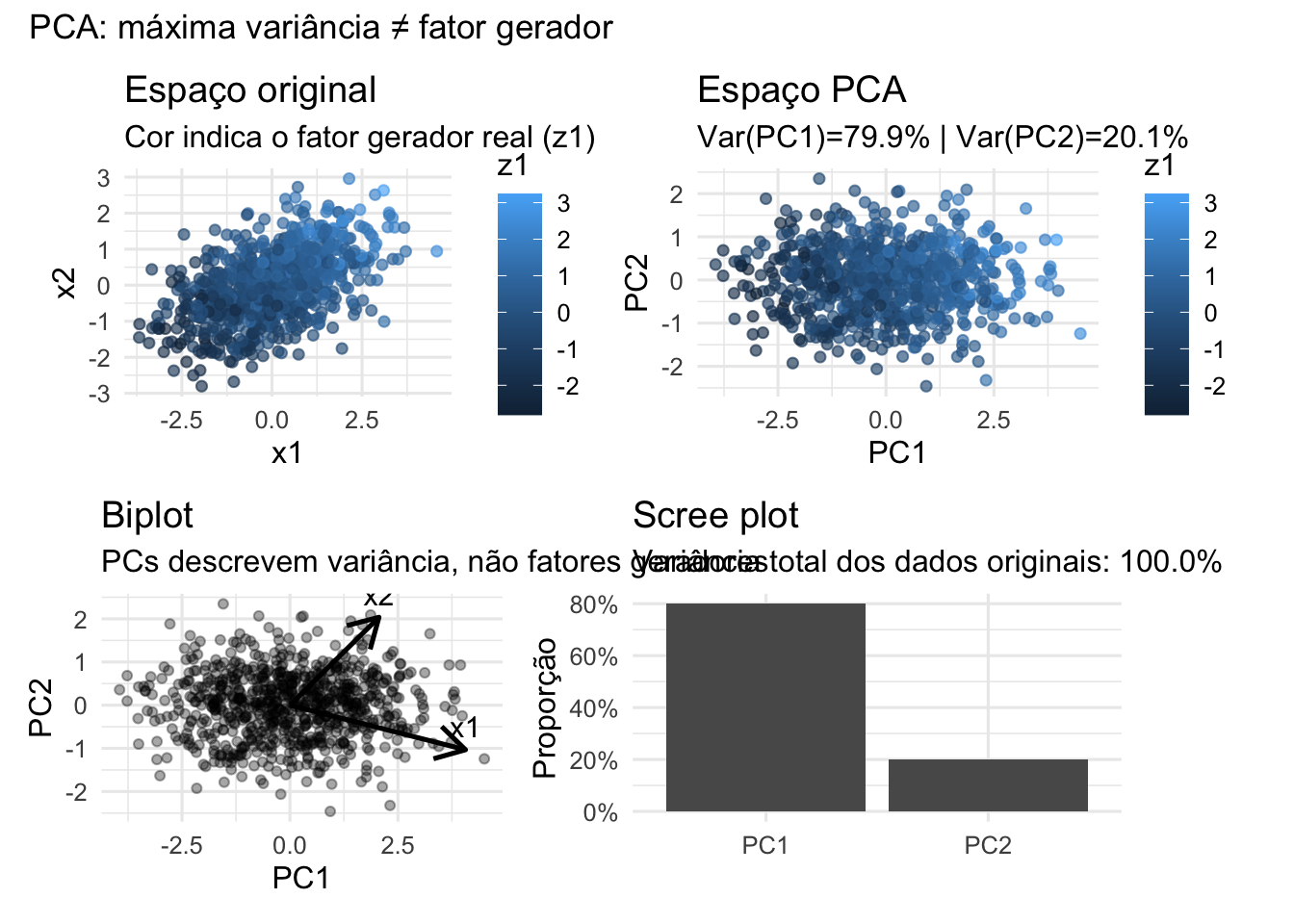
Figura 50.7: Análise de Componentes Principais (PCA). O PC1 maximiza variância total, mas pode não alinhar com o fator latente real (z1).
O pacote mlr3425 fornece funções para fluxos de trabalho complexos, incluindo pré-processamento, ajuste de hiperparâmetros e integração com diversos algoritmos.
50.13 Métricas de distância e similaridade
50.13.1 O que é uma métrica?
- Uma métrica é uma função que quantifica a distância entre dois objetos em um espaço vetorial, obedecendo propriedades como não-negatividade, identidade, simetria e desigualdade triangular.REF?
50.13.2 Quais são as principais métricas?
\[\begin{equation} \tag{50.1} d(x, y) = \sum_{i=1}^{n} |x_i - y_i| \end{equation}\]
- Distância Euclidiana (50.2): raiz quadrada da soma dos quadrados das diferenças entre as coordenadas dos pontos.REF?
\[\begin{equation} \tag{50.2} d(x, y) = \sqrt{\sum_{i=1}^{n} (x_i - y_i)^2} \end{equation}\]
- Distância Minkowski: (50.3): generalização das distâncias de Manhattan e Euclidiana, onde o parâmetro \(p\) determina a ordem da métrica. Para \(p=1\), é equivalente à distância de Manhattan; para \(p=2\), é equivalente à distância Euclidiana.REF?
\[\begin{equation} \tag{50.3} d(x, y) = \left( \sum_{i=1}^{n} |x_i - y_i|^p \right)^{\frac{1}{p}} \end{equation}\]
- Distância Chebyshev (50.4): máximo das diferenças absolutas entre as coordenadas dos pontos, representando a distância em um espaço onde o movimento é permitido em todas as direções.REF?
\[\begin{equation} \tag{50.4} d(x, y) = \max_{i} |x_i - y_i| \end{equation}\]
- Similaridade cosseno (50.5): medida de similaridade entre dois vetores que calcula o cosseno do ângulo entre eles, variando de -1 (totalmente opostos) a 1 (totalmente semelhantes).REF?
\[\begin{equation} \tag{50.5} \text{similaridade}(x, y) = \frac{x \cdot y}{\|x\| \|y\|} \end{equation}\]
- Distância de Hamming (50.6): número de posições em que os símbolos correspondentes de duas sequências de igual comprimento são diferentes, frequentemente usada para medir a diferença entre strings ou códigos binários.REF?
\[\begin{equation} \tag{50.6} d(x, y) = \sum_{i=1}^{n} \mathbf{1}(x_i \neq y_i) \end{equation}\]
- Índice de Jaccard (50.7): medida de similaridade entre conjuntos, calculada como a razão entre a interseção e a união dos conjuntos, variando de 0 (sem elementos em comum) a 1 (conjuntos idênticos).REF?
\[\begin{equation} \tag{50.7} \text{similaridade}(A, B) = \frac{|A \cap B|}{|A \cup B|} \end{equation}\]
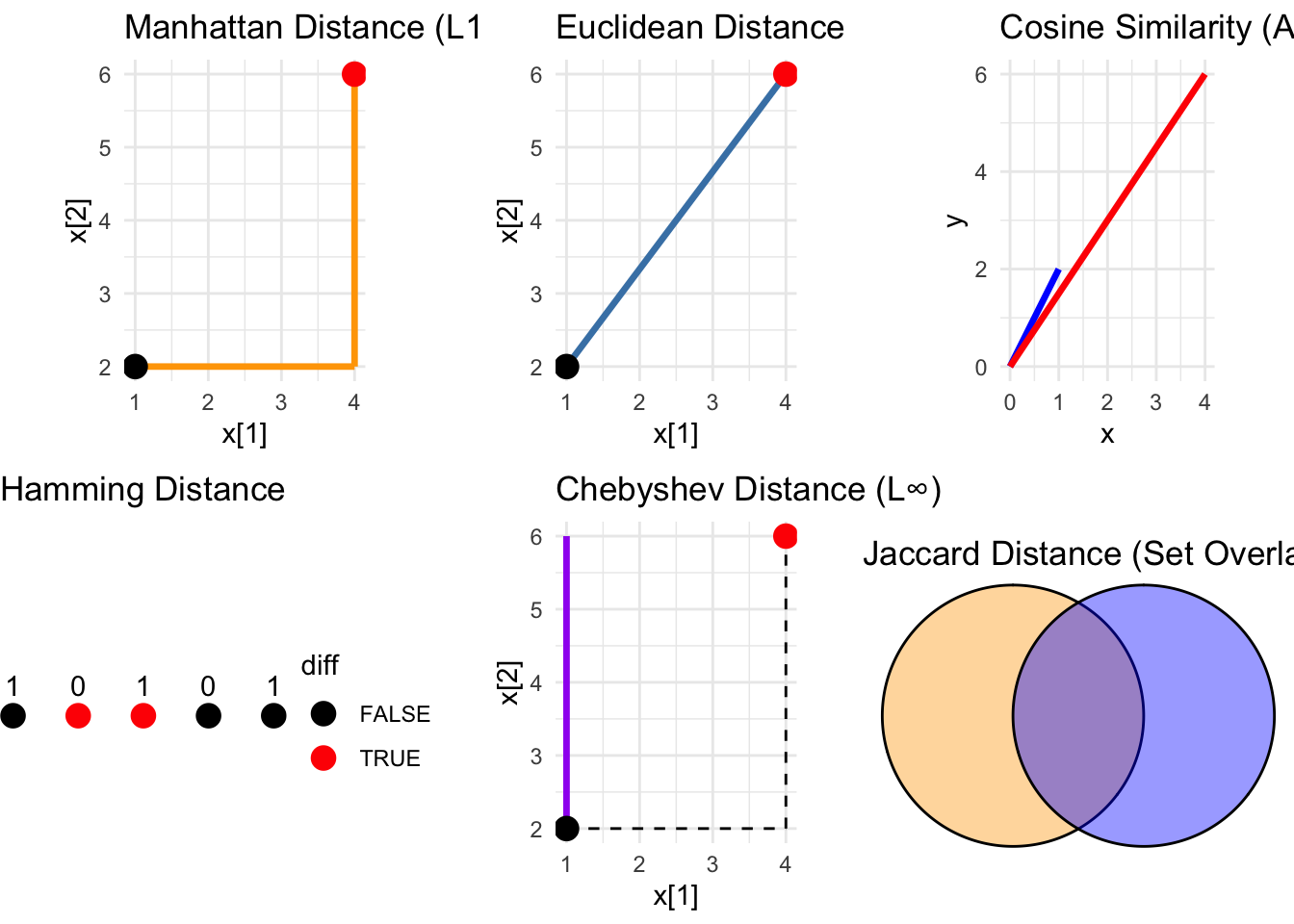
Figura 50.8: Visualização de diferentes métricas de distância e similaridade.
50.13.3 Como escolher a métrica adequada?
- A escolha da métrica depende do tipo de dados (contínuos, categóricos, binários), da escala das variáveis, da presença de outliers e do objetivo da análise (agrupamento, classificação, etc.).REF?
50.13.4 Quais métricas são indicadas para avaliar modelos preditivos?
A área sob a curva ROC (AUROC) como medida de discriminação.428,429
Um gráfico de calibração para avaliar a concordância entre probabilidades estimadas e proporções observadas.428,429
Uma medida de utilidade clínica como o net benefit por meio de decision curve analysis.428,429
Um gráfico que mostre a distribuição das probabilidades preditas por categoria de desfecho.428,429
50.13.5 Quais métricas são consideradas inadequadas?
Todas as métricas puramente baseadas em classificação dependente de limiar são consideradas impróprias para limiares clinicamente relevantes, exceto quando o limiar é 0,5 ou igual à prevalência verdadeira.428
Métricas derivadas da matriz de confusão não devem ser usadas isoladamente como critério principal de avaliação, pois dependem da escolha do limiar e não refletem diretamente a utilidade, especialmente em cenários com dados desbalanceados.428
O F-score \(F_{\beta}\) pode produzir classificações de modelos inconsistentes com a utilidade clínica, favorecendo modelos menos úteis em cenários reais de decisão médica.429
O F-score \(F_{\beta}\) exige a dicotomização das probabilidades preditas, o que é indesejável em modelos, já que a tomada de decisão frequentemente depende de uma faixa contínua de riscos e de limiares que variam entre indivíduos e contextos.429
O F1-score (\(F1\)) é explicitamente desencorajado como métrica principal porque não tem um foco claro em desempenho estatístico e é uma medida inadequada dentro de sua própria categoria conceitual.428
50.14 Avaliação de modelos de classificação
50.14.1 Por que é importante avaliar o desempenho de classificação?
Para evitar estimativas otimistas de desempenho, modelos devem ser avaliados em dados que não foram utilizados durante o treinamento.419
Essa separação entre dados de treinamento e validação permite estimar a capacidade de generalização do algoritmo em novos dados.419
50.14.2 O que é uma matriz de confusão 2x2?
A matriz de confusão é uma tabela de contingência 2×2 utilizada para avaliar o desempenho de um classificador binário, comparando as classes verdadeiras observadas com as classes previstas pelo modelo.430
Em aprendizado supervisionado, ela permite decompor os erros de classificação e analisar como o modelo se comporta em relação a cada classe.430
50.14.3 Como interpretar uma matriz de confusão 2x2?
Verdadeiro-positivo (\(VP\)): instância cuja classe verdadeira é positiva e foi corretamente classificada como positiva.430
Falso-negativo (\(FN\)): instância positiva que foi incorretamente classificada como negativa.430
Verdadeiro-negativo (\(VN\)): instância negativa corretamente classificada como negativa.430
Falso-positivo (\(FP\)): instância negativa incorretamente classificada como positiva.430
| Classe predita correta | Classe predita incorreta | Total | |
|---|---|---|---|
| Classe verdadeira correta | \(VP\) | \(FP\) | \(VP+FP\) |
| Classe verdadeira incorreta | \(FN\) | \(VN\) | \(FN+VN\) |
| Total | \(VP+FN\) | \(FP+VN\) | \(N=VP+VN+FP+FN\) |
50.14.4 Quais métricas caracterizam o desempenho de um classificador?
- Acurácia (\(ACU\)) (50.8): Proporção de classificações corretas (verdadeiros-positivos e verdadeiros-negativos) em relação ao total de casos.430
\[\begin{equation} \tag{50.8} ACU = \dfrac{VP + VN}{VP + FN + VN + FP} \end{equation}\]
- Precisão (\(PRE\)) (50.9): Proporção de verdadeiro-positivos dentre aqueles classificados como positivos.430
\[\begin{equation} \tag{50.9} PRE = \dfrac{VP}{VP + FP} \end{equation}\]
- Revocação (\(REV\)) (50.10): Proporção de verdadeiro-positivos dentre aqueles com a condição, equivalente à sensibilidade.430
\[\begin{equation} \tag{50.10} REV = \dfrac{VP}{VP + FN} \end{equation}\]
- F-beta score (\(F_{\beta}\)) (50.11): Média harmônica ponderada entre precisão e revocação, onde \(\beta < 1\) prioriza precisão (\(PRE\)) e \(\beta > 1\) prioriza sensibilidade \(SEN\) ou \(REV\).429
\[\begin{equation} \tag{50.11} F_{\beta} = \dfrac{(1+\beta^{2}) \times TP}{(1+\beta^{2}) \times TP + \beta^{2} \times FN + FP} \end{equation}\]
- F1-score (\(F1\)) (50.12): Média harmônica entre precisão e revocação, balanceando ambos os aspectos do desempenho (\(\beta = 1\)).430
\[\begin{equation} \tag{50.12} F1 = 2 \times \dfrac{PRE \times REV}{PRE + REV} \end{equation}\]
50.15 Baselines em classificação
50.15.1 O que são baselines?
- Baselines são modelos extremamente simples que ignoram as variáveis preditoras e produzem previsões com base apenas na distribuição das classes ou em estratégias aleatórias simples.431
50.15.2 Por que é necessário comparar classificadores com um baseline?
A avaliação de um classificador requer a comparação com um nível mínimo de desempenho esperado, denominado baseline.431
O objetivo de um baseline é estabelecer um ponto de referência para determinar se um modelo preditivo realmente apresenta desempenho superior ao acaso ou a estratégias triviais.431
Sem essa referência, métricas aparentemente altas podem ser enganosas, especialmente em conjuntos de dados com desbalanceamento de classes.431
50.15.3 Quais são os principais classificadores baseline?
Baselines baseados em aleatoriedade produzem distribuições de desempenho (por exemplo, acurácia média próxima de 0,5 em classificação binária), de modo que a superioridade de um modelo deve ser avaliada em relação à variabilidade esperada desses valores.431
Esses modelos ignoram completamente as variáveis preditoras e, portanto, representam estratégias mínimas de classificação.431
Predição aleatória uniforme (uniform random): cada classe é prevista com igual probabilidade, independentemente da distribuição observada nos dados.431
Predição aleatória proporcional (proportional random): as classes são previstas aleatoriamente, mas respeitando as proporções observadas no conjunto de treinamento.431
Predição da classe mais frequente (most frequent): o modelo sempre prevê a classe mais comum no conjunto de dados.431
50.15.4 Como o desbalanceamento de classes afeta o baseline?
Em conjuntos de dados balanceados, os baselines uniforme e proporcional tendem a apresentar desempenho semelhante.431
Em dados desbalanceados, o baseline proporcional frequentemente apresenta maior acurácia e especificidade, mas sensibilidade muito baixa para a classe minoritária.431
O baseline da classe mais frequente pode apresentar acurácia elevada mesmo sem qualquer capacidade real de discriminação.431
Por isso, métricas devem sempre ser interpretadas em relação ao desempenho esperado de um baseline apropriado.431
50.15.5 Como usar baselines na avaliação de modelos?
O desempenho de um classificador deve ser considerado relevante apenas quando supera claramente o desempenho esperado do baseline.431
Em dados desbalanceados, o baseline proporcional geralmente é o mais adequado, pois incorpora a distribuição real das classes.431
Em aplicações com eventos raros, pode ser apropriado utilizar o baseline da classe mais frequente como referência prática.431
Em alguns casos, pode-se avaliar a distribuição de desempenho do baseline por simulação para determinar limiares estatisticamente superiores ao acaso.431
50.16 Desbalanceamento de classes
50.16.1 O que é desbalanceamento de classes?
- Ocorre quando as classes do desfecho (por exemplo, presença vs. ausência de um evento) não estão igualmente representadas nos dados de treinamento.REF?
50.16.2 Por que o desbalanceamento de classes é um problema?
Modelos podem aprender a priorizar a classe mais frequente, obtendo alta acurácia global, mas baixo desempenho para a classe minoritária.REF?
Isso pode comprometer métricas como sensibilidade, especificidade e, em alguns casos, a calibração.REF?
50.16.3 Como lidar com desbalanceamento de classes?
Reamostragem aleatória: superamostragem da classe minoritária; subamostragem da classe majoritária).REF?
Ajuste de pesos: penaliza mais os erros na classe menos frequente.REF?
Alteração do limiar de decisão: muda o ponto de corte de probabilidade para otimizar métricas específicas.REF?
50.16.4 O desbalanceamento de classes afeta a calibração de modelos?
Corrigir o desbalanceamento de classes nem sempre melhora a calibração e, em alguns casos, pode piorá-la.432
Em simulações computacionais, modelos sem correção tiveram calibração igual ou superior aos corrigidos.432
A piora observada foi caracterizada por superestimação do risco, nem sempre reversível com re-calibração.432
Ferreira, Arthur de Sá. Ciência com R: Perguntas e respostas para pesquisadores e analistas de dados. Rio de Janeiro: 1a edição,