Capítulo 54 Tamanho da amostra
54.1 Tamanho da amostra
54.1.1 O que é tamanho da amostra?
Tamanho da amostra \(n\) é a quantidade de participantes (ou unidades de análise) necessárias para conduzir um estudo a fim de testar uma hipótese.449
O cálculo do tamanho da amostra depende de quatro pilares interligados — tamanho de efeito esperado, variabilidade, nível de significância (\(\alpha\)) e poder (\(1-\beta\)) — cuja combinação determina o \(n\) necessário para detectar efeitos de interesse com precisão adequada.47
Em estudos de métodos mistos, o tamanho amostral não é único nem determinado por um único critério. Componentes quantitativos seguem lógica inferencial (poder estatístico), enquanto componentes qualitativos seguem lógica informacional (saturação, variação relevante).40
54.1.2 Por que determinar o tamanho da amostra é importante?
É virtualmente impossível, devido a limitações de recursos — tempo, acesso, custo, dentre outros — coletar dados da população completa.60
Uma amostra muito pequena para o estudo pode resultar em ajuste exagerado, imprecisão e baixo poder do teste.161
54.1.3 Quais fatores devem ser considerados para determinar o tamanho da amostra?
Tamanho da população (\(N\)): O tamanho da amostra depende parcialmente do tamanho da população de origem. Geralmente assume-se que a população tem tamanho desconhecido ou infinito.449
Em estudos com amostras de populações de tamanho finito (inferior a 100.000 indivíduos), geralmente em pesquisas descritivas, esse tamanho deve ser incorporado nos cálculos.449
Delineamento do estudo.449
Quantidade e características (dependente vs. independente) dos grupos de participantes do estudo.449
Erros tipo I (\(\alpha\)) e tipo II (\(\beta\)).449
Tipo de variável a ser observada (contínua, intervalo, ordinal, nominal, dicotômica).449
Tamanho de efeito mínimo a ser observado.449
Variabilidade da(s) variável(eis) coletada(s).449
Lateralidade do teste de hipótese (unicaudais ou bicaudais).449
Perdas de dados durante a coleta e/ou acompanhamento dos participantes do estudo.449
O pacote pwr346 fornece a função plot.power.htest para apresentar graficamente a relação entre o tamanho da amostra e o poder de testes de hipóteses.
54.1.4 Quais aspectos éticos estão envolvidos no tamanho da amostra?
Determinar a priori o tamanho da amostra pode diminuir o risco de realizar testes ou intervenções desnecessários, desperdício de recursos associados e de coletar dados insuficientes para testar as hipóteses do estudo.449
O tratamento ético dos participantes do estudo, portanto, não exige que se considere se o poder do estudo é inferior à meta convencional de 80% ou 90%.450
Estudos com poder <80% não são necessariamente antiéticos.450
Metas convencionais de poder (80–90%) são guias pragmáticos e não regras morais rígidas; estudos com poder <80% não são automaticamente antiéticos quando bem justificados.450
Grandes estudos podem ser desejáveis por outras razões que não as éticas.450
54.2 Saturação em pesquisas qualitativas
54.2.1 O que é saturação de dados em pesquisas qualitativas?
Saturação é o ponto em que a coleta de dados não produz novas informações, categorias ou temas, indicando que o fenômeno investigado já foi suficientemente explorado.451
Essa noção surgiu na teoria fundamentada com o termo “saturação teórica”, mas hoje é amplamente usada em diferentes tradições qualitativas, incluindo fenomenologia, etnografia e análise temática.452
54.2.2 Quais tipos de saturação existem?
Saturação de códigos: ocorre quando não emergem novos códigos relevantes nos dados452
Saturação de significados: atinge-se quando a profundidade e a variação dos significados de um tema foram plenamente exploradas.452
Saturação teórica: quando categorias estão suficientemente desenvolvidas e suas relações esclarecidas.451
Saturação de metatemas: em pesquisas multicêntricas, quando os grandes temas transversais já foram identificados.453
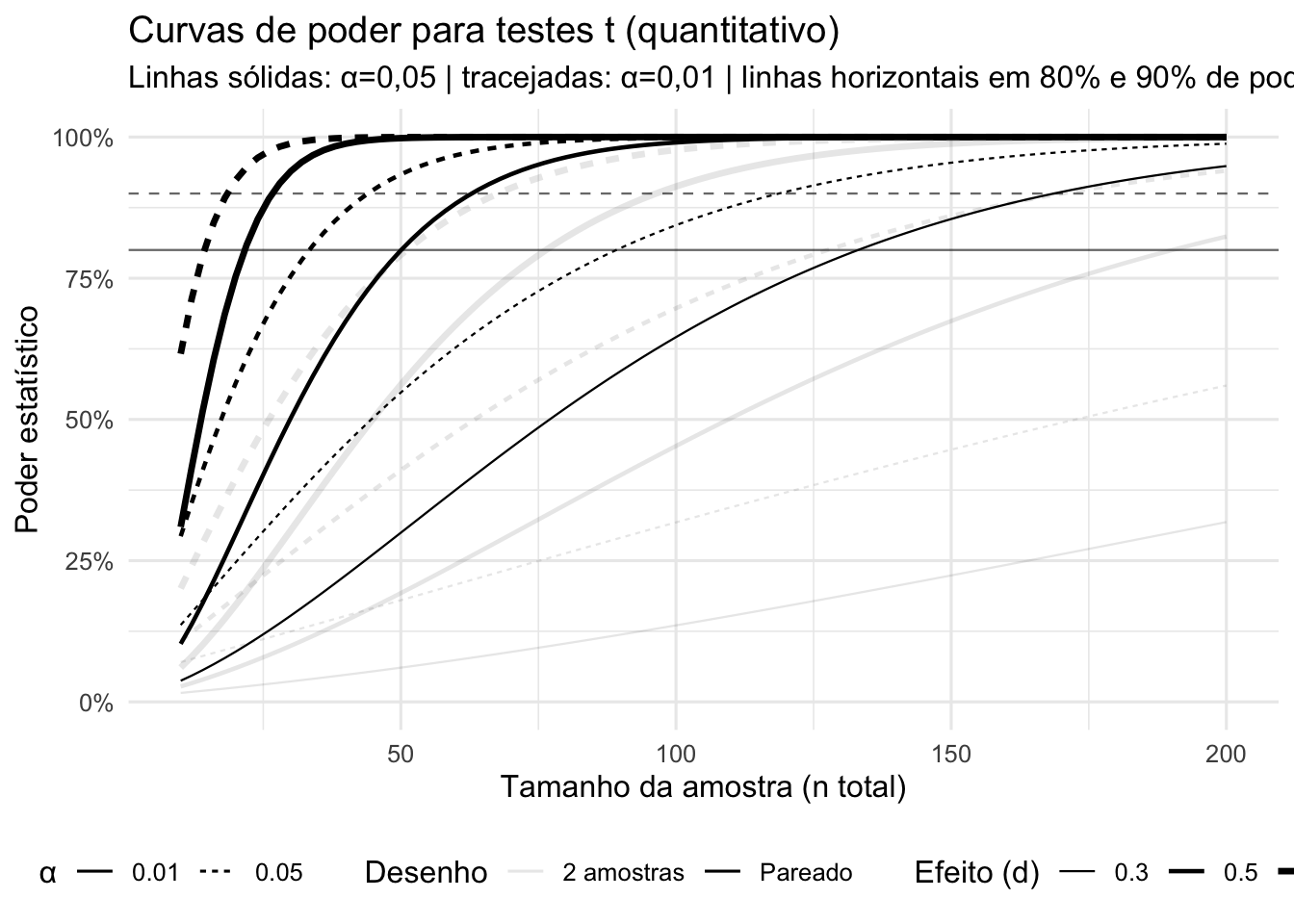
Figura 54.1: Curvas de poder para testes t (quantitativo). Linhas sólidas: \(\alpha = 0,05\) | tracejadas: \(\alpha = 0,01\) | linhas horizontais em 80% e 90% de poder.
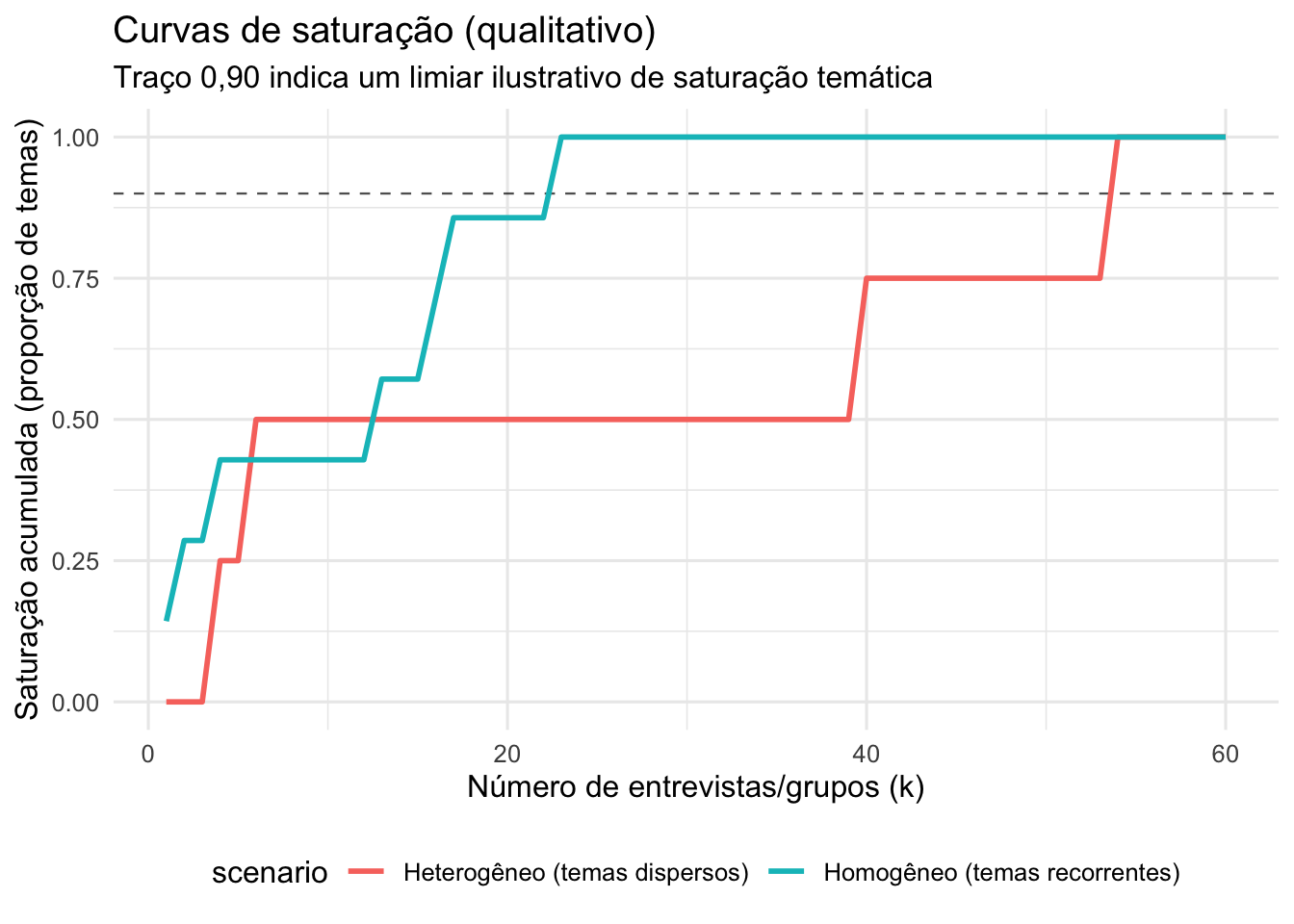
Figura 54.2: Curvas de saturação para estudos qualitativos de descoberta de temas.
54.2.3 Quantas entrevistas ou grupos focais são necessários para alcançar saturação?
Estudos empíricos mostram que a saturação de códigos pode ser atingida com 9 a 17 entrevistas em populações homogêneas e objetivos específicos.452
Para saturação de significados, podem ser necessárias entre 16 e 24 entrevistas.452
Em grupos focais, a saturação temática pode ocorrer com 4 a 8 grupos homogêneos.452
Revisões recentes sugerem que a saturação teórica exige 20 a 30 entrevistas ou mais, dependendo da complexidade do estudo.453
54.2.4 Quais debates existem sobre o conceito de saturação?
Defensores argumentam que a saturação é central para garantir rigor e confiança nos resultados qualitativos.451
Críticos sugerem que o conceito pode ser usado de forma rígida, levando a coletas excessivas ou pouco sensíveis a perspectivas únicas.451
Pesquisadores contemporâneos recomendam usar a saturação de forma flexível, adaptada ao contexto, método e população estudada.453
54.2.5 Quais recomendações para tamanho de amostras de estudos qualitativos?
Para entrevistas individuais: 9–12 entrevistas podem ser suficientes para saturação temática em contextos homogêneos; estudos heterogêneos ou multicêntricos exigem mais casos.452,453
Para grupos focais: 4–8 grupos são geralmente adequados.452
Para estudos multicêntricos: recomenda-se 20–40 entrevistas por local para alcançar saturação de metatemas.453
É importante relatar não apenas o número de entrevistas, mas também como e quando a saturação foi avaliada.454
54.3 “Fome de dados”
54.3.1 O que significa “fome de dados”?
Data hungry descreve a necessidade de um modelo contar com muitos eventos por variável (EPV) para alcançar estabilidade estatística.
Enquanto a regressão logística atinge desempenho estável com cerca de 20–50 EPV, modelos como random forests, redes neurais e máquinas de vetor de suporte podem demandar >200 EPV para reduzir o otimismo e estabilizar o desempenho.
54.3.2 Por que a “fome de dados” é relevante?
Em bases de dados pequenas, modelos clássicos tendem a ser mais robustos e menos suscetíveis a superajuste.375
O uso de modelos modernos só se justifica quando há grandes bases de dados, caso contrário o ganho em acurácia é marginal.375
Esse conceito conecta diretamente a escolha do modelo ao planejamento amostral.375
54.4 Eventos por variável (EPV) em modelos preditivos
54.5 Cálculo do tamanho da amostra
54.5.1 Como calcular o tamanho da amostra?
O tamanho amostral pode ser calculado por meio de fórmulas matemáticas que tendem a assegurar margens de erros tipos I (\(\alpha\)) e II (\(\beta\)) para a estimação dos parâmetros populacionais (tamanho de efeito) a partir dos dados amostrais.449
O tamanho da amostra deve ser calculado para cada um dos objetivos primários e/ou secundários, sendo escolhido o maior tamanho de amostra calculado para o estudo.449
Geralmente é recomendado ser cético em relação às regras práticas para o tamanho da amostra, tais como a proporção entre o número de variáveis (ou eventos) e de participantes.161
54.5.2 Como especificar o tamanho do efeito esperado?
Estudo-piloto — realizados nas mesmas condições do estudo, mas envolvendo um tamanho de amostra limitado — pode ser útil na estimativa do tamanho da amostra a partir do tamanho do efeito estimado.449
Utilizar os limites dos intervalos de confiança de estudos-piloto de ensaios clínicos como estimativa do tamanho do efeito pode aumentar o poder estatístico da análise se comparado ao uso das estimativas pontuais obtidas no mesmo piloto.455
Embora os testes de hipótese considerem efeito nulo para a hipótese nula — ex.: diferença de média (\(H_{0}: \mu_{1} - \mu_{2}=0\)), correlação (\(H_{0}: r=0\)), associação (\(H_{0}: \beta=0\) ou \(H_{0}: OR=1\)) —, em geral é improvável que os efeitos populacionais sejam de fato nulos (isto é, exatamente 0).456
O pacote pwr346 fornece a função pwr.2p.test para cálculo do tamanho da amostra para testes de proporção balanceados (2 amostras com mesmo número de participantes).
O pacote pwr346 fornece a função pwr.2p2n.test para cálculo do tamanho da amostra para testes de proporção não balanceados (2 amostras com diferente número de participantes).
O pacote pwr346 fornece a função pwr.anova.test para cálculo do tamanho da amostra para testes de análise de variância balanceados (3 ou mais amostras com mesmo número de participantes).
O pacote pwr346 fornece a função pwr.chisq.test para cálculo do tamanho da amostra para testes de qui-quadrado \(\chi^2\).
O pacote pwr346 fornece a função pwr.f2.test para cálculo do tamanho da amostra para testes com modelo linear geral.
O pacote pwr346 fornece a função pwr.norm.test para cálculo do tamanho da amostra para a média de uma distribuição normal com variância conhecida.
O pacote pwr346 fornece a função pwr.p.test para cálculo do tamanho da amostra para testes de proporção (1 amostra).
O pacote pwr346 fornece a função pwr.r.test para cálculo do tamanho da amostra para testes de correlação (1 amostra).
O pacote pwr346 fornece a função pwr.t.test para cálculo do tamanho da amostra para testes t de diferença de 1 amostra, 2 amostras dependentes ou 2 amostras independentes (grupos balanceados).
O pacote pwr346 fornece a função pwr.t2n.test para cálculo do tamanho da amostra para testes t de diferença de 2 amostras independentes (grupos não balanceados).
O pacote longpower444 fornece a função power.mmrm para calcular o tamanho da amostra para estudos com análises por modelo linear misto.
54.6 Perdas de amostra
54.6.1 O que é perda de amostra?
Perda de amostra(s) — isto é, participante(s) ou unidade(s) de análise — pode ocorrer durante a coleta e/ou acompanhamento dos participantes do estudo.449
Perda amostral pode ocorrer por: abandono ou desistência do participante, perda de contato com o participante, perda de informação, ocorrência de eventos adversos, morte do participante, entre outros.449
54.6.2 Por que a perda de amostra é um problema?
A perda de amostra reduz o tamanho efetivo de \(n\) e, portanto, o poder estatístico do estudo, elevando a probabilidade de erro tipo II (\(\beta\)).161,449
A atrição diferencial também pode introduzir viés de seleção (ou de atrito), quando as características dos participantes que permanecem diferem sistematicamente das daqueles que se perdem ao seguimento.449
54.6.3 Como evitar perda de amostra?
- A perda de amostra pode ser compensada pelo aumento do tamanho da amostra, desde que o aumento seja suficiente para manter o poder do estudo.449
54.7 Ajustes no tamanho da amostra
54.7.1 Por que ajustar o tamanho da amostra?
- O tamanho da amostra pode ser ajustado durante o estudo para compensar a perda de amostra, desde que o aumento seja suficiente para manter o poder do estudo.449
54.8 Justificativa do tamanho da amostra
54.8.1 Como justificar o tamanho da amostra de um estudo?
Em estudos que envolvem condições raras, pode ser difícil recrutar o número necessário de participantes devido à limitada disponibilidade de casos da população. Mesmo assim, é aconselhável determinar o tamanho da amostra.449
Quando um estudo deste tipo não é possível, as considerações referentes ao tamanho da amostra são justificadas de acordo com o número máximo de pacientes que podem ser recrutados no decorrer do estudo.449
54.8.2 Como justificar o tamanho da amostra em estudos qualitativos?
Pesquisas qualitativas devem apresentar uma justificativa explícita da amostra, relacionando-a à estratégia de coleta, aos objetivos e ao critério de saturação adotado.454
A noção de “poder da informação” (information power) indica que quanto mais relevante e focada é a amostra em relação à pergunta de pesquisa, menor pode ser o número de participantes.454
Relatar claramente o processo de decisão aumenta a transparência e a credibilidade da pesquisa.454
Ferreira, Arthur de Sá. Ciência com R: Perguntas e respostas para pesquisadores e analistas de dados. Rio de Janeiro: 1a edição,