Capítulo 12 Distribuições e parâmetros
12.1 Distribuições de probabilidade
12.1.1 O que são distribuições de probabilidade?
- Uma distribuição de probabilidade é uma função que descreve os valores possíveis ou o intervalo de valores de uma variável (eixo horizontal) e a frequência com que cada valor é observado (eixo vertical).49
12.1.2 Como representar distribuições de probabilidade?
Tabelas de frequência, polígonos de frequência, gráficos de barras, histogramas e boxplots são formas de representar distribuições de probabilidade.100
Tabelas de frequência mostram as categorias de medição e o número de observações em cada uma. É necessário conhecer o intervalo de valores (mínimo e máximo), que é dividido em intervalos arbitrários chamados “intervalos de classe”.100
Se houver muitos intervalos, não haverá redução significativa na quantidade de dados, e pequenas variações serão perceptíveis. Se houver poucos intervalos, a forma da distribuição não poderá ser adequadamente determinada.100
A quantidade de intervalos pode ser determinada pelo método de Sturges, que é dado pela fórmula \(k = 1 + 3.322 \times \log_{10}(n)\), onde \(k\) é o número de intervalos e \(n\) é o número de observações.101
A quantidade de intervalos pode ser determinada pelo método de Scott, que é dado pela fórmula \(h = 3.5 \times \text{sd}(x) \times n^{-1/3}\), onde \(h\) é a largura do intervalo, \(\text{sd}(x)\) é o desvio padrão e \(n\) é o número de observações.102
A quantidade de intervalos pode ser determinada pelo método de Freedman-Diaconis, que é dado pela fórmula \(h = 2 \times \text{IQR}(x) \times n^{-1/3}\), onde \(h\) é a largura do intervalo, \(\text{IQR}(x)\) é o intervalo interquartil e \(n\) é o número de observações.103
A largura das classes pode ser determinada dividindo o intervalo total de observações pelo número de classes. Recomenda-se larguras iguais, mas larguras desiguais podem ser usadas quando existirem grandes lacunas nos dados ou em contextos específicos. Os intervalos devem ser mutuamente exclusivos e não sobrepostos, evitando intervalos abertos (ex.: <5, >10).100
Polígonos de frequência são gráficos de linhas que conectam os pontos médios de cada barra do histograma. Eles são úteis para comparar duas ou mais distribuições de frequência.100
Gráficos de barra verticais ou horizontais representam a distribuição de frequências de uma variável categórica. A altura de cada barra é proporcional à frequência da classe. A largura da barra é igual à largura da classe. A área de cada barra é proporcional à frequência da classe. A área total do gráfico de barras é igual ao número total de observações.100
Histogramas representam a distribuição de frequências de uma variável contínua. A altura de cada barra é proporcional à frequência da classe. A largura da barra é igual à largura da classe. A área de cada barra é proporcional à frequência da classe. A área total do histograma é igual ao número total de observações.100
Boxplots representam a distribuição de frequências de uma variável contínua. A linha central divide os dados em duas partes iguais (mediana ou Q2). A caixa inferior representa o primeiro quartil (Q1) e a caixa superior representa o terceiro quartil (Q3). A linha inferior é o mínimo e a linha superior é o máximo. Os valores atípicos são representados por pontos individuais.100
O pacote grDevices104 fornece a função nclass para determinar a quantidade de classes de um histograma com os métodos de Sturge101, Scott102 ou Freedman-Diaconis103.
12.1.3 Quais características definem uma distribuição?
- Uma distribuição pode ser definida por modelos matemáticos e caracterizada por parâmetros de tendência central, dispersão, simetria e curtose.
12.1.4 Quais são as distribuições mais comuns?
Distribuções discretas:
Uniforme: resultados (finitos) que são igualmente prováveis.REF?
Binomial: número de sucessos em k tentativas.REF?
Poisson: número de eventos em um intervalo de tempo fixo.REF?
Bernoulli: .REF?
Geométrica: número de testes até o 1o sucesso.REF?
Binomial negativa: número de testes até o k-ésimo sucesso.REF?
Hipergeométrica: número de indivíduos na amostra tomados sem reposição.REF?
Distribuições contínuas:
Uniforme: resultados que possuem a mesma densidade.REF?
Exponencial: tempo entre eventos.REF?
Normal: .REF?
Normal padrão: .REF?
Aproximação binomial: número de sucessos em uma grande quantidade de tentativas.REF?
Aproximação Poisson: número de ocorrências em um intervalo de tempo fixo.REF?
Qui-quadrado: .REF?
t-Student: .REF?
Weibull: .REF?
Log-normal: .REF?
Beta: .REF?
Gama: .REF?
Logística: .REF?
Pareto.REF?
12.1.5 Quais são as funções de uma distribuição?
Função de massa de probabilidade (probability mass function, pmf).REF?
Função de distribuição cumulativa (cumulative distribution function, cdf).REF?
Função quantílicas (quantile function, qf).REF?
Função geradora de números aleatórios (random function, rf).REF?
O pacote stats44 fornece funções de distribuição de probabilidade (p), funções de densidade (d), funções quantílicas (q) e funções geradores de números aleatórios (r) para as distribuições normal, Student t, binomial, qui-quadrado, uniforme, dentre outras.
O pacote ggdist106 fornece a função geom_slabinterval para criar gráficos de distribuição de probabilidade (p) e funções de densidade (d) as distribuições.
O pacote ggfortify107 fornece a função ggdistribution para criar gráficos de distribuição de probabilidade (p), funções de densidade (d), funções quantílicas (q) e funções geradores de números aleatórios (r) para as distribuições.
12.1.6 O que é a distribuição normal?
A distribuição normal (ou gaussiana) é uma distribuição com desvios simétricos positivos e negativos em torno de um valor central.79
Em uma distribuição normal, o intervalo de 1 desvio-padrão (±1DP) inclui cerca de 68% dos dados; de 2 desvios-padrão (±2DP) cerca de 95% dos dados; e no intervalo de 3 desvios-padrão (±3DP) cerca de 99% dos dados.79
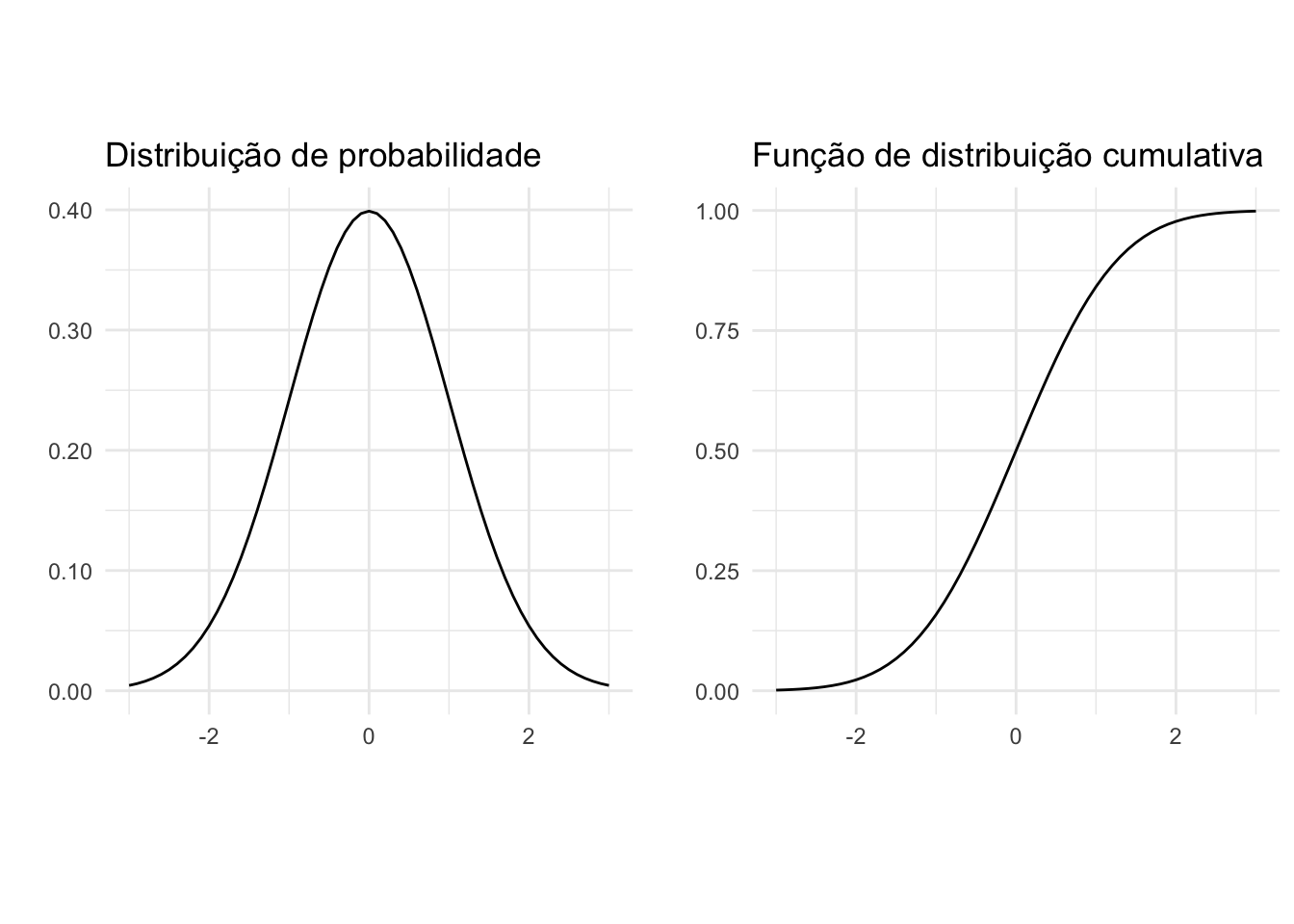
Figura 12.1: Distribuições e funções de probabilidade
12.2 Parâmetros
12.2.1 O que são parâmetros?
Parâmetros são informações que definem um modelo teórico, como propriedades de uma coleção de indivíduos.78
Parâmetros definem características de uma população inteira, tipicamente não observados por ser inviável ter acesso a todos os indivíduos que constituem tal população.49
12.2.2 O que é uma análise paramétrica?
Testes paramétricos possuem suposições sobre as características e/ou parâmetros da distribuição dos dados na população.49
Testes paramétricos assumem que: a variável é quantitativa numérica (contínua); os dados foram amostrados de uma população com distribuição normal; a variância da(S) amostra(s) é igual à da população; as amostras foram selecionadas de modo aleatório na população; os valores de cada amostra são independentes entre si.49,79
Testes paramétricos são baseados na suposição de que os dados amostrais provêm de uma população com parâmetros fixos determinando sua distribuição de probabilidade.8
12.2.3 O que é uma análise não paramétrica?
Testes não-paramétricos fazem poucas suposições, ou menos rigorosas, sobre as características e/ou parâmetros da distribuição dos dados na população.49,79
Testes não-paramétricos são úteis quando as suposições de normalidade não podem ser sustentadas.79
12.2.4 Devemos testar as suposições de normalidade?
- Testes preliminares de normalidade não são necessários para a maioria dos testes paramétricos de comparação, pois eles são robustos contra desvios moderados da normalidade. Normalidade da distribuição deve ser estabelecida para a população.108
12.2.5 Por que as análises paramétricas são preferidas?
Em geral, testes paramétricos são mais robustos (isto é, possuem menores erros tipo I e II) que seus testes não-paramétricos correspondentes.49,109
Testes não-paramétricos apresentam menor poder estatístico (maior erro tipo II) comparados aos testes paramétricos correspondentes.79
12.3 Tendência central
12.3.1 Que parâmetros de tendência central podem ser estimados?
Média: aritmética, ponderada, geométrica ou harmônica.79,110,113
A posição relativa das medidas de tendência central (média, mediana e moda) depende da forma da distribuição.114
Em uma distribuição normal, as três medidas são idênticas.114
A média é sempre puxada para os valores extremos, por isso é deslocada para a cauda em distribuições assimétricas.114
A mediana fica entre a média e a moda em distribuições assimétricas.114
A moda é o valor mais frequente e, portanto, se localiza no pico da distribuição assimétrica.114
12.3.2 Como escolher o parâmetro de tendência central?
A mediana é preferida à média quando existem poucos valores extremos na distribuição, alguns valores são indeterminados, ou há uma distribuição aberta, ou os dados são medidos em uma escala ordinal.114
A moda é preferida quando os dados são medidos em uma escala nominal.114
A média geométrica é preferida quando os dados são medidos em uma escala logarítmica.114
12.4 Dispersão
12.4.1 Que parâmetros de dispersão podem ser estimados?
Desvio-padrão: Informam sobre a dispersão da população e são, portanto, úteis como preditores da variação em novas amostras.111,115,116
Erro-padrão: Refletem a incerteza na média e sua dependência do tamanho da amostra.111,115
Intervalo de confiança: Captura a média populacional correspondente ao nível de significância \(\alpha\) pré-estabelecido.79,110,115,117
O pacote stats44 fornece a função confint para calcular o intervalo de confiança em um nível de significância \(\alpha\).
12.5 Proporção
12.5.1 Que parâmetros de proporção podem ser estimados?
Quantil: é o ponto de corte que define a divisão da amostra em grupos de tamanhos iguais. Portanto, não se referem aos grupos em si, mas aos valores que os dividem:112
Tercil: 2 valores que dividem a amostra em 3 grupos de tamanhos iguais.112
Quartil: 3 valores que dividem a amostra em 4 grupos de tamanhos iguais.112
Quintil: 4 valores que dividem a amostra em 5 grupos de tamanhos iguais.112
Decil: 9 valores que dividem a amostra em 10 grupos de tamanhos iguais.112
12.7 Extremos
12.7.1 O que são extremos?
- Valores extremos podem constituir valores legítimos ou ilegítimos de uma distribuição.118
12.8 Valores discrepantes
12.8.1 O que são valores discrepantes (outliers)?
Em termos gerais, um valor discrepante - “fora da curva” ou outlier - é uma observação que possui um valor relativamente grande ou pequeno em comparação com a maioria das observações.119
Um valor discrepante é uma observação incomum que exerce influência indevida em uma análise.119
Valores discrepantes são dados com valores altos de resíduos.118
12.8.2 Quais são os tipos de valores discrepantes?
Valores discrepantes podem ser categorizados em três subtipos: outliers de erro, outliers interessantes e outliers aleatórios.118
Os valores discrepantes de erro são observações claramente não legítimas, distantes de outros dados devido a imprecisões por erro de mensuração e/ou codificação.118
Os valores discrepantes interessantes não são claramente erros, mas podem refletir um processo/mecanismo potencialmente interessante para futuras pesquisas.118
Os valores discrepantes aleatórios são observações que resultam por acaso, sem qualquer padrão ou tendência conhecida.118
Valores discrepantes podem ser univariados ou multivariados.118
12.8.3 Por que é importante avaliar valores discrepantes?
Excluir o valor discrepante implica em reduzir inadequadamente a variância, ao remover um valor que de fato pertence à distribuição considerada.118
Manter os dados inalterados (mantendo o valor discrepante) implica em aumentar inadequadamente a variância, pois a observação não pertence à distribuição que fundamenta o experimento.118
Em ambos os casos, uma decisão errada pode influenciar o erro do tipo I (\(\alpha\) — rejeitar uma hipótese verdadeira) ou o erro do tipo II (\(\beta\) — não rejeitar uma hipótese falsa).118
12.8.4 Como detectar valores discrepantes?
Na maioria das vezes, não há como saber de qual distribuição uma observação provém. Por isso, não é possível ter certeza se um valor é legítimo ou não dentro do contexto do experimento.118
Recomenda-se seguir um procedimento em duas etapas: detectar possíveis candidatos a outliers usando ferramentas quantitativas; e gerenciar os outliers, decidindo manter, remover ou recodificar os valores, com base em informações qualitativas.118
A detecção de outliers deve ser aplicada apenas uma vez no conjunto de dados; um erro comum é identificar e tratar os outliers (como remover ou recodificar) e, em seguida, reaplicar o procedimento no conjunto de dados já modificado.118
A detecção ou o tratamento dos outliers não deve ser realizada após a análise dos resultados, pois isso introduz viés nos resultados.118
12.8.5 Quais são os métodos para detectar valores discrepantes?
Valores univariados são comumente considerados outliers quando são mais extremos do que a média ± (desvio padrão × constante), podenso essa constante ser 3 (99,7% das observações estão dentro de 3 desvios-padrão da média) ou 3,29 (99,9% estão dentro de 3,29 desvios-padrão).118
Para detectar outliers univariados, recomenda-se o uso da Mediana da Desviação Absoluta (Median Absolute Deviation, MAD), calculado a partir de um intervalo em torno da mediana, multiplicado por uma constante (valor padrão: 1,4826).118,120
Para detectar outliers multivariados, comumente utiliza-se a distância de Mahalanobis, que identifica valores muito distantes do centróide formado pela maioria dos dados (por exemplo, 99%).118
Para detectar outliers multivariados, recomenda-se o Determinante de Mínima Covariância (Minimum Covariance Determinant, MCD), pois possui o maior ponto de quebra possível e utiliza a mediana, que é o indicador mais robusto em presença de outliers.118,121
12.8.6 Como manejar os valores discrepantes?
Manter outliers pode ser uma boa decisão se a maioria desses valores realmente pertence à distribuição de interesse. Manter outliers que pertencem a uma distribuição alternativa pode ser problemático, pois um teste pode se tornar significativo apenas por causa de um ou poucos outliers.118
Remover outliers pode ser eficaz quando eles distorcem a estimativa dos parâmetros da distribuição. Remover outliers que pertencem legitimamente à distribuição pode reduzir artificialmente a estimativa do erro.118
Remover outliers leva à perda de observações, especialmente em conjuntos de dados com muitas variáveis, quando outliers univariados são excluídos em cada variável.118
Recodificar outliers evita a perda de uma grande quantidade de dados, mas deve ser baseada em argumentos razoáveis e convincentes.118
Erros de observação e de medição são uma justificativa válida para descartar observações discrepantes.119
12.8.7 Como conduzir análises com valores discrepantes?
É importante reportar se existem valores discrepantes e como foram tratados.119
Valores discrepantes na variável de desfecho podem exigir uma abordagem mais refinada, especialmente quando representam uma variação real na variável que está sendo medida.119
Valores discrepantes em uma (co)variável podem surgir devido a um projeto experimental inadequado; nesse caso, abandonar a observação ou transformar a covariável são opções adequadas.119
Valores discrepantes podem ser recodificados usando a Winsorização,122 que transforma os outliers em valores de percentis específicos (como o 5º e o 95º).118
O pacote outliers123 fornece a função rm.outlier para remover os valores mais distantes da média detectados por testes de hipótese e/ou substitui-los pela média ou mediana.