Capítulo 36 Modelos
36.1 Modelos
36.1.1 O que são modelos?
- Modelos são representações simplificadas de um sistema real, usados para entender, prever ou controlar fenômenos complexos.REF?
36.1.2 O que é modelagem?
- Modelagem é o processo de usar dados para selecionar um modelo matemático explícito que represente o processo gerador dos dados.268
36.1.3 Por que a escolha do modelo é complexa?
Há inúmeras combinações possíveis de variáveis, formas funcionais (lineares, quadráticas, transformações), interações e formas do desfecho, o que torna o espaço de possibilidades muito amplo.268
Todos os modelos são errados, mas alguns são úteis.336
O pacote equatiomatic337 fornece a função extract_eq para extrair a equação dos modelos em formato LaTeX para visualização.
36.1.4 O que diferencia modelos clássicos e modernos em predição?
- Modelos clássicos, como a regressão logística e as árvores de decisão, contrastam com os modelos modernos, como máquinas de vetor de suporte, redes neurais e random forests , principalmente pela maior flexibilidade e capacidade destes últimos de capturar não linearidades e interações.338
36.2 Modelos estocásticos
36.2.2 O que são cadeias de Markov?
- As cadeias de Markov descrevem processos em que o estado futuro depende apenas do estado presente, e não da trajetória passada.339
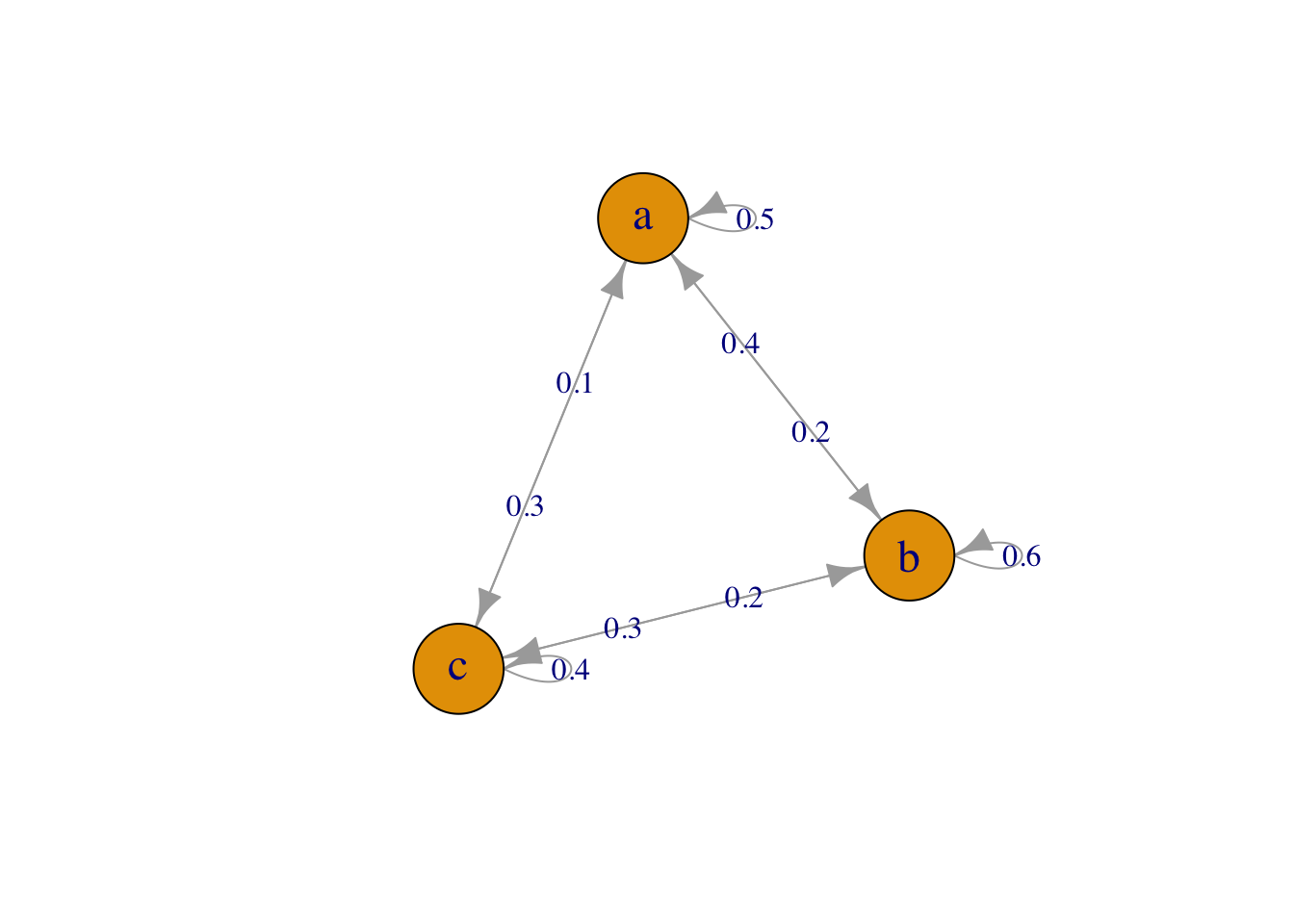
Figura 36.1: Cadeia de Markov com 3 estados (a, b, c) e suas probabilidades de transição.
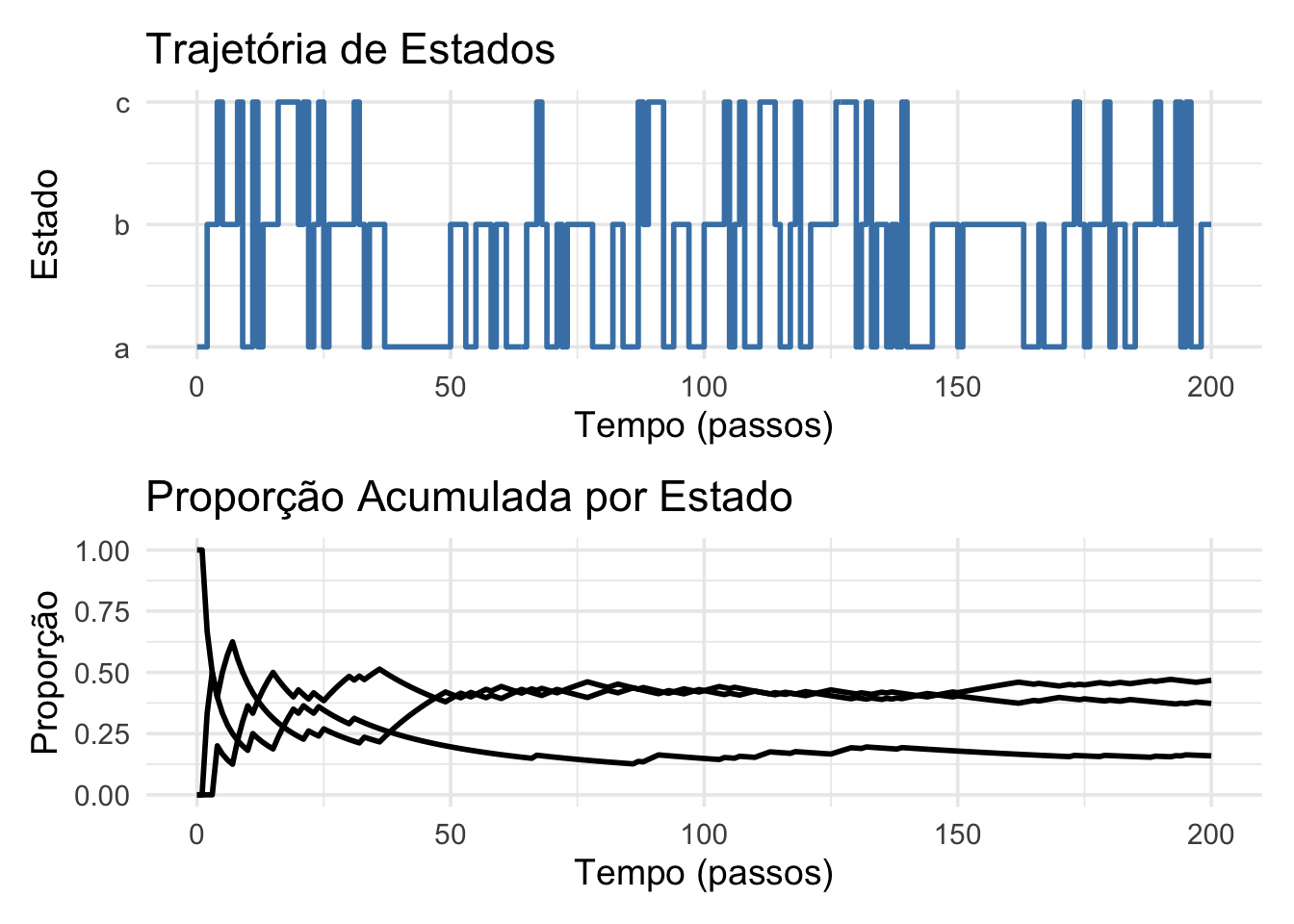
Figura 36.2: Trajetória de estados e proporção acumulada por estado em uma cadeia de Markov com 3 estados (a, b, c).
O pacote markovchain340 fornece a função markovchainFit ajusta uma cadeia com base em dados observados.
36.3 Efeito fixo
36.3.1 O que é efeito fixo?
Efeito fixo é a relação média entre variáveis assumida como igual para todos os grupos ou indivíduos, representando o comportamento populacional esperado.REF?
Ele descreve tendências sistemáticas e reproduzíveis que não dependem de pertencer a um grupo específico.REF?
Em modelos estatísticos, corresponde aos parâmetros estimados globalmente a partir de todos os dados.REF?
36.4 Efeito aleatório
36.4.1 O que é efeito aleatório?
Efeito aleatório representa desvios específicos de grupos ou unidades em relação ao efeito fixo.REF?
Ele modela a variabilidade entre grupos, assumindo que esses desvios são amostras de uma distribuição comum.REF?
Não busca estimar cada grupo isoladamente, mas sim quantificar a variabilidade entre eles.REF?
36.5 Efeito misto
36.5.1 O que é efeito misto?
Um modelo de efeitos mistos combina efeitos fixos e aleatórios em uma única estrutura estatística.REF?
Ele permite estimar tendências globais ao mesmo tempo em que ajusta variações específicas por grupo.REF?
Essa combinação possibilita inferência correta mesmo na presença de heterogeneidade, evitando armadilhas como o Paradoxo de Simpson.REF?
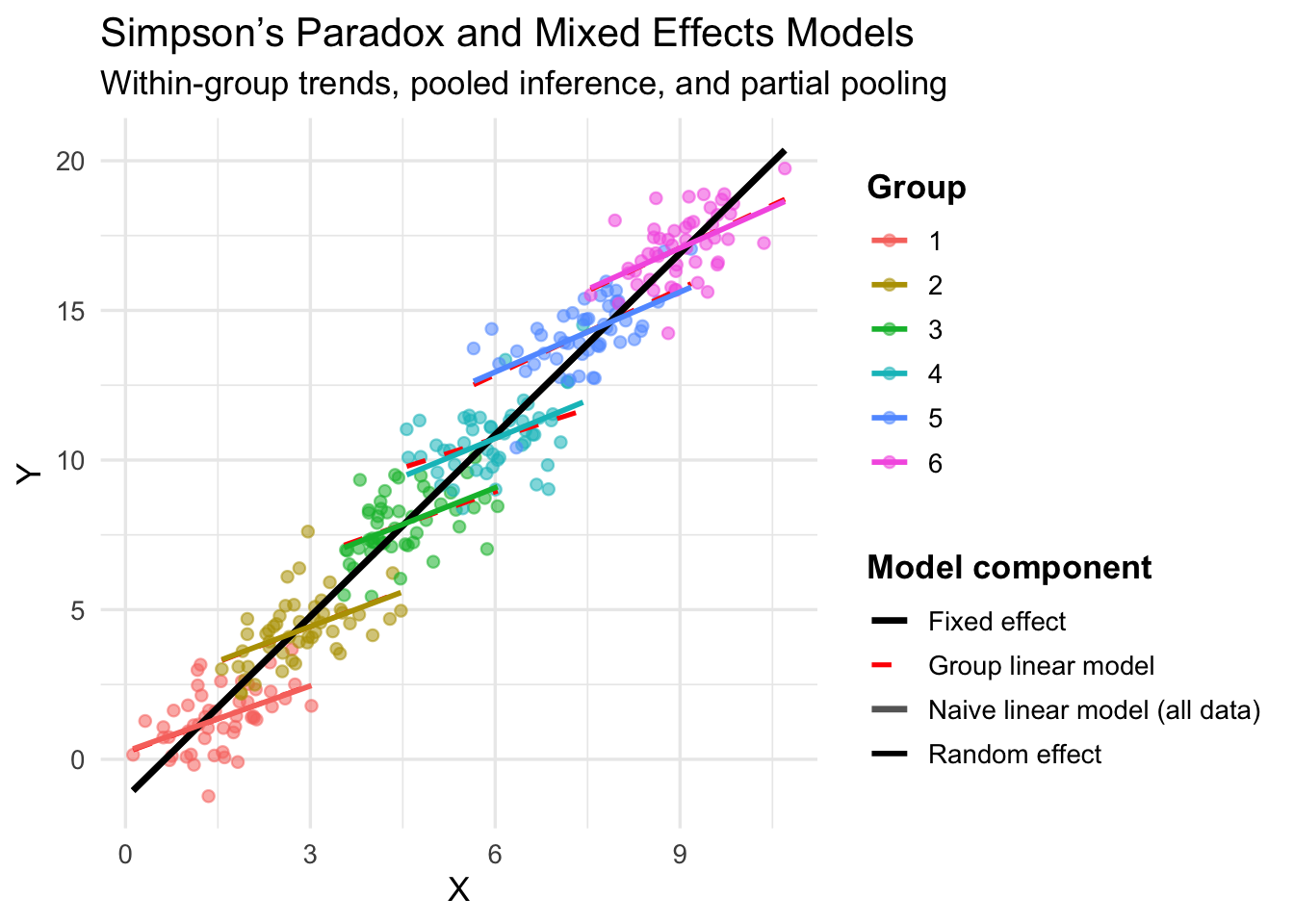
Figura 36.3: Efeitos fixos, aleatórios e mistos em dados simulados com paradoxo de Simpson. As linhas vermelhas representam os efeitos dentro dos grupos, enquanto as linhas cinza e preta representam os efeitos globais (naive e fixo, respectivamente). O modelo misto (linhas coloridas) captura os efeitos dentro dos grupos sem extrapolar além dos dados observados.
36.7 Efeito de interação
36.7.1 O que é efeito de interação?
A interação - representada pelo símbolo * - é o termo estatístico empregado para representar a heterogeneidade de um determinado efeito.342
.341
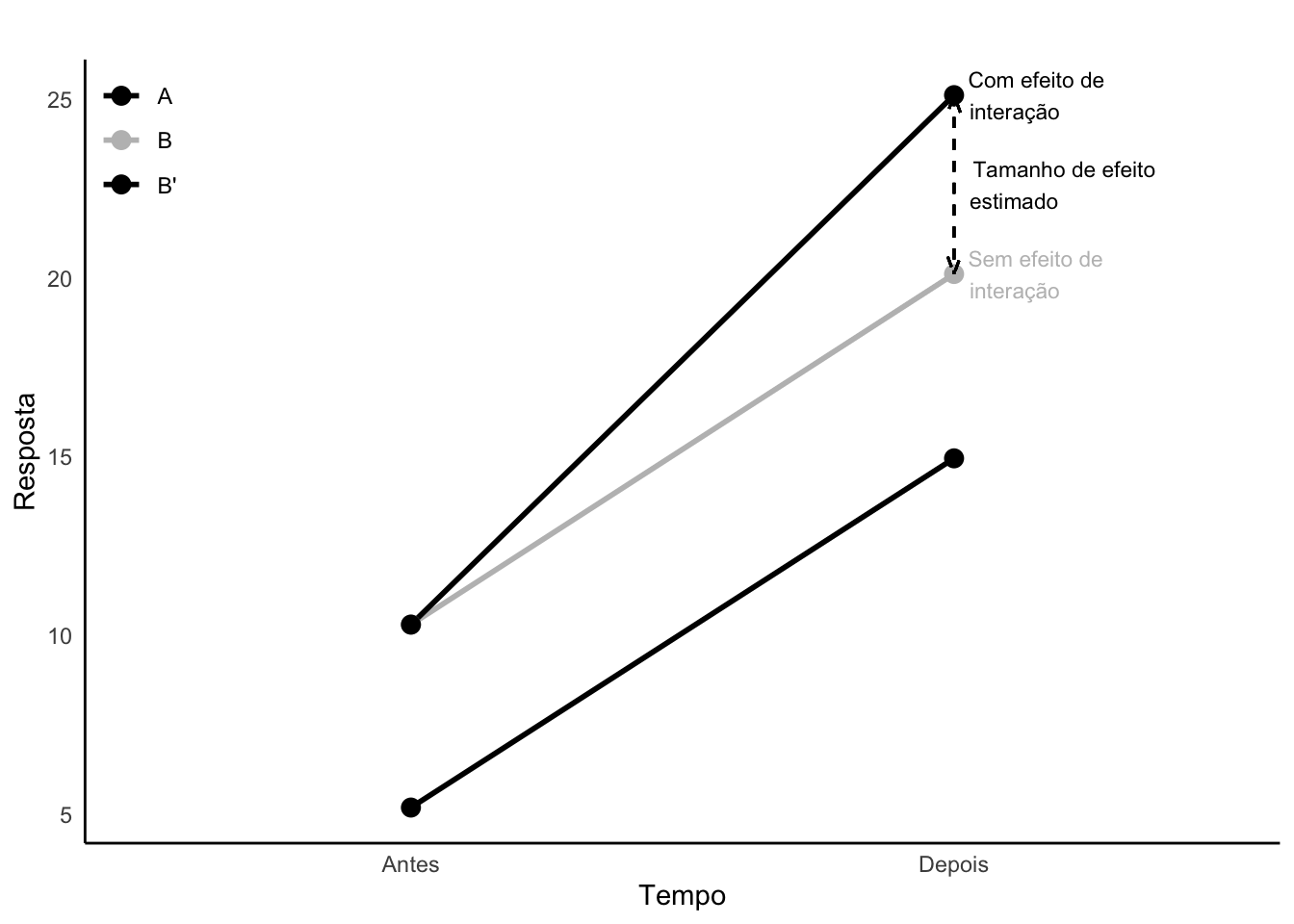
Figura 36.4: Análise de efeito de interação (direta) entre grupos e tempo. Retas paralelas sugerem ausência de efeito de interação.
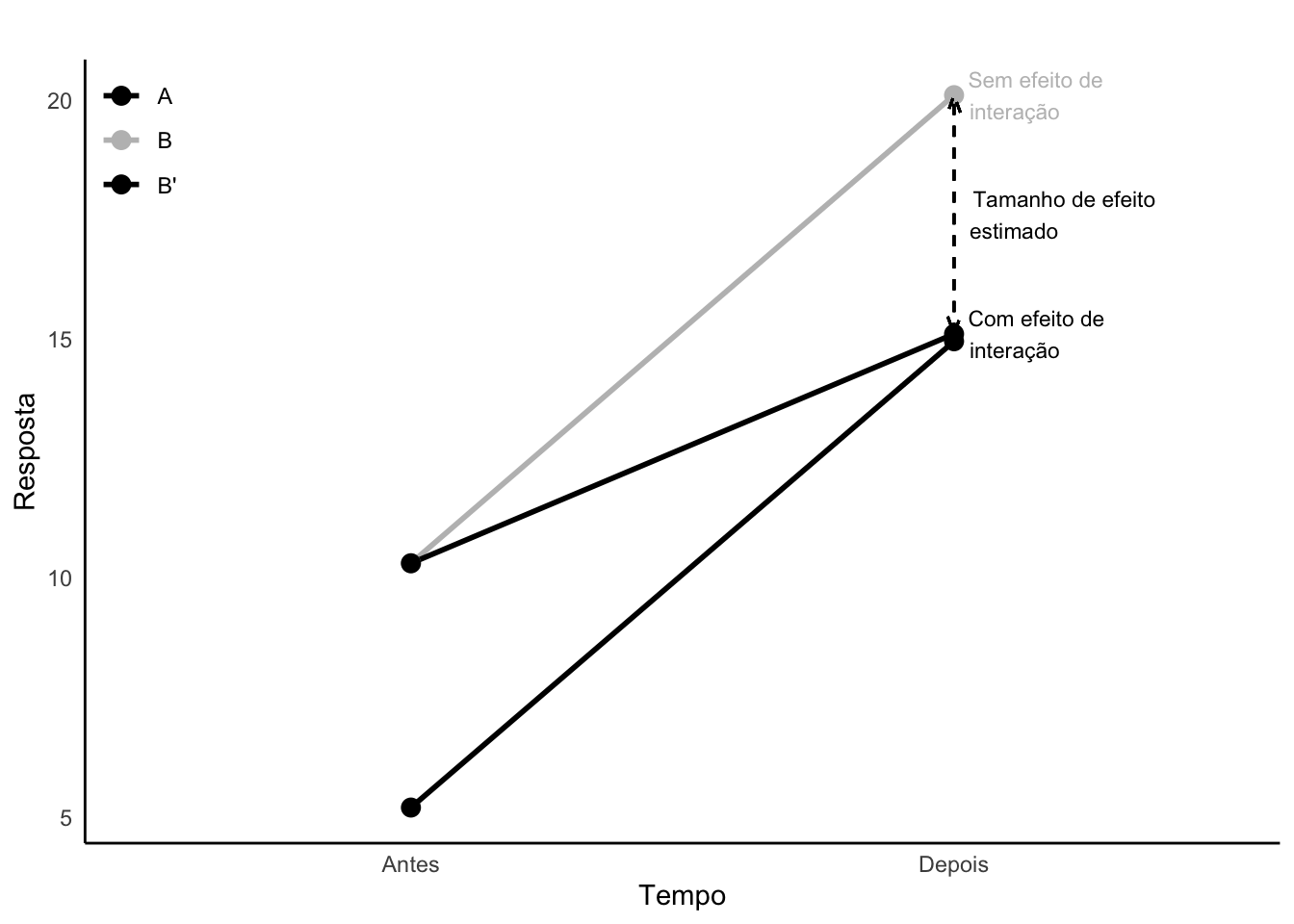
Figura 36.5: Análise de efeito de interação (inversa) entre grupos e tempo. Retas paralelas sugerem ausência de efeito de interação.
O pacote emmeans345 fornece a função emmeans para calcular as médias marginais dos fatores e suas combinações de um modelo de regressão misto linear.
36.11 Desempenho e estabilidade de modelos
36.11.1 Como avaliar o desempenho dos modelos?
Pela área sob a curva ROC em conjunto com o otimismo (diferença entre AUC aparente e validada).338
O desempenho melhora com maior tamanho amostral, mas de forma desigual entre técnicas.338
36.11.2 Qual modelo alcança estabilidade mais rapidamente?
Regressão logística é o mais estável e menos data hungry.338
Árvore de decisão para classificação e regressão estabiliza rápido, mas em nível de desempenho baixo.338
Máquina de vetores de suporte, redes neurais e random forests apresentam instabilidade mesmo em amostras muito grandes.338
36.13 Avaliação de modelos
36.13.1 Como avaliar a qualidade de ajuste de um modelo?
- Coeficiente de determinação (\(R^2\)) (36.1) e \(R^2\) ajustado (36.2): Medem a proporção da variabilidade dos dados explicada pelo modelo. O \(R^2\) ajustado penaliza a inclusão de variáveis irrelevantes.REF?
\[\begin{equation} \tag{36.1} R^2 = 1 - \frac{SS_{res}}{SS_{tot}} \end{equation}\]
\[\begin{equation} \tag{36.2} R^2_{ajustado} = 1 - (1 - R^2)\frac{n - 1}{n - p - 1} \end{equation}\]
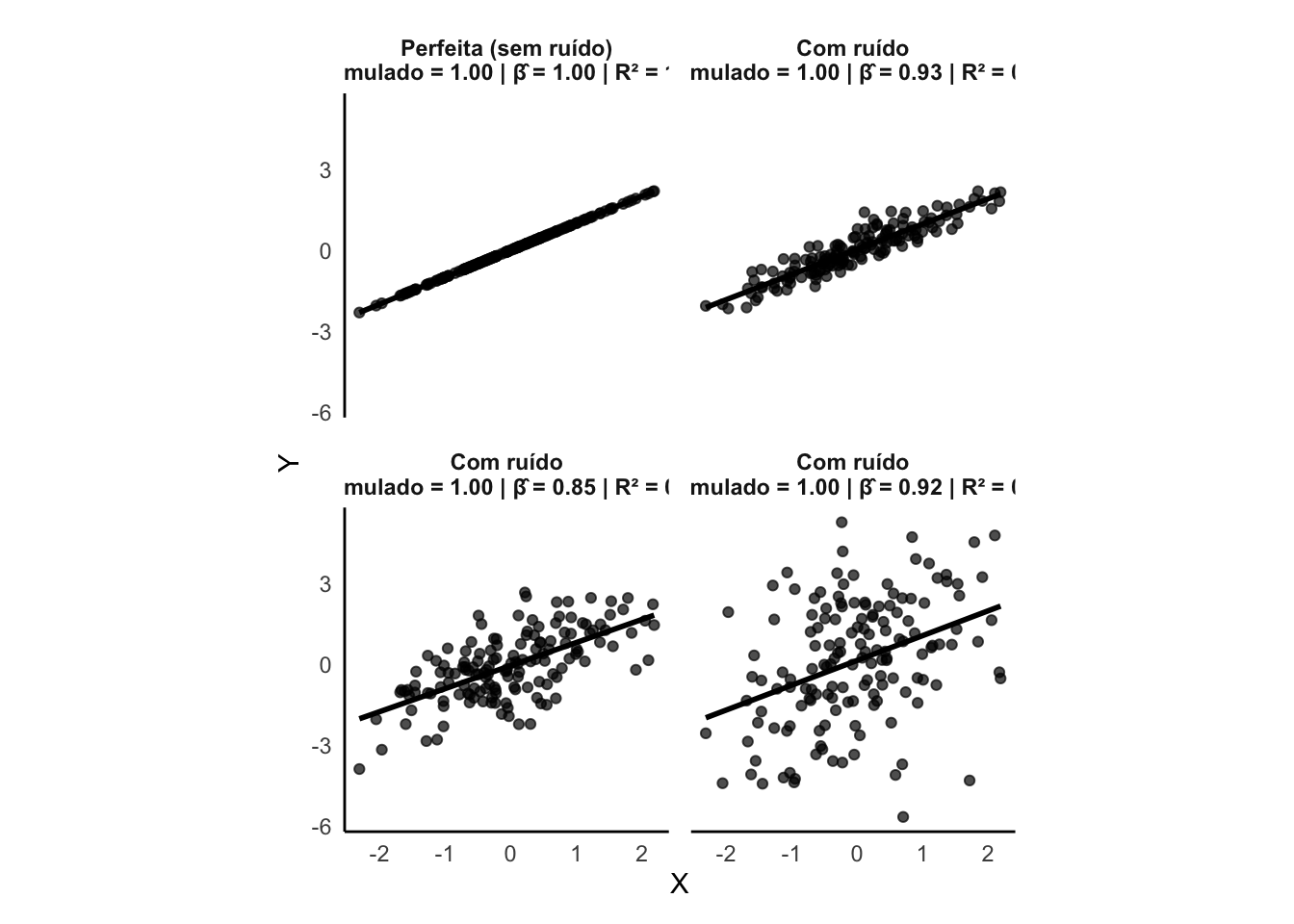
Figura 36.6: Exemplos de ajuste de modelos de regressão linear simples (\(y \sim x\)) com diferentes níveis de ruído (\(R^2\)). Cada painel mostra a reta ajustada (cinza) e os valores observados (pontos). Os valores anotados indicam o coeficiente angular simulado (\(\beta\)), o coeficiente angular estimado (\(\hat{\beta}\)) e o \(R^2\) observado.
- Erro quadrático médio (\(RMSE\)) (36.3): Mede a média dos erros ao quadrado entre os valores observados e os valores previstos pelo modelo, onde \(y_i\) são os valores observados, \(\hat{y}_i\) são os valores previstos pelo modelo, e \(n\) é o número de observações. Valores menores indicam melhor ajuste.REF?
\[\begin{equation} \tag{36.3} RMSE = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2} \end{equation}\]
- Critério de Informação Akaike (\(AIC\)) (36.4) e Critério de Informação Bayesiano (\(BIC\)) (36.5): Avaliam o ajuste do modelo penalizando a complexidade (número de parâmetros), onde \(k\) é o número de parâmetros do modelo, \(L\) é a verossimilhança máxima do modelo, e \(n\) é o tamanho da amostra. Modelos com menor AIC ou BIC são preferíveis.REF?
\[\begin{equation} \tag{36.4} AIC = 2k - 2\ln(L) \end{equation}\]
\[\begin{equation} \tag{36.5} BIC = \ln(n)k - 2\ln(L) \end{equation}\]
- Desvio residual (\(\sigma\)): Mede a variabilidade dos resíduos do modelo. Valores menores indicam melhor ajuste.REF?
| Métrica | Valor |
|---|---|
| AIC | 513.017 |
| AIC corrigido | 513.267 |
| BIC | 520.833 |
| \(R^2\) | 0.007 |
| \(R^2\) ajustado | -0.003 |
| Erro quadrático médio (RMSE) | 3.053 |
| Desvio residual (sigma) | 3.084 |
O pacote performance267 fornece a função model_performance para calcular as métricas de ajuste da regressão adequadas ao modelo pré-especificado.
O pacote performance267 fornece a função compare_performance para comparar o desempenho e a qualidade do ajuste de diversos modelos de regressão pré-especificados.
36.15 Calibração de modelos
36.15.1 Como calibrar modelos estatísticos?
- .REF?
Ferreira, Arthur de Sá. Ciência com R: Perguntas e respostas para pesquisadores e analistas de dados. Rio de Janeiro: 1a edição,